Forecasting in Offline Reinforcement Learning for Non-stationary Environments
作者: Suzan Ece Ada, Georg Martius, Emre Ugur, Erhan Oztop
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-12-01 (更新: 2025-12-27)
备注: The Thirty-Ninth Annual Conference on Neural Information Processing Systems, NeurIPS 2025
💡 一句话要点
提出FORL框架,解决离线强化学习在非平稳环境中因状态偏移导致的性能下降问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线强化学习 非平稳环境 状态预测 条件扩散模型 时间序列预测 零样本学习 强化学习
📋 核心要点
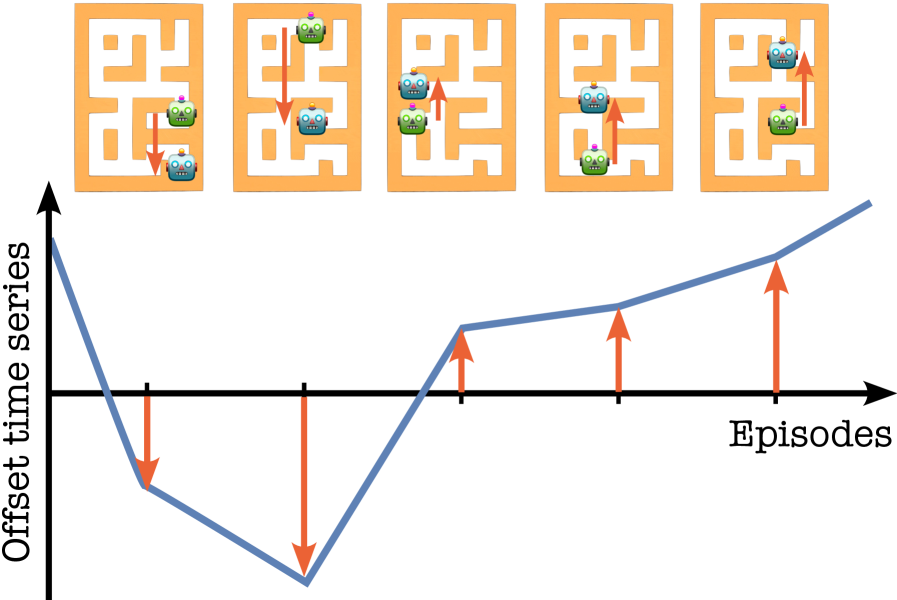
- 现有离线强化学习方法在非平稳环境下表现不佳,因为它们通常假设环境是静态的,无法应对真实世界中突发的状态偏移。
- FORL框架通过结合条件扩散模型生成候选状态和零样本时间序列预测模型,来预测和适应环境中的非平稳性。
- 实验结果表明,FORL在模拟真实非平稳环境的离线强化学习基准测试中,性能优于其他基线方法。
📝 摘要(中文)
本文提出了一种名为“非平稳离线强化学习中的预测”(FORL)的框架,旨在解决离线强化学习在非平稳环境中面临的挑战。现有离线强化学习方法通常假设环境是平稳的,或者只考虑测试时的合成扰动,这在现实世界中是不成立的,因为现实世界中存在突发且随时间变化的偏移。这些偏移会导致部分可观测性,使智能体错误地感知其真实状态,从而降低性能。FORL框架统一了(i)基于条件扩散的候选状态生成,该生成过程无需预设任何特定的未来非平稳模式,以及(ii)零样本时间序列基础模型。FORL的目标是那些容易出现意外的、可能非马尔可夫偏移的环境,要求智能体在每个episode开始时就具有强大的性能。在离线强化学习基准上的实证评估表明,通过使用真实世界的时间序列数据来模拟现实的非平稳性,FORL始终优于具有竞争力的基线方法。通过将零样本预测与智能体的经验相结合,旨在弥合离线强化学习与现实世界非平稳环境的复杂性之间的差距。
🔬 方法详解
问题定义:离线强化学习在非平稳环境中面临的主要问题是环境状态的突发偏移,导致智能体无法准确感知当前状态,从而影响策略的有效性。现有方法通常假设环境平稳或仅考虑合成扰动,无法有效应对真实世界中复杂的非平稳性。
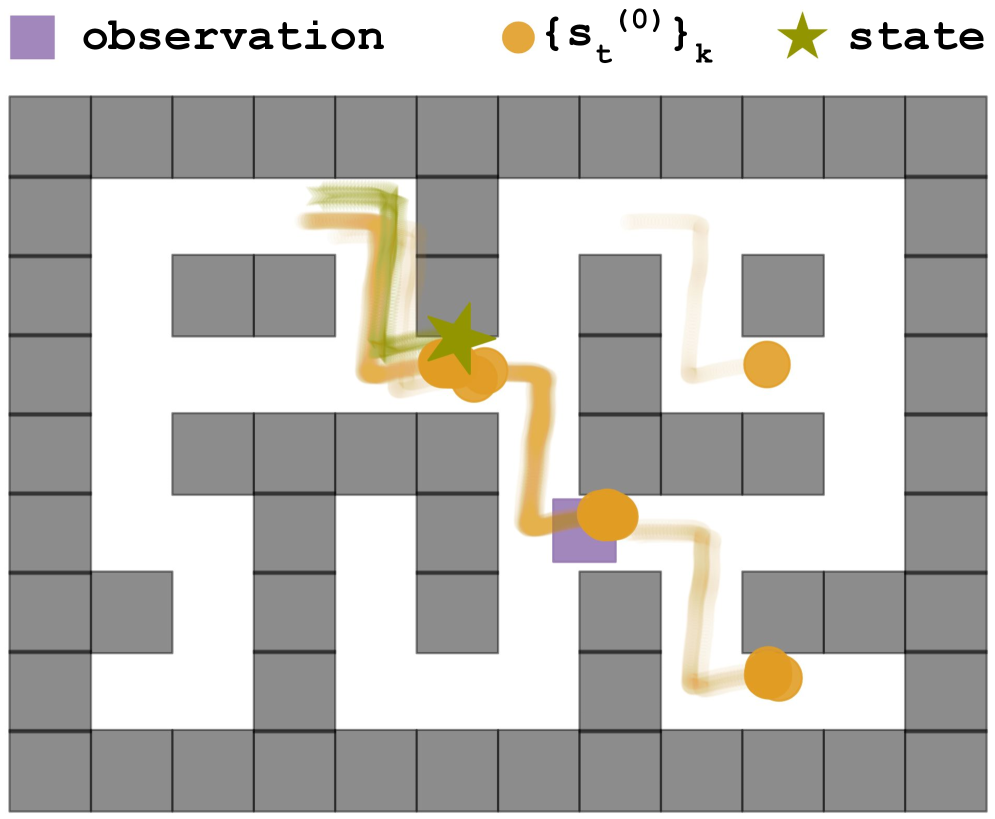
核心思路:FORL的核心思路是利用预测来增强智能体对非平稳环境的适应能力。通过预测未来可能的状态,智能体可以更好地理解当前环境,并制定更有效的策略。该方法结合了条件扩散模型生成候选状态和零样本时间序列模型进行预测,从而在没有特定非平稳模式先验知识的情况下,提高智能体的鲁棒性。
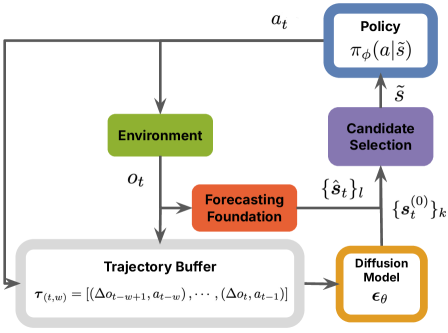
技术框架:FORL框架主要包含两个核心模块:(1) 基于条件扩散的候选状态生成器:该模块利用离线数据训练一个条件扩散模型,用于生成未来可能的状态。条件可以是当前状态、历史状态或其他相关信息。(2) 零样本时间序列预测模型:该模块利用预训练的时间序列模型,对环境的未来状态进行预测。这两个模块的输出被整合到智能体的决策过程中,帮助智能体更好地适应非平稳环境。
关键创新:FORL的关键创新在于将条件扩散模型和零样本时间序列预测模型结合起来,用于解决离线强化学习在非平稳环境中的问题。这种结合使得智能体能够在没有特定非平稳模式先验知识的情况下,预测和适应环境的变化。此外,FORL框架的设计允许智能体在每个episode开始时就具有强大的性能,这对于那些容易出现意外偏移的环境至关重要。
关键设计:条件扩散模型使用离线数据进行训练,目标是生成与环境状态分布相似的候选状态。零样本时间序列预测模型采用预训练模型,无需针对特定环境进行微调。框架的关键在于如何有效地整合这两个模块的输出,并将其融入到智能体的决策过程中。具体的整合方式可能涉及加权平均、注意力机制或其他融合策略。损失函数的设计需要考虑预测的准确性和策略的有效性。
🖼️ 关键图片
📊 实验亮点
FORL在离线强化学习基准测试中表现出色,通过使用真实世界的时间序列数据模拟非平稳环境,FORL始终优于其他基线方法。具体性能提升幅度未知,但论文强调了FORL在应对非平稳环境方面的优势。实验结果表明,FORL能够有效地预测和适应环境的变化,从而提高智能体的鲁棒性和性能。
🎯 应用场景
FORL框架具有广泛的应用前景,例如在机器人导航、自动驾驶、金融交易等领域。在这些领域中,环境通常是非平稳的,智能体需要能够适应环境的变化才能做出正确的决策。FORL框架可以帮助智能体在这些复杂环境中实现更鲁棒和高效的性能,从而提高系统的可靠性和效率。未来,FORL可以进一步扩展到多智能体系统和更复杂的非平稳环境。
📄 摘要(原文)
Offline Reinforcement Learning (RL) provides a promising avenue for training policies from pre-collected datasets when gathering additional interaction data is infeasible. However, existing offline RL methods often assume stationarity or only consider synthetic perturbations at test time, assumptions that often fail in real-world scenarios characterized by abrupt, time-varying offsets. These offsets can lead to partial observability, causing agents to misperceive their true state and degrade performance. To overcome this challenge, we introduce Forecasting in Non-stationary Offline RL (FORL), a framework that unifies (i) conditional diffusion-based candidate state generation, trained without presupposing any specific pattern of future non-stationarity, and (ii) zero-shot time-series foundation models. FORL targets environments prone to unexpected, potentially non-Markovian offsets, requiring robust agent performance from the onset of each episode. Empirical evaluations on offline RL benchmarks, augmented with real-world time-series data to simulate realistic non-stationarity, demonstrate that FORL consistently improves performance compared to competitive baselines. By integrating zero-shot forecasting with the agent's experience, we aim to bridge the gap between offline RL and the complexities of real-world, non-stationary environments.