Rethinking Decoupled Knowledge Distillation: A Predictive Distribution Perspective
作者: Bowen Zheng, Ran Cheng
分类: cs.LG, cs.CV
发布日期: 2025-12-04
备注: Accepted to IEEE TNNLS
🔗 代码/项目: GITHUB
💡 一句话要点
提出广义解耦知识蒸馏(GDKD),从预测分布角度提升知识迁移效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 模型压缩 解耦学习 预测分布 logits蒸馏 深度学习 模型优化
📋 核心要点
- 现有知识蒸馏方法,特别是DKD,在logit知识利用上仍有提升空间,其内在机制需要更深入的理解。
- 论文提出广义解耦知识蒸馏(GDKD),从教师模型预测分布的角度出发,优化logits的解耦和加权策略。
- 实验结果表明,GDKD在多个数据集上超越了DKD和其他主流知识蒸馏方法,验证了其有效性。
📝 摘要(中文)
在知识蒸馏的发展历程中,研究重点曾从基于logits的方法转移到基于特征的方法。然而,解耦知识蒸馏(DKD)的出现重新强调了logit知识的重要性,它通过先进的解耦和加权策略来实现。虽然DKD是一个显著的进步,但其潜在机制值得更深入的探索。本文从预测分布的角度重新思考DKD。首先,引入了一个增强版本,即广义解耦知识蒸馏(GDKD)损失,它为解耦logits提供了一种更通用的方法。然后,特别关注教师模型的预测分布及其对GDKD损失梯度的影响,揭示了两个经常被忽视的关键见解:(1)通过top logit进行划分显著改善了非top logits之间的相互关系,(2)放大对非top logits的蒸馏损失的关注增强了它们之间的知识提取。利用这些见解,进一步提出了一种简化的GDKD算法,该算法具有高效的划分策略来处理教师模型预测分布的多模态性。在包括CIFAR-100、ImageNet、Tiny-ImageNet、CUB-200-2011和Cityscapes在内的各种基准上进行的综合实验表明,GDKD的性能优于原始DKD和其他领先的知识蒸馏方法。
🔬 方法详解
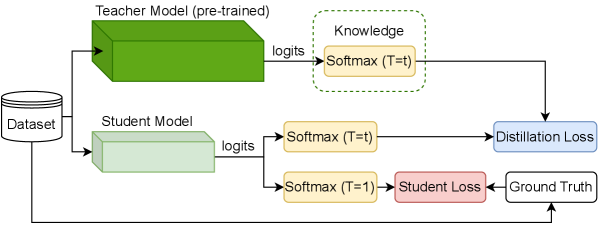
问题定义:知识蒸馏旨在将大型教师模型的知识迁移到小型学生模型。现有的解耦知识蒸馏(DKD)方法虽然在logit层面进行了改进,但对教师模型预测分布的理解和利用还不够充分,导致知识迁移效率受限。尤其是在处理复杂数据集时,教师模型预测分布的多模态性给知识提取带来了挑战。
核心思路:论文的核心思路是从教师模型的预测分布出发,通过更精细的解耦和加权策略,提升学生模型对教师模型logits的学习能力。具体来说,通过分析教师模型预测分布的特性,发现top logit对非top logits的影响,并据此设计更有效的损失函数。
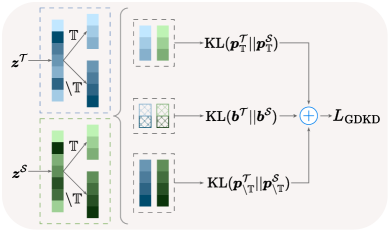
技术框架:GDKD的整体框架仍然是知识蒸馏的标准流程,包括教师模型、学生模型和蒸馏损失。关键在于GDKD损失的设计,它基于对教师模型预测分布的分析,对logits进行解耦和加权。算法流程主要包括:1) 使用教师模型和学生模型进行前向传播;2) 计算GDKD损失;3) 使用GDKD损失更新学生模型参数。
关键创新:GDKD的关键创新在于:1) 提出了广义的解耦方法,允许更灵活地控制logits之间的关系;2) 揭示了top logit对非top logits的重要性,并据此设计了新的损失函数;3) 提出了一种高效的划分策略,用于处理教师模型预测分布的多模态性。与现有方法的本质区别在于,GDKD更加关注教师模型预测分布的内在结构,并据此进行知识迁移。
关键设计:GDKD的关键设计包括:1) GDKD损失函数,它由多个部分组成,分别负责top logit和非top logits的蒸馏;2) 解耦参数,用于控制logits之间的关系;3) 加权策略,用于调整不同logits的蒸馏权重;4) 划分策略,用于处理教师模型预测分布的多模态性。具体的损失函数形式和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GDKD在CIFAR-100、ImageNet、Tiny-ImageNet、CUB-200-2011和Cityscapes等数据集上均取得了优于DKD和其他主流知识蒸馏方法的效果。例如,在ImageNet数据集上,GDKD相比DKD有显著的性能提升,验证了其有效性。
🎯 应用场景
GDKD可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测、以及资源受限环境下的自然语言处理。通过将大型模型的知识迁移到小型模型,GDKD能够有效降低计算成本和存储需求,同时保持较高的模型性能。该研究的未来影响在于推动知识蒸馏技术在实际应用中的普及。
📄 摘要(原文)
In the history of knowledge distillation, the focus has once shifted over time from logit-based to feature-based approaches. However, this transition has been revisited with the advent of Decoupled Knowledge Distillation (DKD), which re-emphasizes the importance of logit knowledge through advanced decoupling and weighting strategies. While DKD marks a significant advancement, its underlying mechanisms merit deeper exploration. As a response, we rethink DKD from a predictive distribution perspective. First, we introduce an enhanced version, the Generalized Decoupled Knowledge Distillation (GDKD) loss, which offers a more versatile method for decoupling logits. Then we pay particular attention to the teacher model's predictive distribution and its impact on the gradients of GDKD loss, uncovering two critical insights often overlooked: (1) the partitioning by the top logit considerably improves the interrelationship of non-top logits, and (2) amplifying the focus on the distillation loss of non-top logits enhances the knowledge extraction among them. Utilizing these insights, we further propose a streamlined GDKD algorithm with an efficient partition strategy to handle the multimodality of teacher models' predictive distribution. Our comprehensive experiments conducted on a variety of benchmarks, including CIFAR-100, ImageNet, Tiny-ImageNet, CUB-200-2011, and Cityscapes, demonstrate GDKD's superior performance over both the original DKD and other leading knowledge distillation methods. The code is available at https://github.com/ZaberKo/GDKD.