MemLoRA: Distilling Expert Adapters for On-Device Memory Systems
作者: Massimo Bini, Ondrej Bohdal, Umberto Michieli, Zeynep Akata, Mete Ozay, Taha Ceritli
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-12-04
💡 一句话要点
MemLoRA:为端侧内存系统蒸馏专家适配器,实现高效本地部署。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内存增强 知识蒸馏 端侧部署 多模态学习 视觉问答
📋 核心要点
- 现有内存增强型大型语言模型(LLM)计算成本高昂,难以在本地设备上部署,且缺乏原生视觉能力,限制了其在多模态场景中的应用。
- MemLoRA通过知识蒸馏,为小型语言模型(SLM)配备专门的内存适配器,分别处理知识提取、内存更新和内存增强生成等操作。
- 实验表明,MemLoRA在文本任务上超越了10倍大的模型,并在视觉问答任务上显著优于基于字幕的方法,验证了其有效性。
📝 摘要(中文)
本文提出MemLoRA,一种新型内存系统,通过为小型语言模型(SLM)配备专门的内存适配器来实现本地部署。同时,提出了视觉扩展MemLoRA-V,它将小型视觉-语言模型(SVLM)集成到内存系统中,从而实现原生的视觉理解。遵循知识蒸馏原则,每个适配器都针对特定的内存操作(知识提取、内存更新和内存增强生成)进行单独训练。配备内存适配器后,小型模型无需云依赖即可实现准确的端侧内存操作。在纯文本操作中,MemLoRA优于大10倍的基线模型(如Gemma2-27B),并在LoCoMo基准测试中实现了与大60倍的模型(如GPT-OSS-120B)相当的性能。为了评估视觉理解操作,使用需要直接视觉推理的视觉问答任务扩展了LoCoMo。在此基础上,集成了VLM的MemLoRA-V在基于字幕的方法上显示出巨大的改进(81.3 vs. 23.7的准确率),同时在基于文本的任务中保持了强大的性能,证明了该方法在多模态环境中的有效性。
🔬 方法详解
问题定义:现有内存增强型LLM通常过于庞大,无法在资源受限的设备上本地部署。即使是小型语言模型(SLM),其性能也难以满足需求。此外,这些系统缺乏原生的视觉能力,限制了它们在多模态环境中的应用。因此,需要一种能够在本地设备上高效运行,并具备视觉理解能力的内存增强系统。
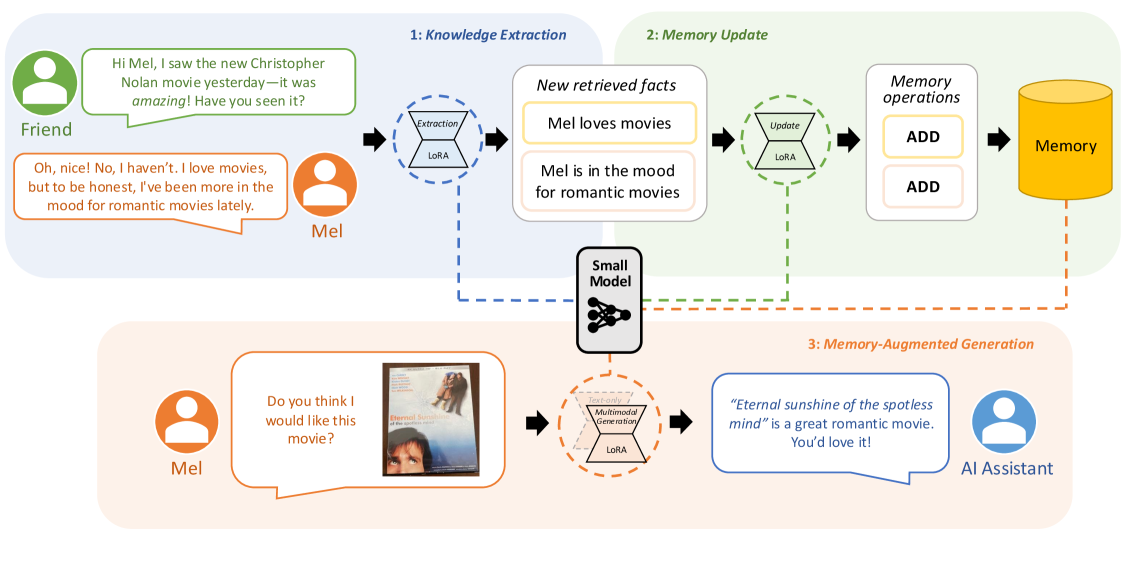
核心思路:论文的核心思路是利用知识蒸馏,将大型LLM的知识转移到小型SLM上,并为SLM配备专门的内存适配器。这些适配器针对不同的内存操作(知识提取、内存更新和内存增强生成)进行单独训练,从而使SLM能够高效地执行内存操作,并在多模态环境中实现良好的性能。
技术框架:MemLoRA包含三个主要的适配器模块:知识提取适配器、内存更新适配器和内存增强生成适配器。对于视觉扩展MemLoRA-V,则集成了小型视觉-语言模型(SVLM)。整体流程为:首先,知识提取适配器从输入中提取相关信息;然后,内存更新适配器将提取的信息更新到内存中;最后,内存增强生成适配器利用内存中的信息生成输出。在MemLoRA-V中,SVLM负责处理视觉输入,并将其与文本输入结合,以进行多模态推理。
关键创新:最重要的技术创新点在于针对不同的内存操作,分别训练专门的适配器。这种方法能够使SLM更有效地利用内存,并提高整体性能。此外,将SVLM集成到内存系统中,使系统具备了原生的视觉理解能力,从而扩展了其在多模态环境中的应用。
关键设计:论文采用了知识蒸馏的方法来训练适配器。具体来说,首先使用大型LLM生成训练数据,然后使用这些数据来训练小型SLM的适配器。损失函数的设计考虑了不同内存操作的特点,例如,在知识提取中,使用了交叉熵损失函数来衡量提取的信息与真实标签之间的差异。网络结构方面,适配器通常采用轻量级的Transformer结构,以减少计算开销。
🖼️ 关键图片


📊 实验亮点
MemLoRA在文本任务上超越了10倍大的基线模型(Gemma2-27B),并在LoCoMo基准测试中达到了与60倍大的模型(GPT-OSS-120B)相当的性能。在视觉问答任务中,MemLoRA-V的准确率达到了81.3%,显著优于基于字幕的方法(23.7%),证明了其在多模态环境中的有效性。
🎯 应用场景
MemLoRA可应用于各种需要本地化、个性化和多模态交互的场景,例如:智能助手、本地知识库问答、移动设备上的视觉问答、以及需要保护用户隐私的应用。该研究有助于推动AI在资源受限设备上的普及,并为开发更智能、更个性化的应用提供新的可能性。
📄 摘要(原文)
Memory-augmented Large Language Models (LLMs) have demonstrated remarkable consistency during prolonged dialogues by storing relevant memories and incorporating them as context. Such memory-based personalization is also key in on-device settings that allow users to keep their conversations and data private. However, memory-augmented systems typically rely on LLMs that are too costly for local on-device deployment. Even though Small Language Models (SLMs) are more suitable for on-device inference than LLMs, they cannot achieve sufficient performance. Additionally, these LLM-based systems lack native visual capabilities, limiting their applicability in multimodal contexts. In this paper, we introduce (i) MemLoRA, a novel memory system that enables local deployment by equipping SLMs with specialized memory adapters, and (ii) its vision extension MemLoRA-V, which integrates small Vision-Language Models (SVLMs) to memory systems, enabling native visual understanding. Following knowledge distillation principles, each adapter is trained separately for specific memory operations$\unicode{x2013}$knowledge extraction, memory update, and memory-augmented generation. Equipped with memory adapters, small models enable accurate on-device memory operations without cloud dependency. On text-only operations, MemLoRA outperforms 10$\times$ larger baseline models (e.g., Gemma2-27B) and achieves performance comparable to 60$\times$ larger models (e.g., GPT-OSS-120B) on the LoCoMo benchmark. To evaluate visual understanding operations instead, we extend LoCoMo with challenging Visual Question Answering tasks that require direct visual reasoning. On this, our VLM-integrated MemLoRA-V shows massive improvements over caption-based approaches (81.3 vs. 23.7 accuracy) while keeping strong performance in text-based tasks, demonstrating the efficacy of our method in multimodal contexts.