AlignSAE: Concept-Aligned Sparse Autoencoders
作者: Minglai Yang, Xinyu Guo, Zhengliang Shi, Jinhe Bi, Steven Bethard, Mihai Surdeanu, Liangming Pan
分类: cs.LG, cs.CL
发布日期: 2025-12-01 (更新: 2026-01-13)
备注: 23 pages, 16 figures, 7 tables
💡 一句话要点
提出AlignSAE,通过概念对齐的稀疏自编码器实现LLM内部知识的可控干预。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 概念对齐 可解释性 知识干预 大型语言模型 因果推理 Grokking 课程学习
📋 核心要点
- 现有稀疏自编码器难以将LLM内部特征与人类概念对齐,导致特征表示纠缠。
- AlignSAE通过预训练和后训练,将SAE特征与预定义本体对齐,实现概念与特征的解耦。
- 实验表明AlignSAE能够实现精确的概念干预,支持多跳推理,并能探测Grokking类泛化动态。
📝 摘要(中文)
大型语言模型(LLM)将事实知识编码在难以检查或控制的隐藏参数空间中。稀疏自编码器(SAE)可以将隐藏激活分解为更细粒度、可解释的特征,但它们通常难以可靠地将这些特征与人类定义的概念对齐,导致特征表示纠缠和分散。为了解决这个问题,我们提出AlignSAE,一种通过“预训练,后训练”课程将SAE特征与预定义本体对齐的方法。在初始的无监督训练阶段之后,我们应用监督后训练将特定概念绑定到专用潜在槽,同时保留剩余容量用于一般重建。这种分离创建了一个可解释的接口,可以在不干扰不相关特征的情况下检查和控制特定概念。实验结果表明,AlignSAE通过针对单个语义对齐的槽,能够实现精确的因果干预,例如可靠的“概念交换”,并进一步支持多跳推理和对Grokking类泛化动态的机械探测。
🔬 方法详解
问题定义:大型语言模型(LLM)虽然强大,但其内部知识表示难以理解和控制。稀疏自编码器(SAE)旨在将LLM的隐藏层激活分解为更易于理解的特征,但现有的SAE方法难以保证分解出的特征与人类定义的特定概念对齐,导致特征表示分散且纠缠,难以进行精确的概念干预。
核心思路:AlignSAE的核心思路是通过一个两阶段的训练流程,首先进行无监督的预训练,学习通用的特征表示能力,然后进行有监督的后训练,将特定的概念与SAE的特定神经元(或称为槽)绑定。这样,每个槽就对应一个明确的概念,从而实现概念与特征的解耦,方便进行概念层面的干预和分析。
技术框架:AlignSAE的整体框架包含两个主要阶段:预训练阶段和后训练阶段。在预训练阶段,使用标准的稀疏自编码器训练方法,学习从LLM隐藏层激活到稀疏特征的映射。在后训练阶段,引入监督信号,使用带有标签的数据集,将特定概念与特定的SAE神经元进行对齐。后训练阶段的目标是最小化重构误差的同时,最大化特定神经元对特定概念的激活程度。
关键创新:AlignSAE的关键创新在于其“预训练,后训练”的课程学习策略,以及将监督信号引入SAE训练过程,实现概念与特征的对齐。与传统的SAE方法相比,AlignSAE能够更好地将LLM内部的知识表示与人类可理解的概念联系起来,从而实现更精确的控制和干预。
关键设计:AlignSAE的关键设计包括:1) 使用L1正则化来保证SAE的稀疏性;2) 在后训练阶段,使用交叉熵损失函数来衡量概念预测的准确性;3) 设计合适的后训练数据集,包含与目标概念相关的样本;4) 调整预训练和后训练的学习率,以平衡重构误差和概念对齐的精度。具体的网络结构和参数设置需要根据具体的LLM和目标概念进行调整,论文中可能提供了具体的实验参数。
🖼️ 关键图片


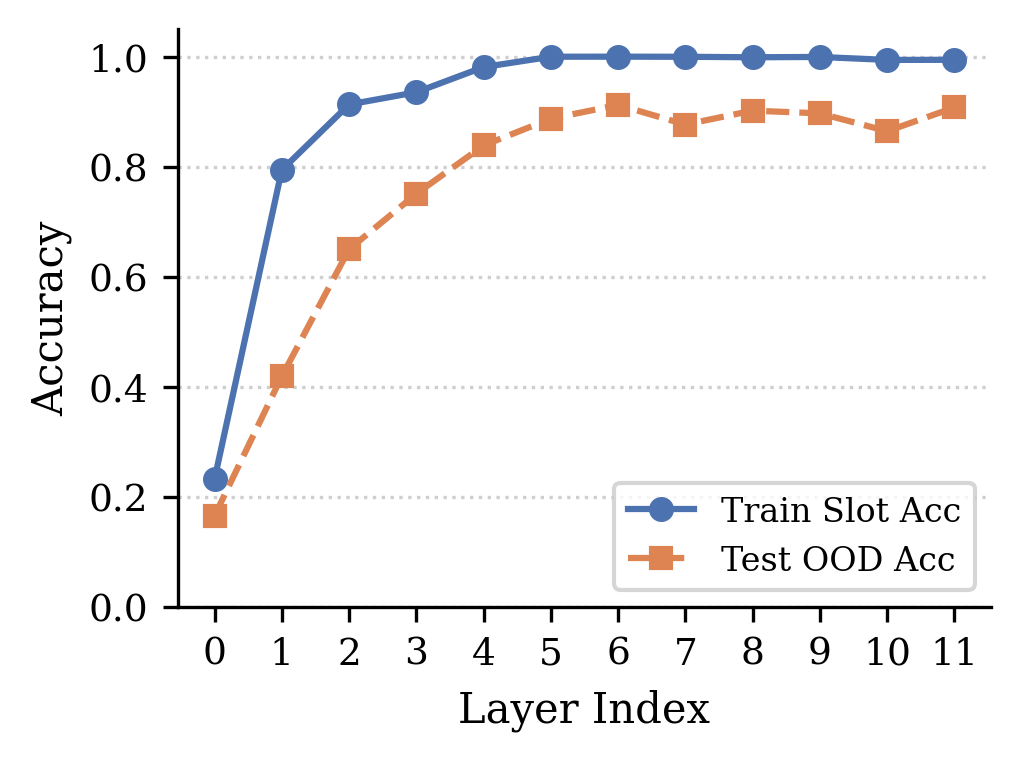
📊 实验亮点
AlignSAE在实验中展示了其精确的概念干预能力,例如通过“概念交换”实验,成功地将LLM中关于一个概念的知识替换为另一个概念的知识,而不会影响其他概念的表示。此外,AlignSAE还被用于分析LLM的推理过程,并揭示了Grokking类泛化动态的内在机制。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
AlignSAE可应用于提升LLM的可解释性和可控性,例如:1) 知识编辑:精确修改LLM中关于特定概念的知识;2) 风险控制:移除LLM中与有害概念相关的知识;3) 智能问答:通过分析LLM内部激活,理解其推理过程;4) 提升模型鲁棒性:通过干预特定概念,提高模型在对抗攻击下的稳定性。该研究有助于构建更安全、可靠和可信赖的AI系统。
📄 摘要(原文)
Large Language Models (LLMs) encode factual knowledge within hidden parametric spaces that are difficult to inspect or control. While Sparse Autoencoders (SAEs) can decompose hidden activations into more fine-grained, interpretable features, they often struggle to reliably align these features with human-defined concepts, resulting in entangled and distributed feature representations. To address this, we introduce AlignSAE, a method that aligns SAE features with a predefined ontology through a "pre-train, then post-train" curriculum. After an initial unsupervised training phase, we apply supervised post-training to bind specific concepts to dedicated latent slots while preserving the remaining capacity for general reconstruction. This separation creates an interpretable interface where specific concepts can be inspected and controlled without interference from unrelated features. Empirical results demonstrate that AlignSAE enables precise causal interventions, such as reliable "concept swaps", by targeting single, semantically aligned slots, and further supports multi-hop reasoning and a mechanistic probe of grokking-like generalization dynamics.