Natural Language Actor-Critic: Scalable Off-Policy Learning in Language Space
作者: Joey Hong, Kang Liu, Zhan Ling, Jiecao Chen, Sergey Levine
分类: cs.LG, cs.CL
发布日期: 2025-12-04 (更新: 2026-02-02)
备注: 21 pages, 4 figures
💡 一句话要点
提出自然语言Actor-Critic算法,解决LLM Agent在语言空间中的可扩展离线学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 强化学习 Actor-Critic 语言模型Agent 离线学习
📋 核心要点
- 现有LLM Agent训练依赖策略梯度,在长时程稀疏奖励任务中面临训练不稳定和样本复杂度高的挑战。
- 提出自然语言Actor-Critic (NLAC) 算法,使用生成式LLM Critic提供更丰富可操作的自然语言训练信号。
- NLAC可在离线情况下训练,无需策略梯度,在推理、网页浏览和工具使用等任务中表现出优于现有方法的潜力。
📝 摘要(中文)
大型语言模型(LLM)Agent,即能够与环境动态交互的LLM,已成为一个日益重要的研究领域,能够在涉及工具使用、网页浏览以及人际对话等复杂任务中实现自动化。在缺乏专家演示的情况下,训练LLM Agent依赖于策略梯度方法,该方法根据(通常是稀疏的)奖励函数来优化LLM策略。然而,在具有稀疏奖励的长时程任务中,从轨迹级别的奖励中学习可能充满噪声,导致训练不稳定且样本复杂度高。此外,策略改进取决于通过探索发现更好的动作,当动作位于自然语言空间时,这可能很困难。在本文中,我们提出了一种新的Actor-Critic算法——自然语言Actor-Critic(NLAC),该算法使用生成式LLM Critic来训练LLM策略,该Critic产生自然语言而非标量值。这种方法利用了LLM的内在优势,以提供更丰富、更可操作的训练信号;特别是在具有大型、开放式动作空间的任务中,对动作为何次优的自然语言解释对于LLM策略推理如何改进其动作非常有用,而无需依赖随机探索。此外,我们的方法可以在离线情况下进行训练,无需策略梯度,从而为现有的在线方法提供了一种更具数据效率和稳定性的替代方案。我们展示了在推理、网页浏览以及工具使用与对话任务混合中的结果,表明NLAC在优于现有训练方法方面显示出希望,并为LLM Agent提供了一种更具可扩展性和稳定性的训练范例。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在复杂任务中,由于奖励稀疏和动作空间巨大,导致训练不稳定和样本效率低下的问题。现有方法主要依赖于策略梯度,需要大量的在线探索,且对奖励噪声敏感。
核心思路:核心思路是利用LLM自身的语言理解和生成能力,构建一个能够输出自然语言评价的Critic。这个Critic不仅提供标量奖励,还能解释动作的优劣原因,从而为Actor提供更丰富的反馈信息,加速学习过程。
技术框架:NLAC算法包含两个主要模块:Actor和Critic。Actor是一个LLM,负责生成动作;Critic也是一个LLM,负责对Actor生成的动作进行评价,并给出自然语言解释。训练过程采用离线学习方式,即先收集一批数据,然后使用这些数据来训练Actor和Critic。Actor的目标是最大化Critic给出的奖励,Critic的目标是准确评价动作的优劣。
关键创新:关键创新在于使用自然语言作为Critic的输出。与传统的标量奖励相比,自然语言评价包含更丰富的信息,可以帮助Actor更好地理解环境,并改进自己的策略。此外,NLAC采用离线学习方式,避免了在线探索带来的高样本复杂度问题。
关键设计:Critic的训练目标是生成与人类评价一致的自然语言解释。可以使用监督学习方法,利用人工标注的数据来训练Critic。Actor的训练目标是最大化Critic给出的奖励,可以使用强化学习算法,如Q-learning或DDPG。论文中可能还涉及一些prompt工程的设计,以引导LLM生成更准确和有用的自然语言评价。
🖼️ 关键图片


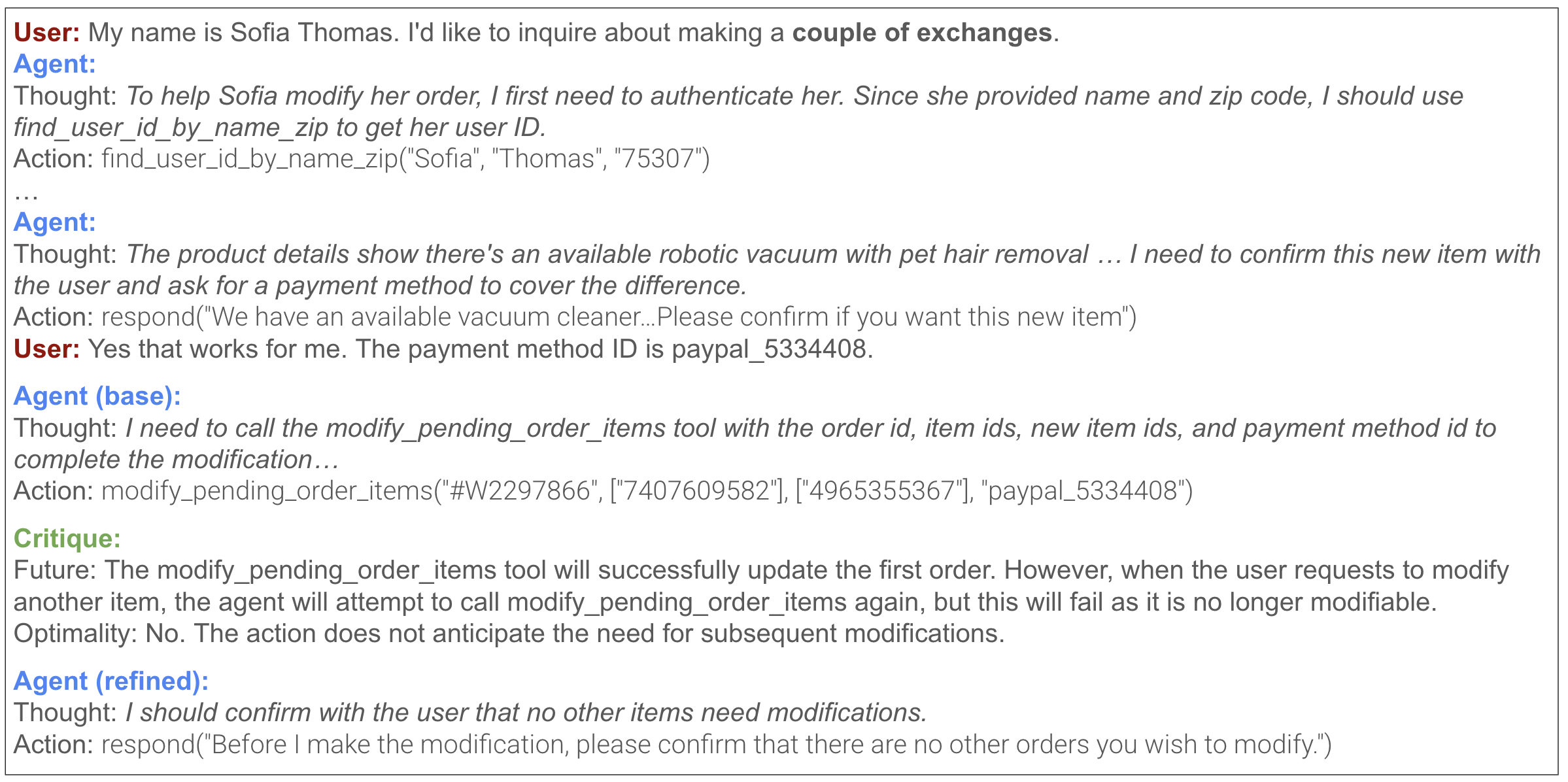
📊 实验亮点
论文在推理、网页浏览和工具使用等任务上进行了实验,结果表明NLAC算法优于现有的训练方法。具体性能提升数据未知,但论文强调NLAC在训练稳定性和可扩展性方面具有显著优势,为LLM Agent的训练提供了一种更有效的范式。
🎯 应用场景
NLAC算法具有广泛的应用前景,可以应用于各种需要LLM Agent与环境交互的复杂任务中,例如:智能客服、自动化网页浏览、机器人控制、游戏AI等。该研究有助于提升LLM Agent的自主学习能力和任务完成效率,降低人工干预成本,推动人工智能在实际场景中的应用。
📄 摘要(原文)
Large language model (LLM) agents -- LLMs that dynamically interact with an environment over long horizons -- have become an increasingly important area of research, enabling automation in complex tasks involving tool-use, web browsing, and dialogue with people. In the absence of expert demonstrations, training LLM agents has relied on policy gradient methods that optimize LLM policies with respect to an (often sparse) reward function. However, in long-horizon tasks with sparse rewards, learning from trajectory-level rewards can be noisy, leading to training that is unstable and has high sample complexity. Furthermore, policy improvement hinges on discovering better actions through exploration, which can be difficult when actions lie in natural language space. In this paper, we propose Natural Language Actor-Critic (NLAC), a novel actor-critic algorithm that trains LLM policies using a generative LLM critic that produces natural language rather than scalar values. This approach leverages the inherent strengths of LLMs to provide a richer and more actionable training signal; particularly, in tasks with large, open-ended action spaces, natural language explanations for why an action is suboptimal can be immensely useful for LLM policies to reason how to improve their actions, without relying on random exploration. Furthermore, our approach can be trained off-policy without policy gradients, offering a more data-efficient and stable alternative to existing on-policy methods. We present results on a mixture of reasoning, web browsing, and tool-use with dialogue tasks, demonstrating that NLAC shows promise in outperforming existing training approaches and offers a more scalable and stable training paradigm for LLM agents.