Coefficient of Variation Masking: A Volatility-Aware Strategy for EHR Foundation Models
作者: Rajna Fani, Rafi Al Attrach, David Restrepo, Yugang Jia, Leo Anthony Celi, Peter Schüffler
分类: cs.LG
发布日期: 2025-12-04
备注: 16 pages, 9 figures, 1 table, 1 algorithm. Accepted at Machine Learning for Health (ML4H) 2025, Proceedings of the Machine Learning Research (PMLR)
💡 一句话要点
提出变异系数掩码(CV-Masking)策略,提升EHR基础模型在波动性生物标志物上的表征能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电子健康记录 掩码自编码器 预训练 变异系数 时间序列 生物标志物 波动性建模
📋 核心要点
- 现有EHR基础模型预训练方法忽略了生物标志物波动性的差异,采用统一随机掩码,导致模型对波动性大的特征学习不足。
- 提出CV-Masking策略,根据每个特征的变异系数自适应调整掩码概率,使模型更关注波动性大的生物标志物。
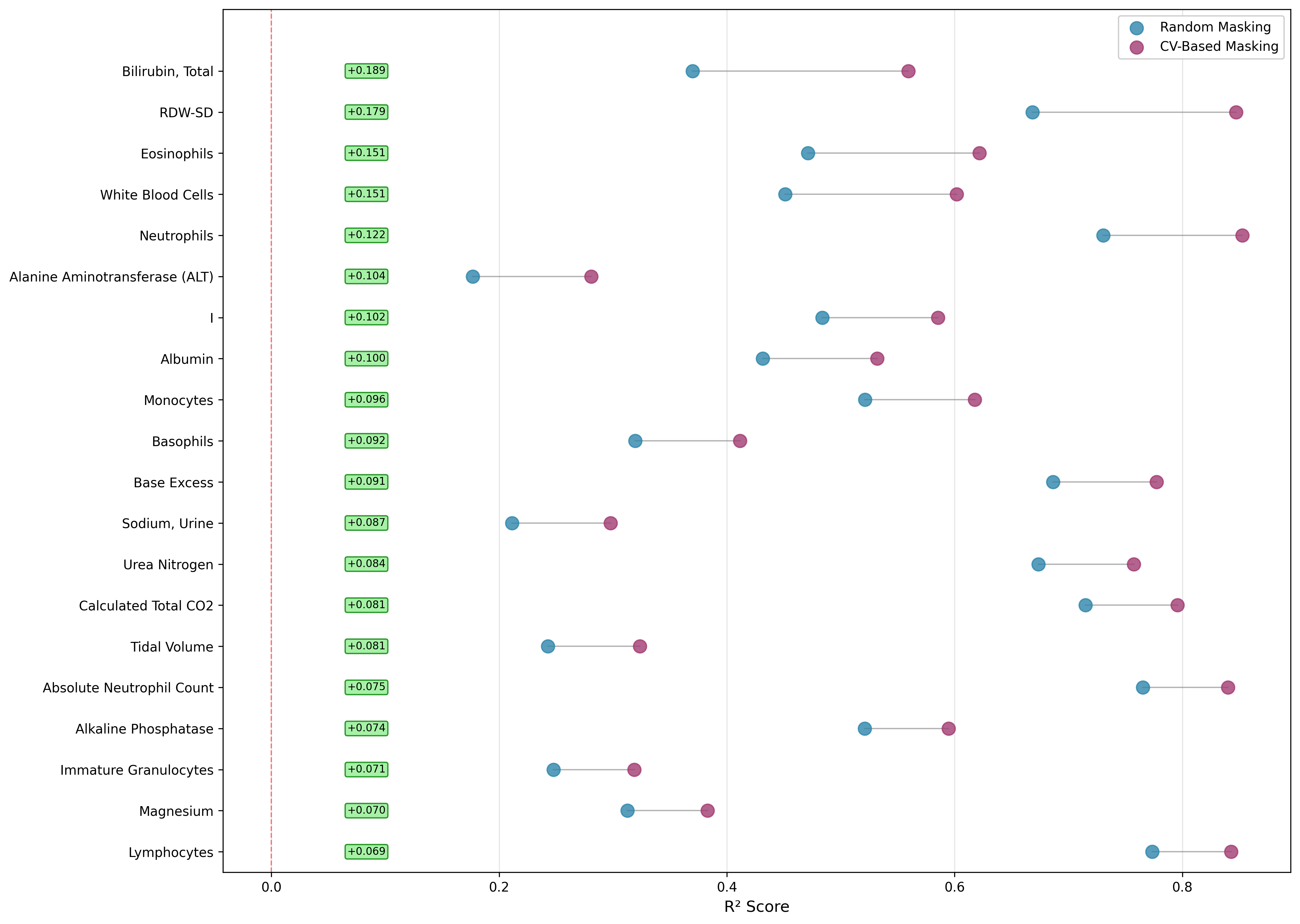
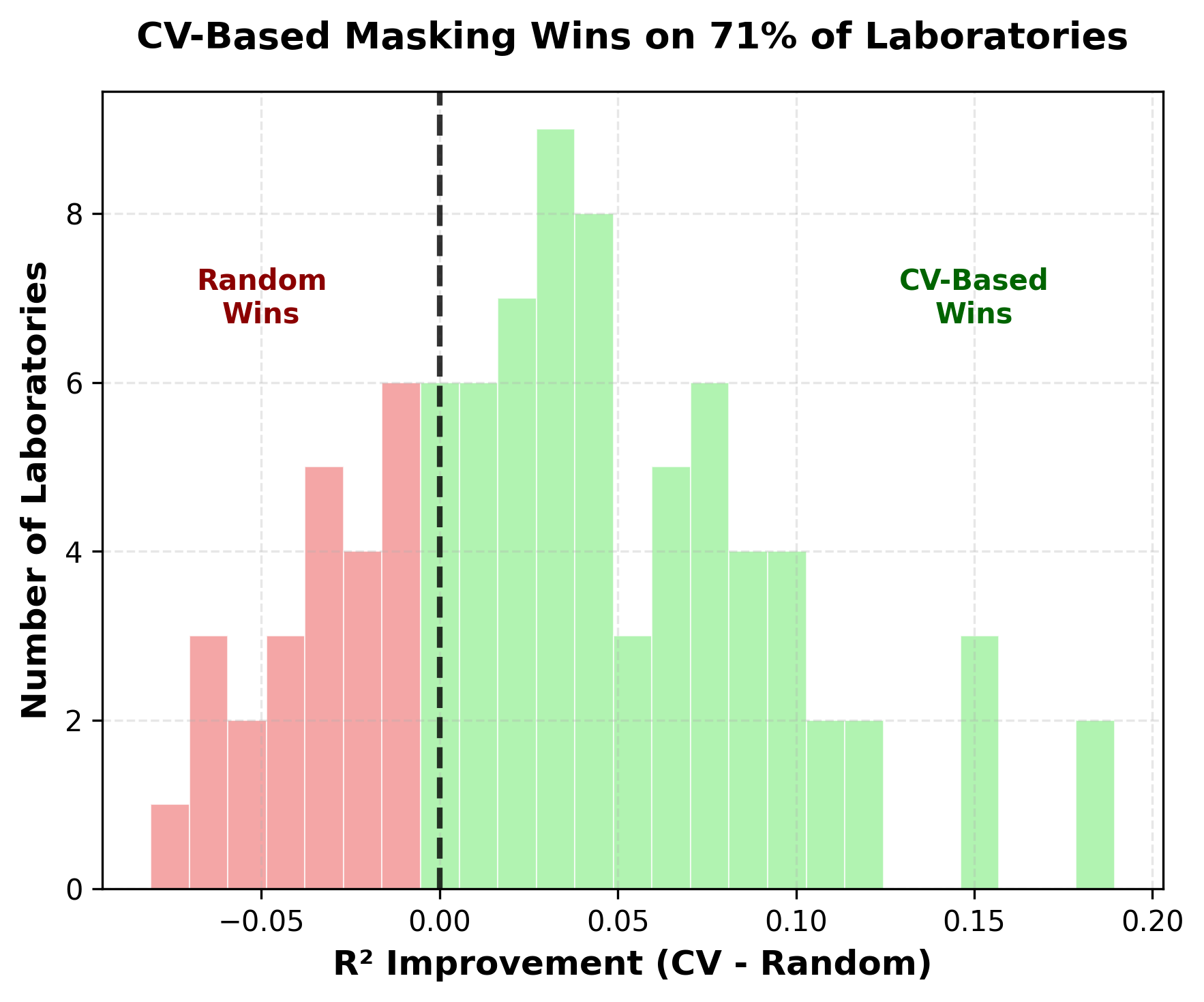
- 实验表明,CV-Masking在重建、下游预测和收敛速度方面均优于随机和基于方差的掩码策略,提升了EHR表征的临床意义。
📝 摘要(中文)
掩码自编码器(MAE)越来越多地应用于电子健康记录(EHR),以学习支持各种临床任务的通用表征。然而,现有方法通常依赖于均匀随机掩码,隐含地假设所有特征都同样可预测。实际上,实验室测试在波动性方面表现出很大的异质性:一些生物标志物(例如,钠)保持稳定,而另一些生物标志物(例如,乳酸)波动很大,更难建模。临床上,不稳定的生物标志物通常预示着急性病理生理学,需要更复杂的建模来捕捉其复杂的时间模式。我们提出了一种波动性感知预训练策略,即变异系数掩码(CV-Masking),它根据每个特征的内在变异性自适应地调整掩码概率。结合与临床工作流程一致的仅值掩码目标,CV-Masking 产生了优于随机和基于方差策略的系统性改进。在大量实验室测试面板上的实验表明,CV-Masking 增强了重建效果,提高了下游预测性能,并加速了收敛,从而产生了更鲁棒和具有临床意义的EHR表征。
🔬 方法详解
问题定义:现有基于掩码自编码器的EHR预训练方法,如MAE,通常采用均匀随机掩码策略。这种策略忽略了不同生物标志物在时间序列上的波动性差异。一些生物标志物(如钠)相对稳定,而另一些(如乳酸)则波动剧烈。这种波动性差异导致模型在学习时对波动性大的特征关注不足,影响了下游任务的性能。
核心思路:论文的核心思路是设计一种波动性感知的掩码策略,即CV-Masking。该策略的核心思想是根据每个特征的变异系数(Coefficient of Variation, CV)来动态调整掩码概率。变异系数越大,表示该特征的波动性越大,因此被掩码的概率也越高。这样可以迫使模型更多地关注波动性大的特征,从而更好地学习其复杂的时间模式。
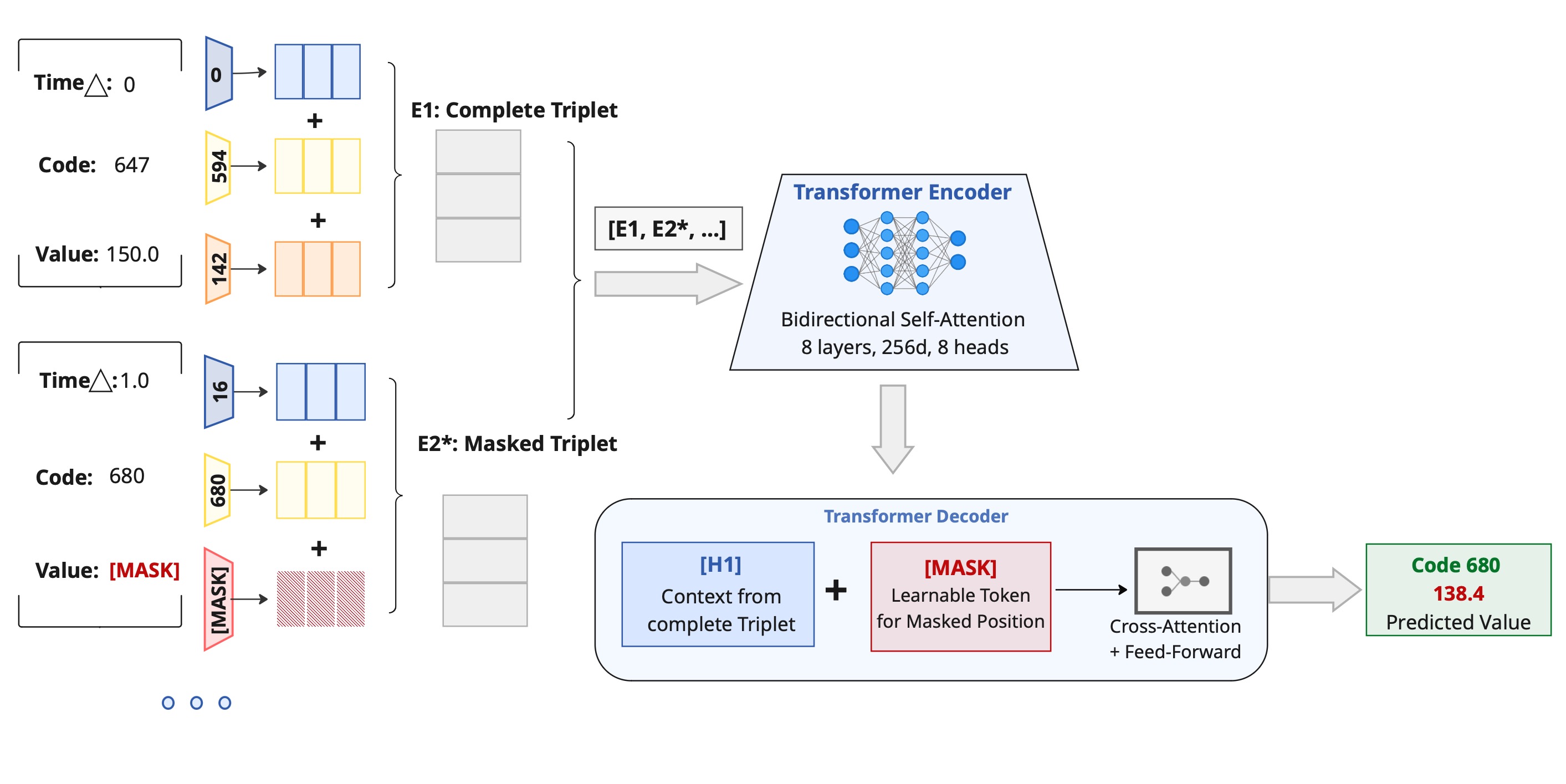
技术框架:CV-Masking可以集成到现有的掩码自编码器框架中。整体流程如下:1) 计算每个特征的变异系数;2) 根据变异系数调整掩码概率;3) 使用调整后的掩码概率对输入数据进行掩码;4) 将掩码后的数据输入到自编码器中进行训练;5) 使用重建损失函数优化模型参数。
关键创新:最重要的技术创新点在于提出了变异系数掩码策略,该策略能够根据特征的波动性自适应地调整掩码概率。与传统的随机掩码和基于方差的掩码策略相比,CV-Masking能够更有效地利用数据中的信息,从而提高模型的性能。此外,论文还结合了value-only masking,即只掩盖特征值,保留时间戳,更符合临床实际应用场景。
关键设计:CV-Masking的关键设计在于如何计算变异系数并将其映射到掩码概率。论文中,变异系数的计算方式为标准差除以均值。掩码概率的映射方式可以采用线性或非线性函数。此外,损失函数采用重建损失,即最小化原始数据与重建数据之间的差异。网络结构可以采用Transformer或其他适合时间序列数据的模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CV-Masking在多个下游预测任务上均优于随机掩码和基于方差的掩码策略。例如,在某些任务上,CV-Masking可以将性能提高5%以上。此外,CV-Masking还能够加速模型的收敛速度,减少训练时间。这些结果表明,CV-Masking是一种有效的EHR预训练策略。
🎯 应用场景
该研究成果可应用于多种临床场景,例如疾病预测、风险评估和个性化治疗。通过学习更鲁棒和具有临床意义的EHR表征,可以提高临床决策的准确性和效率。未来,该方法可以扩展到其他类型的医疗数据,如影像数据和基因组数据,从而构建更强大的医疗人工智能系统。
📄 摘要(原文)
Masked autoencoders (MAEs) are increasingly applied to electronic health records (EHR) for learning general-purpose representations that support diverse clinical tasks. However, existing approaches typically rely on uniform random masking, implicitly assuming all features are equally predictable. In reality, laboratory tests exhibit substantial heterogeneity in volatility: some biomarkers (e.g., sodium) remain stable, while others (e.g., lactate) fluctuate considerably and are more difficult to model. Clinically, volatile biomarkers often signal acute pathophysiology and require more sophisticated modeling to capture their complex temporal patterns. We propose a volatility-aware pretraining strategy, Coefficient of Variation Masking (CV-Masking), that adaptively adjusts masking probabilities according to the intrinsic variability of each feature. Combined with a value-only masking objective aligned with clinical workflows, CV-Masking yields systematic improvements over random and variance-based strategies. Experiments on a large panel of laboratory tests show that CV-Masking enhances reconstruction, improves downstream predictive performance, and accelerates convergence, producing more robust and clinically meaningful EHR representations.