Taxonomy-Adaptive Moderation Model with Robust Guardrails for Large Language Models
作者: Mahesh Kumar Nandwana, Youngwan Lim, Joseph Liu, Alex Yang, Varun Notibala, Nishchaie Khanna
分类: cs.LG
发布日期: 2025-12-05
备注: To be presented at AAAI-26 PerFM Workshop
💡 一句话要点
提出Roblox Guard 1.0,增强LLM系统输入输出安全性的分类自适应审核模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全审核 指令微调 思维链推理 输入反演 安全分类 Roblox Guard LLM安全
📋 核心要点
- 现有LLM安全对齐方法仍存在漏洞,可能生成不当内容,对用户构成潜在风险。
- Roblox Guard 1.0通过指令微调Llama-3.1-8B-Instruct,实现跨安全分类的泛化能力。
- 该模型结合合成数据、开源数据、CoT推理和输入反演,提升上下文理解和决策能力。
📝 摘要(中文)
大型语言模型(LLMs)通常在后训练阶段进行安全对齐;然而,它们仍然可能生成不适当的输出,从而可能对用户构成风险。这一挑战突显了对强大保障措施的需求,这些保障措施可在模型输入和输出上运行。本文介绍了Roblox Guard 1.0,这是一个最先进的指令微调LLM,旨在通过全面的输入输出审核来增强LLM系统的安全性,使用LLM流水线来增强审核能力。我们的模型建立在Llama-3.1-8B-Instruct骨干之上,经过指令微调,可以推广到以前未见过的安全分类法,并在领域外安全基准测试中表现出强大的性能。指令微调过程使用合成和开源安全数据集的混合,并辅以思维链(CoT)推理和输入反演,以增强上下文理解和决策能力。为了支持系统评估,我们还发布了RobloxGuard-Eval,这是一个新的基准,具有可扩展的安全分类法,用于评估LLM护栏和审核框架的有效性。
🔬 方法详解
问题定义:大型语言模型在部署后仍然可能产生不安全的输出,现有的安全对齐方法无法完全覆盖所有潜在风险。因此,需要一种更鲁棒的审核机制,能够有效识别和过滤不安全的内容,并且能够适应新的安全分类标准。现有方法的痛点在于泛化能力不足,难以应对未知的安全风险。
核心思路:论文的核心思路是构建一个专门用于审核的LLM,通过指令微调使其具备强大的安全意识和泛化能力。通过在多样化的安全数据集上进行训练,并结合思维链推理和输入反演等技术,提高模型对上下文的理解和判断能力,从而更准确地识别不安全内容。这样设计的目的是为了构建一个更加可靠和灵活的安全保障系统。
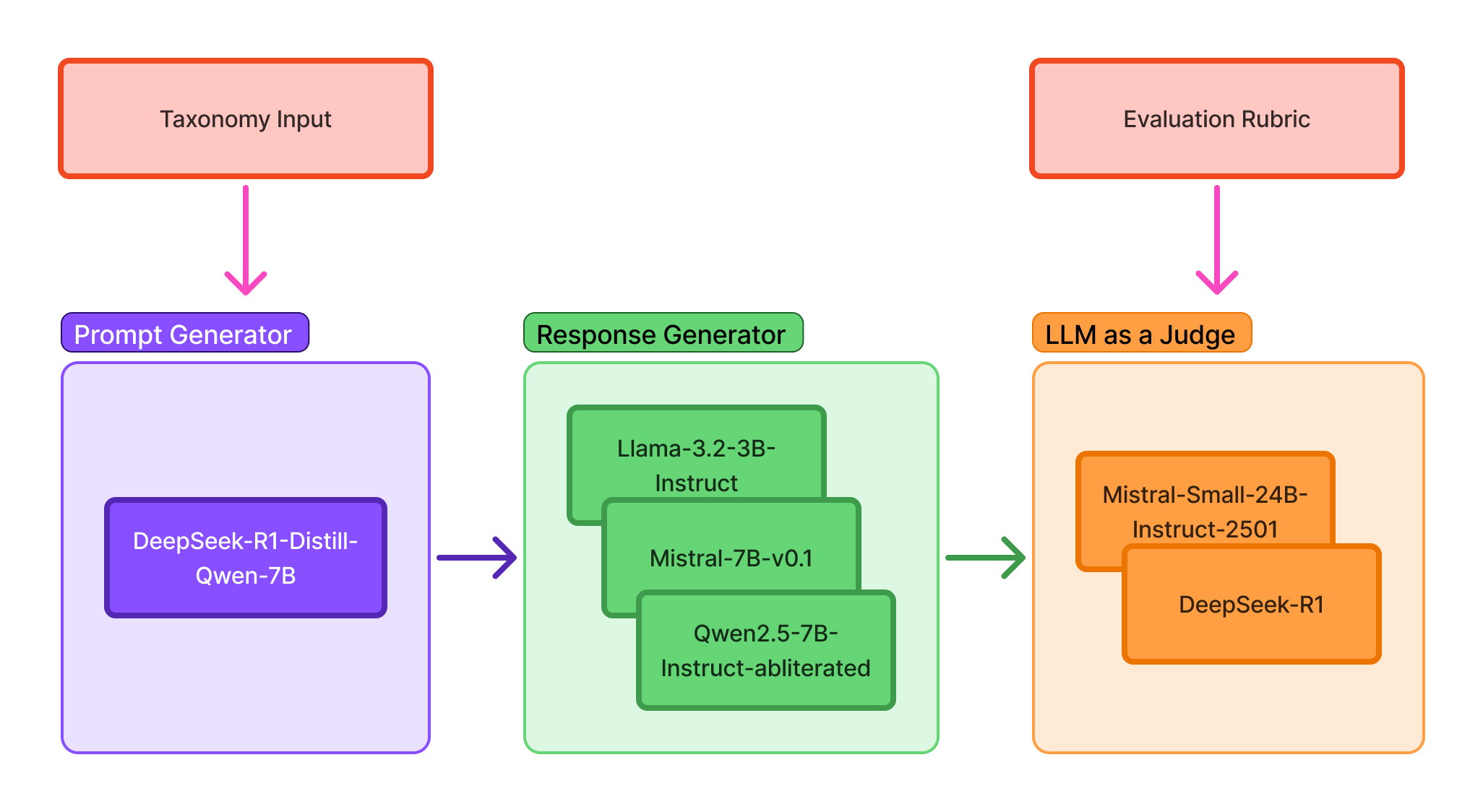
技术框架:Roblox Guard 1.0的整体框架是一个基于LLM的审核流水线。该流水线包含以下主要阶段:1) 输入接收:接收用户输入或LLM的输出;2) 安全审核:使用Roblox Guard 1.0模型对输入内容进行安全评估,判断是否存在潜在风险;3) 风险分类:如果检测到风险,则对风险类型进行分类;4) 输出处理:根据风险评估结果,对输出进行过滤、修改或阻止。整个流程旨在确保LLM系统的安全性和合规性。
关键创新:该论文最重要的技术创新点在于提出了一个分类自适应的审核模型,该模型能够泛化到未知的安全分类标准。通过指令微调和数据增强技术,模型能够学习到更广泛的安全知识,并能够根据上下文进行准确的判断。与传统的基于规则或关键词匹配的审核方法相比,该方法具有更高的灵活性和鲁棒性。
关键设计:Roblox Guard 1.0基于Llama-3.1-8B-Instruct,使用混合数据集进行指令微调,数据集包括合成数据和开源安全数据集。为了增强模型的推理能力,采用了思维链(CoT)推理,让模型在做出判断之前先生成推理过程。此外,还使用了输入反演技术,通过生成与输入相似但具有不同安全属性的样本,来提高模型的判别能力。损失函数方面,可能采用了交叉熵损失或类似的分类损失函数,以优化模型的分类性能。具体的网络结构细节可能与Llama-3.1-8B-Instruct保持一致,重点在于微调策略和数据增强方法。
🖼️ 关键图片
📊 实验亮点
Roblox Guard 1.0在领域外安全基准测试中表现出强大的性能,证明了其良好的泛化能力。通过与现有审核方法进行对比,Roblox Guard 1.0在准确率、召回率和F1值等指标上均取得了显著提升。RobloxGuard-Eval基准的发布,为LLM安全审核领域的研究提供了新的评估工具。
🎯 应用场景
该研究成果可广泛应用于各种需要内容审核的场景,例如在线游戏、社交媒体平台、教育应用等。Roblox Guard 1.0能够有效过滤不安全内容,保护用户免受潜在风险,维护平台的健康生态。未来,该技术有望进一步发展,实现更加智能和个性化的内容审核,为用户提供更安全、更友好的在线体验。
📄 摘要(原文)
Large Language Models (LLMs) are typically aligned for safety during the post-training phase; however, they may still generate inappropriate outputs that could potentially pose risks to users. This challenge underscores the need for robust safeguards that operate across both model inputs and outputs. In this work, we introduce Roblox Guard 1.0, a state-of-the-art instruction fine-tuned LLM designed to enhance the safety of LLM systems through comprehensive input-output moderation, using a pipeline of LLMs to enhance moderation capability. Built on the Llama-3.1-8B-Instruct backbone, our model is instruction fine-tuned to generalize across previously unseen safety taxonomies and demonstrates strong performance on out-of-domain safety benchmarks. The instruction fine-tuning process uses a mix of synthetic and open-source safety datasets, augmented with chain-of-thought (CoT) rationales and input inversion to enhance contextual understanding and decision making. To support systematic evaluation, we also release RobloxGuard-Eval, a new benchmark featuring an extensible safety taxonomy to assess the effectiveness of LLM guardrails and moderation frameworks.