Zero-Overhead Introspection for Adaptive Test-Time Compute
作者: Rohin Manvi, Joey Hong, Tim Seyde, Maxime Labonne, Mathias Lechner, Sergey Levine
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-01 (更新: 2025-12-23)
💡 一句话要点
ZIP-RC:为LLM配备零开销自省能力,实现自适应测试时计算。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自省 大型语言模型 自适应推理 零开销 奖励预测
📋 核心要点
- 现有LLM缺乏自省能力,无法根据自身状态调整计算资源,导致效率低下和可信度问题。
- ZIP-RC通过重用模型logits,在不增加额外开销的情况下,预测奖励和剩余计算量,实现自省。
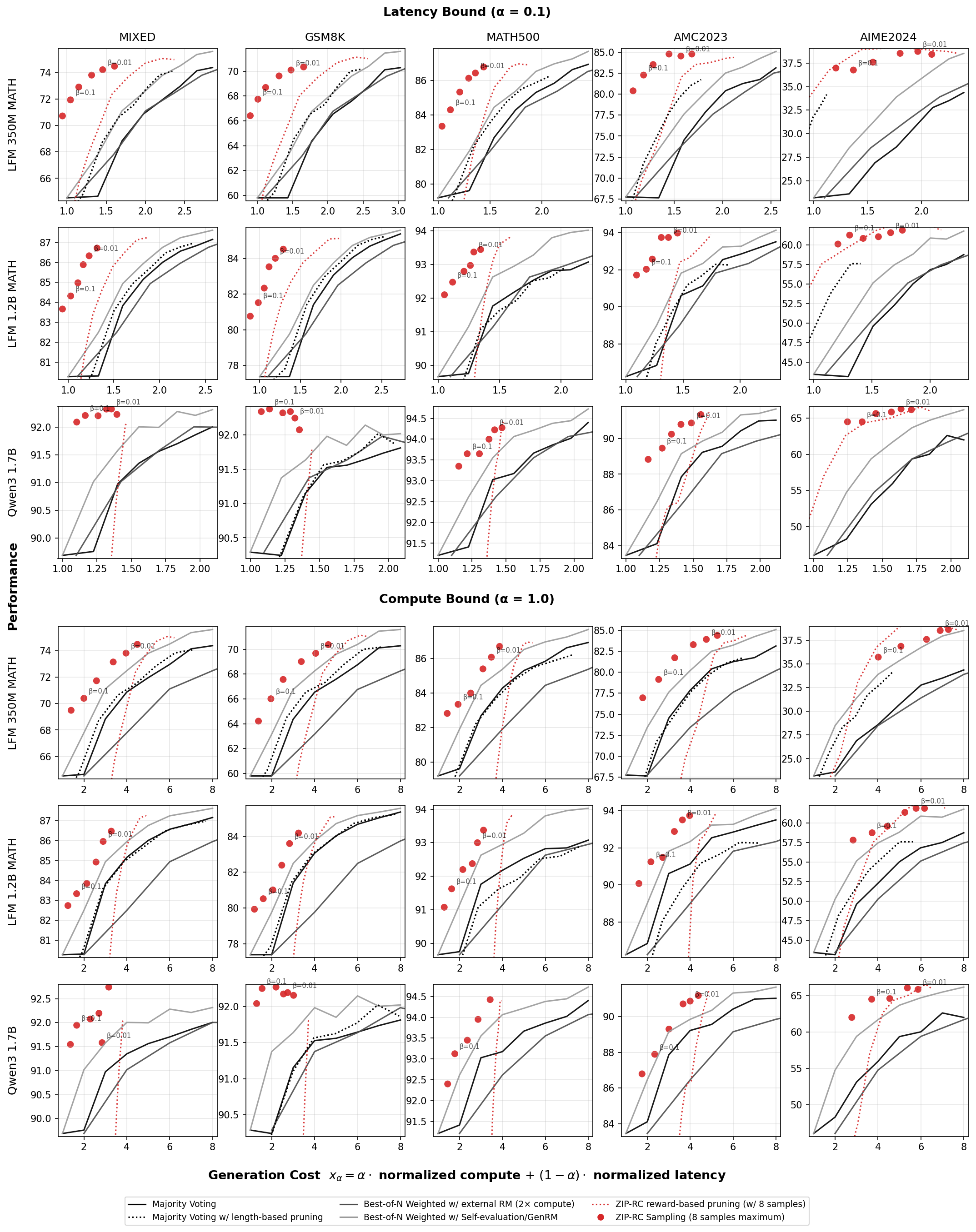
- 实验表明,ZIP-RC在数学基准测试中,以更低的成本实现了更高的准确率,并优化了质量、计算和延迟之间的平衡。
📝 摘要(中文)
大型语言模型(LLM)在推理方面表现出色,但缺乏关键的自省能力,包括预测自身成功的能力以及实现成功所需的计算量。人类利用实时自省来决定投入多少精力、何时进行多次尝试、何时停止以及何时发出成功或失败的信号。缺乏这些能力,LLM难以做出智能的元认知决策。测试时扩展方法(如Best-of-N)通过使用固定的样本预算来增加成本和延迟,而忽略了每次生成时边际效益。此外,缺乏置信度信号可能会误导用户,阻碍升级到更好的工具,并损害可信度。学习到的验证器或奖励模型可以提供置信度估计,但无法实现自适应推理,并且需要额外的模型或前向传递,从而增加了大量成本。我们提出了ZIP-RC,它使模型具备零开销的奖励和成本自省预测能力。在每个token处,ZIP-RC重用与下一个token预测相同的正向传递中保留或未使用的logits,以输出最终奖励和剩余长度的联合分布——无需额外的模型、架构更改或推理开销。这个完整的联合分布用于计算抽样效用,它是预期最大奖励、总计算量和如果生成到完成的一组样本的延迟的线性组合。在推理过程中,我们通过元动作来最大化这种效用,这些元动作决定了继续或开始从中抽样的token前缀。在混合难度的数学基准测试中,ZIP-RC在相同或更低的平均成本下,比多数投票提高了高达12%的准确率,并在质量、计算和延迟之间追踪平滑的帕累托前沿。通过提供实时奖励-成本自省,ZIP-RC实现了自适应、高效的推理。
🔬 方法详解
问题定义:现有的大型语言模型在推理过程中,无法根据自身状态和任务难度动态调整计算资源。例如,Best-of-N方法采用固定数量的样本,忽略了每个样本的边际效益,导致计算资源的浪费。此外,缺乏置信度评估机制,使得模型难以判断何时需要更多计算或何时应该停止,影响了模型的效率和可信度。
核心思路:ZIP-RC的核心思路是在不增加额外计算开销的前提下,让模型具备自省能力,能够预测完成任务所需的计算量和预期获得的奖励。通过这种自省能力,模型可以根据任务的难度和自身的表现,动态调整计算资源,从而提高效率和准确率。
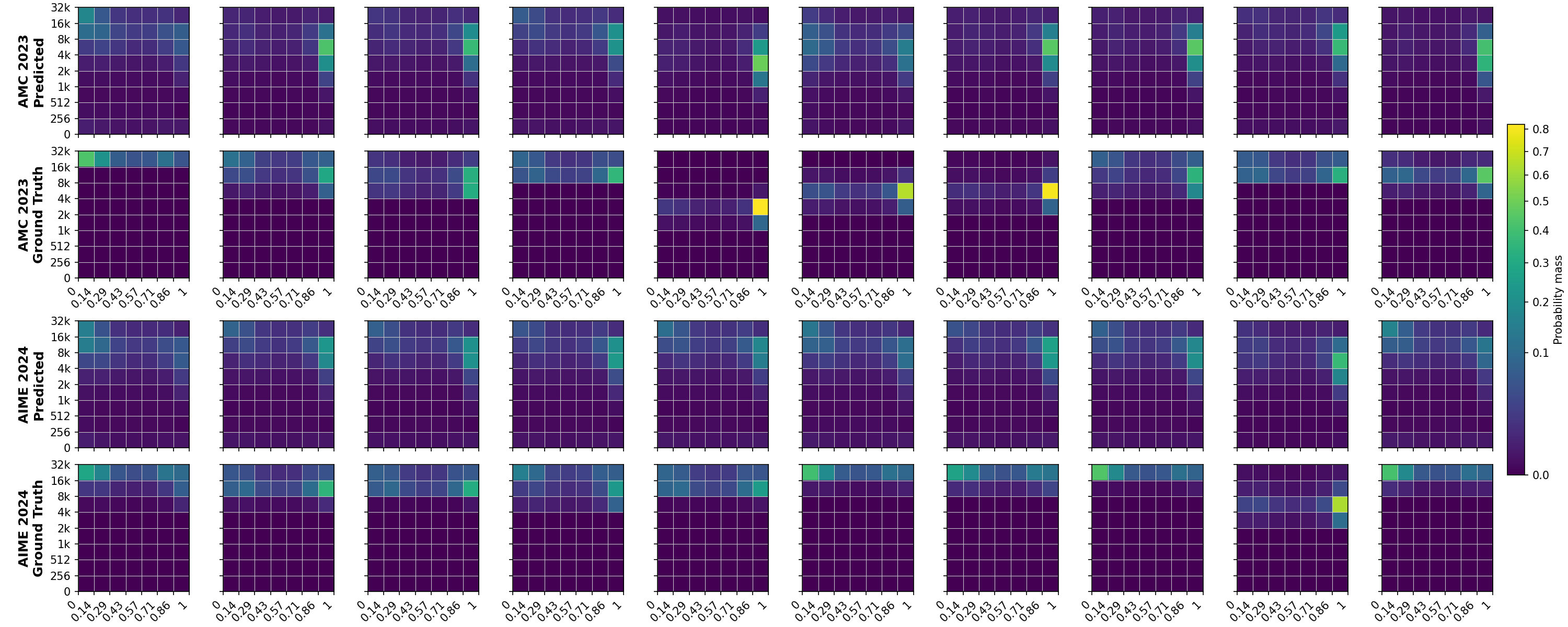
技术框架:ZIP-RC的技术框架主要包括以下几个部分:1) 利用模型生成token的logits,从中提取奖励和剩余长度的联合分布;2) 基于该联合分布,计算抽样效用,该效用是预期最大奖励、总计算量和延迟的线性组合;3) 使用元动作来最大化抽样效用,元动作决定了继续生成或重新抽样的token前缀。整个过程无需额外的模型或前向传递,实现了零开销的自省。
关键创新:ZIP-RC最重要的技术创新点在于其零开销的自省能力。与现有的方法(如学习验证器或奖励模型)相比,ZIP-RC不需要额外的模型或前向传递,从而避免了额外的计算开销。它通过重用模型logits,实现了对奖励和剩余长度的联合预测,从而为自适应推理提供了基础。
关键设计:ZIP-RC的关键设计包括:1) 如何从logits中提取奖励和剩余长度的联合分布;2) 如何定义抽样效用,以及如何平衡奖励、计算量和延迟之间的关系;3) 如何设计元动作,以便模型能够根据抽样效用动态调整生成策略。这些设计共同保证了ZIP-RC的有效性和效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ZIP-RC在混合难度的数学基准测试中,在相同或更低的平均成本下,比多数投票提高了高达12%的准确率。此外,ZIP-RC还能够在质量、计算和延迟之间追踪平滑的帕累托前沿,表明其能够有效地平衡不同目标,实现自适应推理。
🎯 应用场景
ZIP-RC可应用于各种需要高效推理和自适应计算的场景,例如智能客服、自动代码生成、机器人控制等。通过赋予模型自省能力,可以使其在资源受限的环境下更好地完成任务,提高用户体验和系统效率。未来,ZIP-RC有望成为提升LLM智能水平的重要技术。
📄 摘要(原文)
Large language models excel at reasoning but lack key aspects of introspection, including anticipating their own success and the computation required to achieve it. Humans use real-time introspection to decide how much effort to invest, when to make multiple attempts, when to stop, and when to signal success or failure. Without this, LLMs struggle to make intelligent meta-cognition decisions. Test-time scaling methods like Best-of-N drive up cost and latency by using a fixed budget of samples regardless of the marginal benefit of each one at any point in generation, and the absence of confidence signals can mislead people, prevent appropriate escalation to better tools, and undermine trustworthiness. Learned verifiers or reward models can provide confidence estimates, but do not enable adaptive inference and add substantial cost by requiring extra models or forward passes. We present ZIP-RC, which equips models with zero-overhead introspective predictions of reward and cost. At every token, ZIP-RC reuses reserved or unused logits in the same forward pass as next-token prediction to output a joint distribution over final reward and remaining length -- no extra models, architecture change, or inference overhead. This full joint distribution is used to compute a sampling utility which is the linear combination of the expected maximum reward, total compute, and latency of set of samples if generated to completion. During inference, we maximize this utility with meta-actions that determine which prefix of tokens to continue or initiate sampling from. On mixed-difficulty mathematical benchmarks, ZIP-RC improves accuracy by up to 12% over majority voting at equal or lower average cost, and traces smooth Pareto frontiers between quality, compute, and latency. By providing real-time reward-cost introspection, ZIP-RC enables adaptive, efficient reasoning.