Agentic Policy Optimization via Instruction-Policy Co-Evolution
作者: Han Zhou, Xingchen Wan, Ivan Vulić, Anna Korhonen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-01 (更新: 2026-01-31)
备注: 8 pages, 4 figures, 1 table (17 pages including references and appendices)
💡 一句话要点
提出INSPO,通过指令-策略协同进化优化Agentic策略,提升多轮推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 指令优化 策略优化 协同进化 多轮推理 Agentic策略
📋 核心要点
- 现有RLVR方法依赖静态指令,可能并非模型最优,且忽略了策略改进对最优指令的影响。
- INSPO框架将指令优化融入RL循环,通过指令-策略协同进化,动态调整指令以适应Agent策略。
- 实验表明,INSPO在多轮检索和推理任务上显著优于静态指令基线,提升Agent推理能力。
📝 摘要(中文)
强化学习与可验证奖励(RLVR)提升了大型语言模型(LLM)的推理能力,使其能够作为自主Agent进行有效多轮和工具集成推理。虽然指令是定义Agent的主要协议,但RLVR通常依赖于静态和手动设计的指令。这些指令可能对于基础模型而言并非最优,并且随着Agent策略的改进和与环境交互的探索,最优指令可能会发生变化。为了弥合这一差距,我们引入了INSPO,这是一种新颖的指令-策略协同进化框架,它将指令优化集成为强化学习(RL)循环的动态组件。INSPO维护一个动态的指令候选集,这些指令通过问题进行采样,RL循环中的奖励信号会自动归因于每个指令,并且定期修剪低性能者。通过基于LLM的优化器分析来自回放缓冲区的过去经验,并根据当前策略演化出更有效的策略,从而生成并通过在线反思机制验证新指令。我们在多轮检索和推理任务上进行了大量实验,表明INSPO显著优于依赖静态指令的强大基线。INSPO发现了引导Agent走向更具战略性的推理路径的创新指令,仅以少量增加计算开销为代价实现了显著的性能提升。
🔬 方法详解
问题定义:现有基于强化学习的Agent通常使用静态的、人工设计的指令。这些指令可能并非对于初始模型是最优的,并且随着Agent与环境交互并学习,最优指令也会发生变化。因此,如何动态地优化指令,使其与Agent的策略相适应,是一个关键问题。
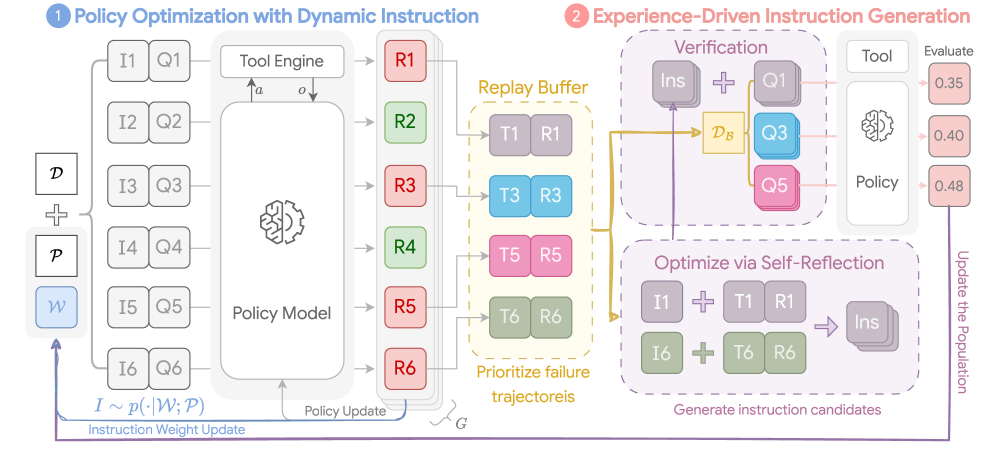
核心思路:INSPO的核心思路是将指令优化作为一个动态组件集成到强化学习循环中,实现指令和策略的协同进化。通过维护一个指令候选集,并根据Agent在环境中的表现,动态地生成、评估和选择指令,从而找到更适合当前策略的指令。
技术框架:INSPO框架包含以下主要模块:1) 指令池:维护一个动态的指令候选集。2) 指令采样:根据一定的策略从指令池中选择指令。3) 策略学习:使用强化学习算法训练Agent的策略。4) 奖励归因:将Agent在环境中的奖励信号归因于每个指令。5) 指令评估:根据奖励信号评估指令的性能。6) 指令进化:使用LLM生成新的指令,并验证其有效性。
关键创新:INSPO的关键创新在于指令-策略协同进化的思想。它将指令优化和策略学习紧密结合,使得指令能够随着策略的改进而不断优化,从而提升Agent的整体性能。此外,使用LLM进行指令生成和验证,可以有效地探索新的指令空间。
关键设计:INSPO使用on-policy reflection机制来生成和验证新的指令。具体来说,LLM-based optimizer分析来自replay buffer的过去经验,并根据当前策略演化出更有效的策略。指令池的大小、指令采样的策略、奖励归因的方法、以及LLM的prompt设计等都是重要的技术细节。
🖼️ 关键图片

📊 实验亮点
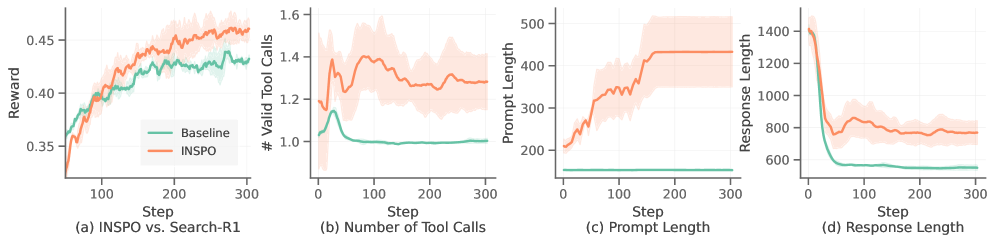
实验结果表明,INSPO在多轮检索和推理任务上显著优于依赖静态指令的基线方法。例如,在某个任务上,INSPO的性能提升了超过10%。此外,INSPO还能够发现一些人工难以设计的创新指令,这些指令能够引导Agent走向更具战略性的推理路径。
🎯 应用场景
INSPO框架可应用于各种需要多轮交互和工具集成的Agent任务,例如智能客服、任务型对话系统、自动化代码生成等。通过动态优化指令,可以提升Agent的推理能力和任务完成效率,使其能够更好地适应复杂多变的环境。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capability of large language models (LLMs), enabling autonomous agents that can conduct effective multi-turn and tool-integrated reasoning. While instructions serve as the primary protocol for defining agents, RLVR typically relies on static and manually designed instructions. However, those instructions may be suboptimal for the base model, and the optimal instruction may change as the agent's policy improves and explores the interaction with the environment. To bridge the gap, we introduce INSPO, a novel Instruction-Policy co-evolution framework that integrates instruction optimization as a dynamic component of the reinforcement learning (RL) loop. INSPO maintains a dynamic population of instruction candidates that are sampled with questions, where reward signals in RL loops are automatically attributed to each instruction, and low performers are periodically pruned. New instructions are generated and verified through an on-policy reflection mechanism, where an LLM-based optimizer analyzes past experience from a replay buffer and evolves more effective strategies given the current policy. We conduct extensive experiments on multi-turn retrieval and reasoning tasks, demonstrating that INSPO substantially outperforms strong baselines relying on static instructions. INSPO discovers innovative instructions that guide the agent toward more strategic reasoning paths, achieving substantial performance gains with only a marginal increase in computational overhead.