Entropy Ratio Clipping as a Soft Global Constraint for Stable Reinforcement Learning
作者: Zhenpeng Su, Leiyu Pan, Minxuan Lv, Tiehua Mei, Zijia Lin, Yuntao Li, Wenping Hu, Ruiming Tang, Kun Gai, Guorui Zhou
分类: cs.LG, cs.CL
发布日期: 2025-12-05
💡 一句话要点
提出熵率裁剪(ERC)机制,稳定强化学习训练,提升大语言模型后训练效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 语言模型 后训练 分布偏移 熵率裁剪
📋 核心要点
- 离策略强化学习训练中,分布偏移导致策略超出信任区域,引起训练不稳定,具体表现为策略熵波动和梯度不稳定。
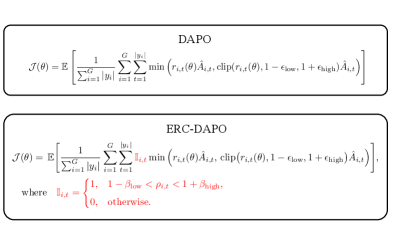
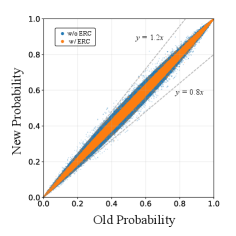
- 论文提出熵率裁剪(ERC)机制,通过对当前和先前策略的熵率施加双向约束,稳定全局分布层面的策略更新。
- ERC被集成到DAPO和GPPO算法中,并在多个基准测试中验证了其性能提升,证明了其有效性。
📝 摘要(中文)
大型语言模型的后训练依赖于强化学习来提升模型能力和对齐质量。然而,离策略训练范式引入了分布偏移,这通常会将策略推离信任区域,导致训练不稳定,表现为策略熵的波动和不稳定的梯度。尽管PPO-Clip通过重要性裁剪缓解了这个问题,但它仍然忽略了动作的全局分布偏移。为了解决这些挑战,我们提出使用当前策略和先前策略之间的熵率作为一个新的全局指标,有效地量化策略探索在更新过程中的相对变化。基于此指标,我们引入了一种 extbf{熵率裁剪}(ERC)机制,该机制对熵率施加双向约束。这在全局分布层面上稳定了策略更新,并弥补了PPO-clip无法调节未采样动作的概率偏移的不足。我们将ERC集成到DAPO和GPPO强化学习算法中。跨多个基准的实验表明,ERC始终能够提高性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型后训练中,使用离策略强化学习时出现的训练不稳定问题。现有方法如PPO-Clip虽然通过重要性采样进行裁剪,但忽略了动作的全局分布偏移,导致策略更新超出信任区域,出现策略熵波动和梯度不稳定等问题。
核心思路:论文的核心思路是利用当前策略和先前策略之间的熵率来量化策略探索的相对变化,并以此作为全局约束,稳定策略更新。通过对熵率进行裁剪,限制策略的剧烈变化,从而缓解分布偏移带来的问题。
技术框架:论文提出的ERC机制可以集成到现有的强化学习算法中,例如DAPO和GPPO。整体流程如下:首先,计算当前策略和先前策略的熵率;然后,使用ERC机制对熵率进行裁剪,得到裁剪后的熵率;最后,将裁剪后的熵率用于更新策略。
关键创新:论文的关键创新在于提出了熵率裁剪(ERC)机制,它是一种全局约束,能够有效地稳定策略更新,并弥补了PPO-clip无法调节未采样动作的概率偏移的不足。ERC通过直接约束策略的全局分布变化,从而更有效地控制策略更新的幅度。
关键设计:ERC机制的关键在于如何选择合适的熵率裁剪范围。论文中可能涉及对裁剪阈值的选择策略,以及如何将其融入到现有的损失函数中,以实现策略的稳定更新。具体实现细节(如损失函数形式、网络结构等)需要参考原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,将ERC集成到DAPO和GPPO算法中后,在多个基准测试中均能显著提高性能。这证明了ERC机制能够有效地稳定策略更新,并提升强化学习算法的训练效果。具体的性能提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于大型语言模型的后训练,提升模型的能力和对齐质量。通过稳定强化学习训练过程,可以更有效地利用强化学习来优化语言模型,使其更好地服务于各种下游任务,例如对话生成、文本摘要、代码生成等。此外,该方法也可以推广到其他需要稳定强化学习训练的领域,例如机器人控制、游戏AI等。
📄 摘要(原文)
Large language model post-training relies on reinforcement learning to improve model capability and alignment quality. However, the off-policy training paradigm introduces distribution shift, which often pushes the policy beyond the trust region, leading to training instabilities manifested as fluctuations in policy entropy and unstable gradients. Although PPO-Clip mitigates this issue through importance clipping, it still overlooks the global distributional shift of actions. To address these challenges, we propose using the entropy ratio between the current and previous policies as a new global metric that effectively quantifies the relative change in policy exploration throughout updates. Building on this metric, we introduce an \textbf{Entropy Ratio Clipping} (ERC) mechanism that imposes bidirectional constraints on the entropy ratio. This stabilizes policy updates at the global distribution level and compensates for the inability of PPO-clip to regulate probability shifts of un-sampled actions. We integrate ERC into both DAPO and GPPO reinforcement learning algorithms. Experiments across multiple benchmarks show that ERC consistently improves performance.