SHAP-Guided Kernel Actor-Critic for Explainable Reinforcement Learning
作者: Na Li, Hangguan Shan, Wei Ni, Wenjie Zhang, Xinyu Li
分类: cs.LG
发布日期: 2025-12-04 (更新: 2026-01-29)
💡 一句话要点
提出基于SHAP引导的核Actor-Critic算法,提升强化学习的可解释性与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 可解释性 Actor-Critic SHAP 再生核希尔伯特空间 状态属性 连续控制
📋 核心要点
- 现有可解释强化学习方法忽略了不同状态特征对奖励的异构影响,将所有特征同等对待。
- RSA2C算法利用RKHS-SHAP计算状态属性,并将其转化为权重,用于调节Actor梯度和Advantage Critic目标。
- 实验结果表明,RSA2C在连续控制环境中实现了效率、稳定性和可解释性的提升。
📝 摘要(中文)
本文提出了一种基于属性感知的核化双时间尺度Actor-Critic算法,称为RSA2C。该算法包含Actor、Value Critic和Advantage Critic三个模块。Actor在向量值再生核希尔伯特空间(RKHS)中实例化,使用Mahalanobis加权算子值核,而Value Critic和Advantage Critic则位于标量RKHS中。这些RKHS增强的组件使用稀疏字典:Value Critic维护自己的字典,而Actor和Advantage Critic共享一个字典。状态属性通过RKHS-SHAP(流形上期望的核均值嵌入和流形外期望的条件均值嵌入)从Value Critic计算得到,并转换为Mahalanobis门控权重,用于调节Actor梯度和Advantage Critic目标。论文推导了状态扰动下的全局非渐近收敛界,通过扰动误差项显示了稳定性,并通过收敛误差项显示了效率。在三个连续控制环境中的实验结果表明,RSA2C实现了效率、稳定性和可解释性。
🔬 方法详解
问题定义:现有的Actor-Critic (AC) 方法在强化学习中应用广泛,但缺乏可解释性。现有的可解释强化学习方法通常忽略了状态空间中不同维度特征对奖励信号的不同影响,简单地将所有特征同等对待,这限制了算法的效率和可解释性。
核心思路:论文的核心思路是利用状态属性(state attributions)来指导Actor-Critic算法的训练。具体来说,通过计算每个状态特征对Value Critic输出的影响,得到状态属性,并将其用于调整Actor的梯度更新和Advantage Critic的目标值,从而使算法更加关注重要的状态特征。
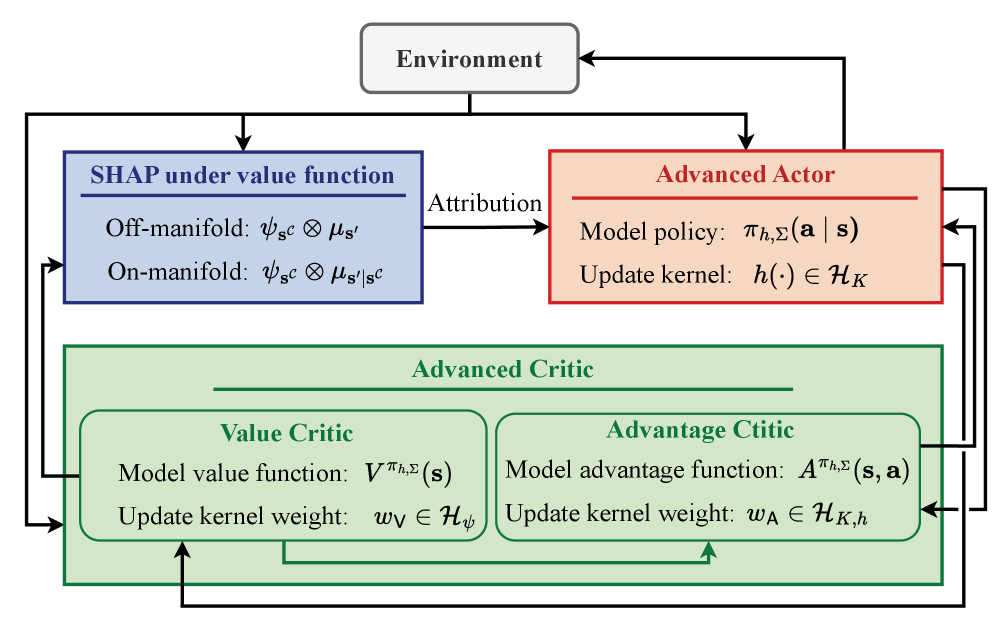
技术框架:RSA2C算法的整体框架包含三个主要模块:Actor、Value Critic和Advantage Critic。Actor负责选择动作,Value Critic负责评估状态的价值,Advantage Critic负责评估动作的优势。这三个模块都基于再生核希尔伯特空间(RKHS)构建,并使用稀疏字典来降低计算复杂度。Value Critic维护自己的字典,而Actor和Advantage Critic共享一个字典。状态属性通过RKHS-SHAP从Value Critic计算得到,并用于调整Actor的梯度和Advantage Critic的目标。
关键创新:论文的关键创新在于将SHAP值引入到Actor-Critic算法中,并利用RKHS-SHAP来计算状态属性。RKHS-SHAP能够有效地处理高维状态空间,并提供可解释的状态属性。此外,论文还提出了Mahalanobis门控权重,用于将状态属性转化为Actor梯度和Advantage Critic目标的调整因子。
关键设计:Actor在向量值RKHS中实例化,使用Mahalanobis加权算子值核,这使得Actor能够学习到更加复杂的策略。Value Critic和Advantage Critic则位于标量RKHS中。RKHS-SHAP的计算依赖于核均值嵌入(kernel mean embedding)和条件均值嵌入(conditional mean embedding),分别用于计算流形上和流形外的期望。Mahalanobis门控权重的计算涉及到Mahalanobis距离,用于衡量状态特征的重要性。
🖼️ 关键图片

📊 实验亮点
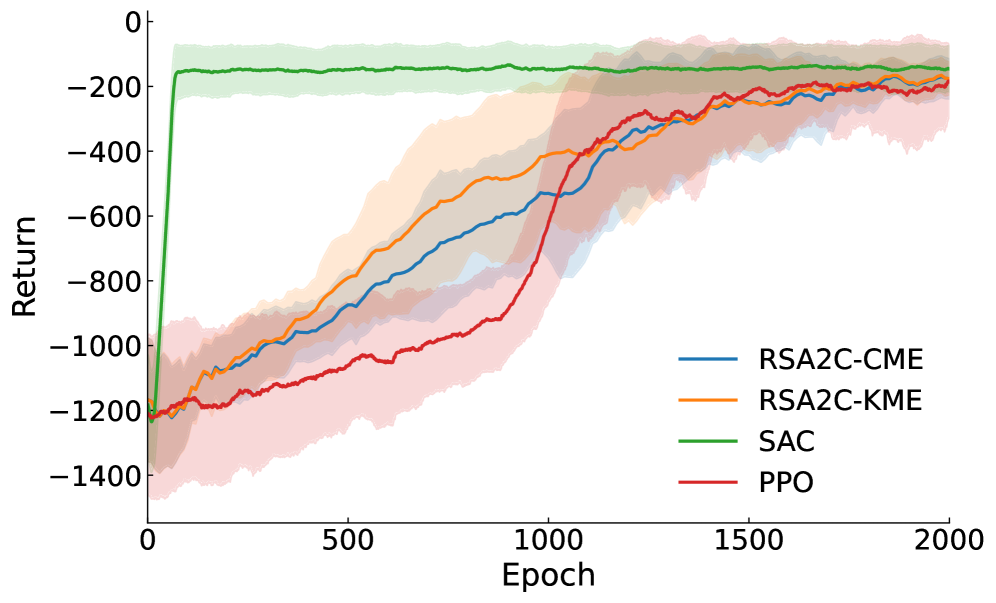
实验结果表明,RSA2C算法在三个连续控制环境中(具体环境名称未知)实现了效率、稳定性和可解释性的提升。相较于基线方法,RSA2C在性能上取得了显著的提高,同时提供了对决策过程的可解释性分析。论文还提供了全局非渐近收敛界,证明了算法的稳定性和效率。
🎯 应用场景
该研究成果可应用于需要高可解释性的强化学习场景,例如自动驾驶、医疗诊断和金融交易等。通过提供对决策过程的解释,可以提高用户对强化学习系统的信任度,并促进其在实际应用中的部署。此外,该方法还可以用于调试和优化强化学习算法,提高其性能和鲁棒性。
📄 摘要(原文)
Actor-critic (AC) methods are a cornerstone of reinforcement learning (RL) but offer limited interpretability. Current explainable RL methods seldom use state attributions to assist training. Rather, they treat all state features equally, thereby neglecting the heterogeneous impacts of individual state dimensions on the reward. We propose RKHS-SHAP-based Advanced Actor-Critic (RSA2C), an attribution-aware, kernelized, two-timescale AC algorithm, including Actor, Value Critic, and Advantage Critic. The Actor is instantiated in a vector-valued reproducing kernel Hilbert space (RKHS) with a Mahalanobis-weighted operator-valued kernel, while the Value Critic and Advantage Critic reside in scalar RKHSs. These RKHS-enhanced components use sparsified dictionaries: the Value Critic maintains its own dictionary, while the Actor and Advantage Critic share one. State attributions, computed from the Value Critic via RKHS-SHAP (kernel mean embedding for on-manifold and conditional mean embedding for off-manifold expectations), are converted into Mahalanobis-gated weights that modulate Actor gradients and Advantage Critic targets. We derive a global, non-asymptotic convergence bound under state perturbations, showing stability through the perturbation-error term and efficiency through the convergence-error term. Empirical results on three continuous-control environments show that RSA2C achieves efficiency, stability, and interpretability.