SPARK: Stepwise Process-Aware Rewards for Reference-Free Reinforcement Learning
作者: Salman Rahman, Sruthi Gorantla, Arpit Gupta, Swastik Roy, Nanyun Peng, Yang Liu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-02
💡 一句话要点
SPARK:提出基于逐步过程感知的免参考强化学习框架,提升数学推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 过程奖励模型 免参考学习 数学推理 自洽性验证
📋 核心要点
- 现有强化学习方法依赖于昂贵的步骤级标注或参考答案,限制了其在许多实际场景中的应用。
- SPARK框架通过生成器和验证器模型,合成高质量的训练数据,用于训练过程奖励模型,无需人工标注。
- 实验表明,SPARK在数学推理任务上优于基于真实结果的强化学习方法,并显著提升了性能。
📝 摘要(中文)
本文提出SPARK,一个三阶段框架,旨在解决强化学习中对密集、步骤级反馈的需求,同时避免昂贵的步骤级标注或参考答案。第一阶段,生成器模型产生多样化的解,验证器模型使用并行缩放(自洽性)和顺序缩放(元批判)评估这些解。第二阶段,使用验证输出作为合成训练数据,微调生成式过程奖励模型,该模型随后作为训练期间的奖励信号。实验表明,在步骤级别聚合多个独立验证,能够为过程奖励模型生成优于真实结果监督的训练数据,在ProcessBench上达到67.5的F1值,高于参考引导训练的66.4和GPT-4o的61.9。最后,将带有思维链验证的生成式PRM(PRM-CoT)应用于数学推理的强化学习实验,并引入格式约束以防止奖励黑客。使用Qwen2.5-Math-7B,在六个数学推理基准测试中实现了47.4%的平均准确率,优于基于真实结果的RLVR(43.9%)。该工作实现了超越真实结果方法的免参考强化学习训练,为缺乏可验证答案或可访问真实结果的领域开辟了新的可能性。
🔬 方法详解
问题定义:论文旨在解决强化学习在缺乏步骤级标注或参考答案的情况下,难以进行有效训练的问题。现有方法要么依赖于昂贵的人工标注,要么需要预先存在的参考答案,这限制了它们在许多实际场景中的应用,尤其是在那些难以获得ground truth的任务中。
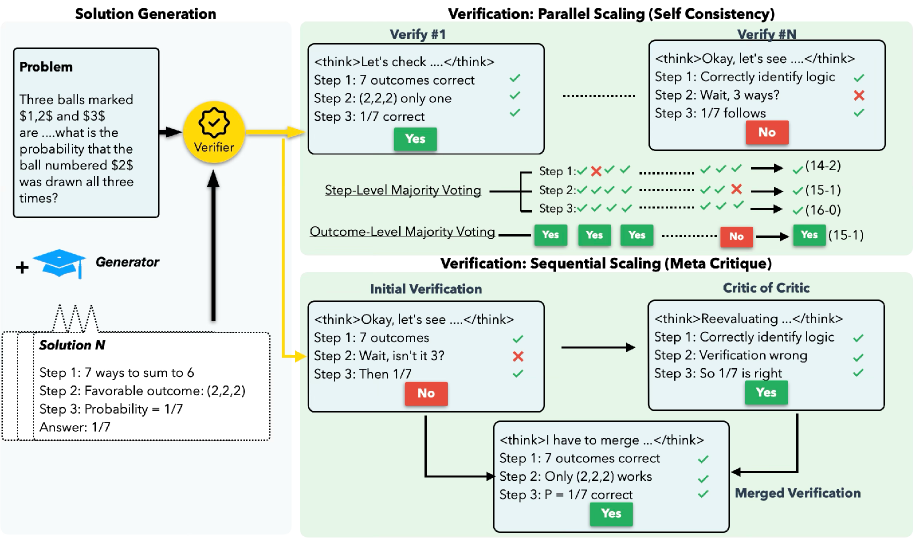
核心思路:论文的核心思路是利用生成模型和验证模型,自动生成高质量的训练数据,用于训练过程奖励模型(PRM)。通过并行缩放(自洽性)和顺序缩放(元批判)来评估生成模型的输出,从而无需人工标注或参考答案即可获得可靠的奖励信号。
技术框架:SPARK框架包含三个主要阶段: 1. 生成阶段:使用生成器模型生成多样化的解决方案。 2. 验证阶段:使用验证器模型评估生成器模型的输出,生成合成训练数据。 3. 强化学习阶段:使用过程奖励模型作为奖励信号,训练强化学习智能体。
关键创新:最重要的技术创新点在于使用生成模型和验证模型,自动生成高质量的训练数据,从而避免了对人工标注或参考答案的依赖。通过并行缩放和顺序缩放,可以有效地评估生成模型的输出,并生成可靠的奖励信号。此外,引入格式约束以防止奖励黑客,提高了强化学习训练的稳定性。
关键设计: * 生成模型:用于生成多样化的解决方案,可以使用各种生成模型,如Transformer模型。 * 验证模型:用于评估生成模型的输出,可以使用并行缩放(自洽性)和顺序缩放(元批判)等方法。 * 过程奖励模型:用于预测每个步骤的奖励,可以使用各种回归模型。 * 格式约束:用于限制强化学习智能体的输出格式,防止奖励黑客。
🖼️ 关键图片


📊 实验亮点
SPARK在ProcessBench数学推理任务上取得了显著的成果,F1值达到67.5%,超过了参考引导训练的66.4%和GPT-4o的61.9%。在六个数学推理基准测试中,使用Qwen2.5-Math-7B作为基础模型,SPARK实现了47.4%的平均准确率,优于基于真实结果的RLVR(43.9%)。
🎯 应用场景
SPARK框架具有广泛的应用前景,可以应用于各种缺乏可验证答案或可访问真实结果的领域,例如代码生成、文本摘要、对话生成等。该方法可以降低强化学习的训练成本,并提高模型的性能,从而促进人工智能技术在更多领域的应用。
📄 摘要(原文)
Process reward models (PRMs) that provide dense, step-level feedback have shown promise for reinforcement learning, yet their adoption remains limited by the need for expensive step-level annotations or ground truth references. We propose SPARK: a three-stage framework where in the first stage a generator model produces diverse solutions and a verifier model evaluates them using parallel scaling (self-consistency) and sequential scaling (meta-critique). In the second stage, we use these verification outputs as synthetic training data to fine-tune generative process reward models, which subsequently serve as reward signals during training. We show that aggregating multiple independent verifications at the step level produces training data for process reward models that surpass ground-truth outcome supervision, achieving 67.5 F1 on ProcessBench (a benchmark for identifying erroneous steps in mathematical reasoning) compared to 66.4 for reference-guided training and 61.9 for GPT-4o. In the final stage, we apply our generative PRM with chain-of-thought verification (PRM-CoT) as the reward model in RL experiments on mathematical reasoning, and introduce format constraints to prevent reward hacking. Using Qwen2.5-Math-7B, we achieve 47.4% average accuracy across six mathematical reasoning benchmarks, outperforming ground-truth-based RLVR (43.9%). Our work enables reference-free RL training that exceeds ground-truth methods, opening new possibilities for domains lacking verifiable answers or accessible ground truth.