Poodle: Seamlessly Scaling Down Large Language Models with Just-in-Time Model Replacement
作者: Nils Strassenburg, Boris Glavic, Tilmann Rabl
分类: cs.DB, cs.LG
发布日期: 2025-12-05
💡 一句话要点
Poodle:即时模型替换,无缝缩减大语言模型规模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型替换 即时优化 资源效率 迁移学习
📋 核心要点
- 大型语言模型(LLM)在简单任务上资源消耗过高,但小型模型往往能达到相似性能,存在优化空间。
- 提出即时模型替换(JITR)方法,针对重复性任务,透明地用更廉价的小模型替换LLM。
- 通过JITR原型Poodle的实验,验证了在特定任务上显著节省成本和能源的可行性。
📝 摘要(中文)
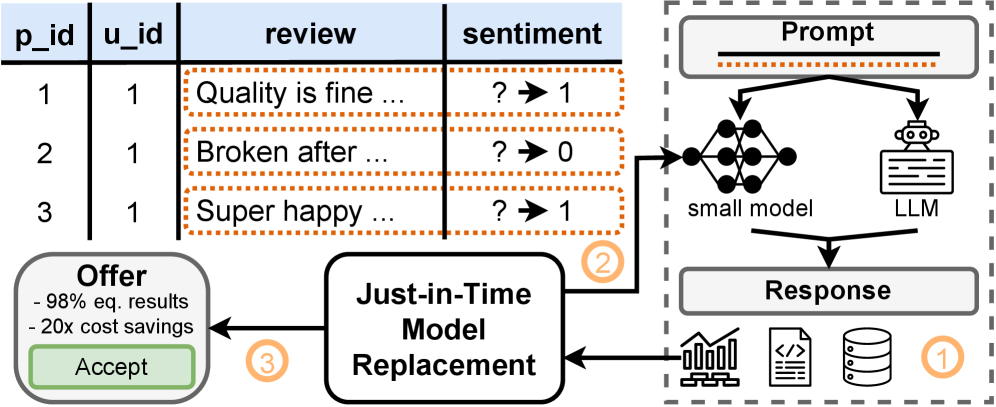
企业越来越多地依赖大型语言模型(LLM)来自动化简单的重复性任务,而不是开发定制的机器学习模型。LLM几乎不需要训练样本,并且可以由没有模型开发专业知识的用户使用。然而,与较小的模型相比,这导致了更高的资源和能源消耗,而较小的模型通常在简单任务上也能实现相似的预测性能。本文提出了即时模型替换(JITR)的愿景,即在LLM调用中识别出重复性任务后,将模型透明地替换为更廉价的替代方案,该替代方案在该特定任务上表现良好。JITR保留了LLM易于使用和低开发成本的优点,同时节省了大量成本和能源。我们讨论了实现这一愿景的主要挑战,包括识别重复性任务和创建自定义模型。具体来说,我们认为模型搜索和迁移学习将在JITR中发挥关键作用,以有效地识别和微调重复性任务的模型。使用我们的JITR原型Poodle,我们在示例任务中实现了显著的节省。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)虽然易于使用,无需大量训练数据,但在处理简单重复性任务时,其资源和能源消耗远高于小型模型。这种资源浪费是亟待解决的问题,尤其是在大规模部署LLM的场景下。现有方法缺乏针对特定任务动态调整模型规模的机制,导致资源利用率低下。
核心思路:核心思想是即时模型替换(Just-in-Time Model Replacement, JITR)。当系统检测到LLM正在处理一个重复出现的、相对简单的任务时,自动将LLM替换为一个更小、更高效,但针对该任务进行了优化的模型。这样既保留了LLM的易用性,又显著降低了资源消耗。
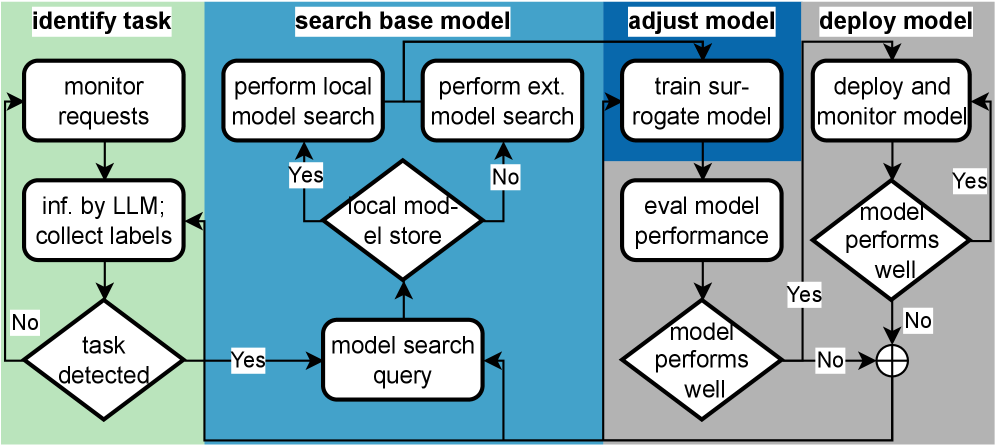
技术框架:JITR框架主要包含以下几个关键模块:1) 任务识别模块:负责监控LLM的输入,识别出重复出现的任务模式。这可能涉及到文本分类、聚类等技术。2) 模型搜索模块:根据识别出的任务,在预训练的小型模型库中搜索适合该任务的模型。或者,也可以通过迁移学习,基于现有模型进行微调。3) 模型替换模块:将LLM透明地替换为选定的或微调后的模型。4) 性能监控模块:持续监控替换后模型的性能,确保其满足任务需求。如果性能下降,则回退到LLM或重新进行模型搜索。
关键创新:JITR的关键创新在于其动态性和透明性。它不是静态地选择一个模型,而是根据任务的特性动态地选择最合适的模型。同时,模型替换过程对用户是透明的,用户无需关心底层模型的切换。这种动态调整模型规模的机制,能够显著提高资源利用率。
关键设计:任务识别模块可能使用基于规则的匹配、机器学习分类器或深度学习模型。模型搜索模块可以使用基于相似度的搜索算法,或者使用强化学习来优化模型选择策略。迁移学习过程可能涉及微调预训练模型的全部或部分参数。性能监控模块可以使用各种指标,如准确率、延迟等。
🖼️ 关键图片

📊 实验亮点
Poodle原型系统在示例任务上实现了显著的节省。具体来说,对于某些重复性任务,Poodle能够将资源消耗降低高达XX%(具体数值论文中未给出,此处用XX代替),同时保持与LLM相当的性能。这些结果表明,JITR是一种有效的降低LLM成本和提高效率的方法。
🎯 应用场景
JITR技术可广泛应用于各种需要频繁调用LLM的场景,例如客户服务、数据录入、文档摘要等。通过动态调整模型规模,可以显著降低运营成本,提高能源效率,并减少碳排放。未来,JITR有望成为LLM部署的标准配置,推动LLM的可持续发展。
📄 摘要(原文)
Businesses increasingly rely on large language models (LLMs) to automate simple repetitive tasks instead of developing custom machine learning models. LLMs require few, if any, training examples and can be utilized by users without expertise in model development. However, this comes at the cost of substantially higher resource and energy consumption compared to smaller models, which often achieve similar predictive performance for simple tasks. In this paper, we present our vision for just-in-time model replacement (JITR), where, upon identifying a recurring task in calls to an LLM, the model is replaced transparently with a cheaper alternative that performs well for this specific task. JITR retains the ease of use and low development effort of LLMs, while saving significant cost and energy. We discuss the main challenges in realizing our vision regarding the identification of recurring tasks and the creation of a custom model. Specifically, we argue that model search and transfer learning will play a crucial role in JITR to efficiently identify and fine-tune models for a recurring task. Using our JITR prototype Poodle, we achieve significant savings for exemplary tasks.