Stabilizing Reinforcement Learning with LLMs: Formulation and Practices
作者: Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, An Yang, Jingren Zhou, Junyang Lin
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-01 (更新: 2025-12-03)
💡 一句话要点
提出基于LLM的强化学习新公式,解决训练不稳定问题并提供稳定训练方案。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 策略梯度 训练稳定性 重要性采样
📋 核心要点
- 现有基于LLM的强化学习方法在训练过程中存在不稳定性,难以有效优化序列级别奖励。
- 论文提出一种新公式,通过最小化训练-推理差异和策略陈旧性,使token级别目标能够有效优化序列级别奖励。
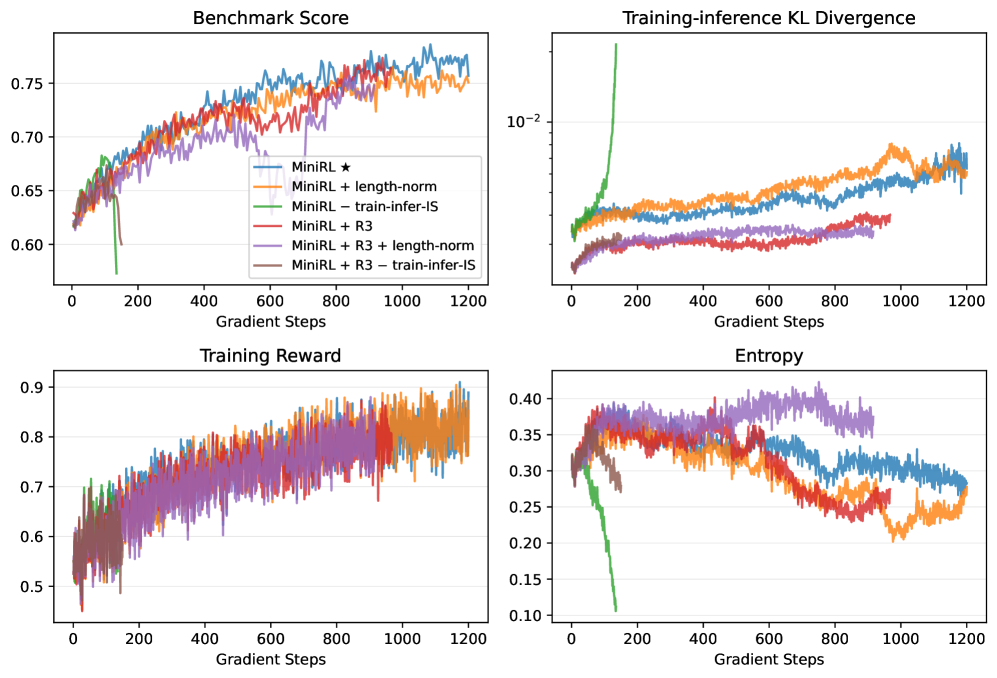
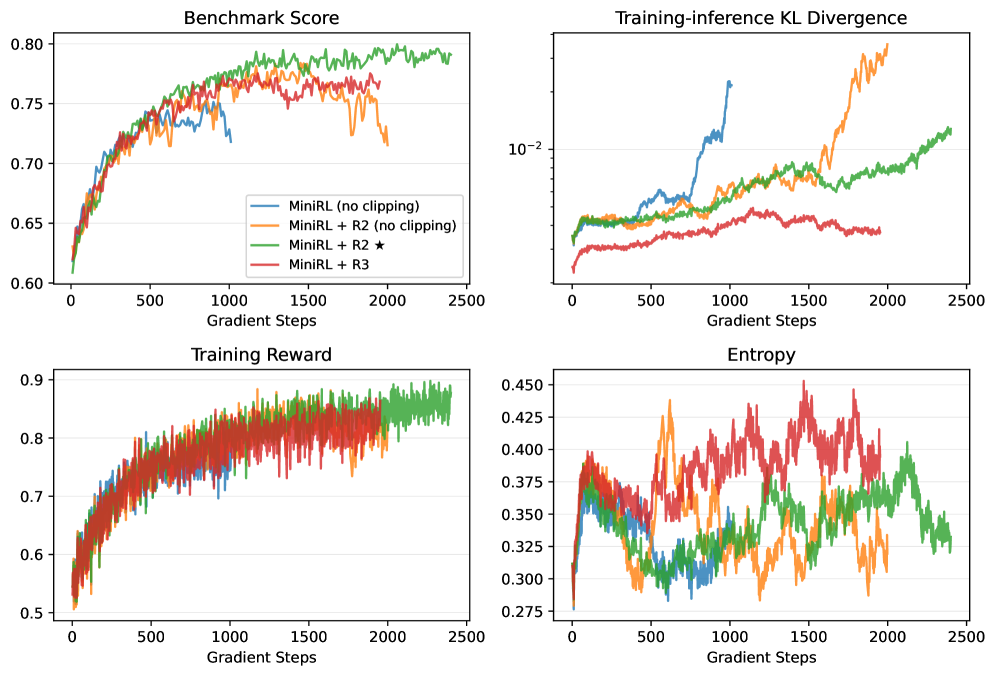
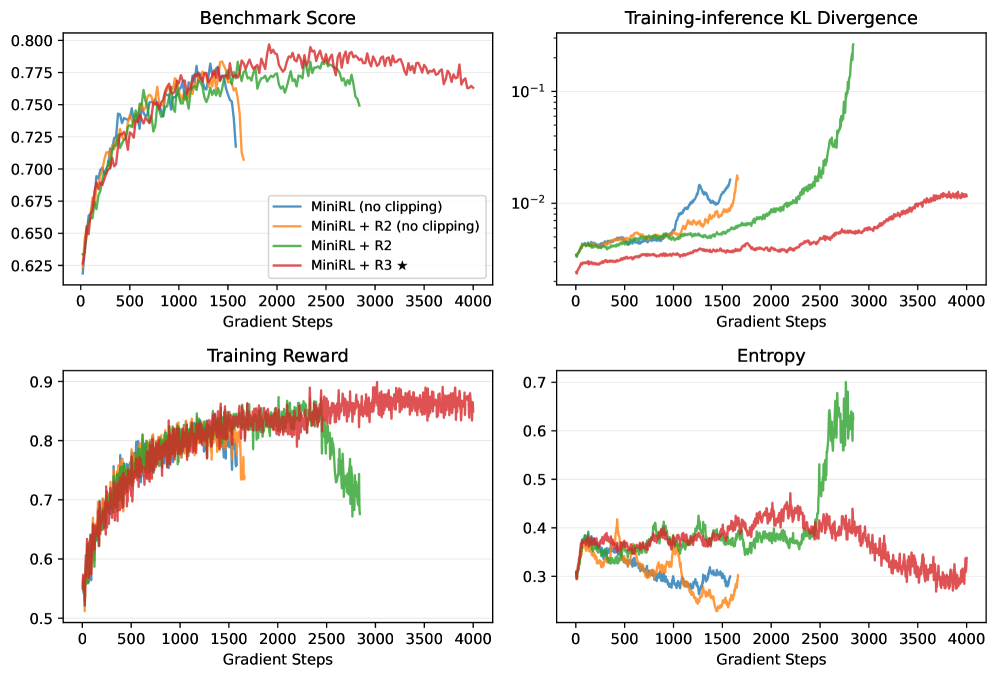
- 实验表明,重要性采样校正可实现最高的on-policy训练稳定性,而梯度裁剪和路由回放对off-policy训练至关重要。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的强化学习(RL)新公式,解释了在何种条件下,可以通过策略梯度方法(如REINFORCE)中的替代token级别目标来优化真实的序列级别奖励。具体而言,通过一阶近似,我们表明只有当训练-推理差异和策略陈旧性都被最小化时,这种替代方法才变得越来越有效。这一见解为稳定RL训练中广泛采用的几种技术的关键作用提供了有原则的解释,包括重要性采样校正、梯度裁剪,特别是用于混合专家(MoE)模型的路由回放。通过使用一个30B MoE模型进行的大量实验(总计数十万GPU小时),我们表明,对于on-policy训练,具有重要性采样校正的基本策略梯度算法实现了最高的训练稳定性。当引入off-policy更新以加速收敛时,结合梯度裁剪和路由回放对于减轻策略陈旧性引起的不稳定性至关重要。值得注意的是,一旦训练稳定下来,无论冷启动初始化如何,长时间的优化始终会产生相当的最终性能。我们希望共享的见解和开发的稳定RL训练方案将促进未来的研究。
🔬 方法详解
问题定义:现有基于LLM的强化学习方法在训练过程中面临不稳定性问题,导致难以有效优化序列级别的奖励目标。现有的策略梯度方法,如REINFORCE,通常使用token级别的目标函数作为序列级别奖励的替代,但这种替代的有效性缺乏理论支撑,容易导致训练崩溃。
核心思路:论文的核心思路是通过一阶近似来分析token级别目标函数与序列级别奖励之间的关系,揭示了训练-推理差异和策略陈旧性是导致训练不稳定的关键因素。通过最小化这两个因素,可以使token级别目标函数更准确地逼近序列级别奖励,从而稳定训练过程。
技术框架:整体框架基于标准的策略梯度强化学习算法,但特别关注如何稳定训练过程。主要模块包括:1) 使用LLM作为策略模型;2) 使用REINFORCE等策略梯度算法进行训练;3) 引入重要性采样校正来减少训练-推理差异;4) 使用梯度裁剪来限制策略更新幅度;5) 对于MoE模型,使用路由回放来缓解策略陈旧性。
关键创新:论文最重要的创新在于提出了一个理论框架,解释了为什么以及在什么条件下,可以使用token级别的目标函数来优化序列级别的奖励。该框架揭示了训练-推理差异和策略陈旧性是导致训练不稳定的关键因素,并为稳定训练提供了一个有原则的解释。
关键设计:关键设计包括:1) 使用重要性采样校正来减少训练-推理差异,通过校正训练数据分布与真实数据分布之间的差异来提高训练的稳定性;2) 使用梯度裁剪来限制策略更新幅度,防止策略突变导致训练崩溃;3) 对于MoE模型,使用路由回放来缓解策略陈旧性,通过重放旧的路由决策来稳定MoE模型的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,对于on-policy训练,具有重要性采样校正的基本策略梯度算法实现了最高的训练稳定性。当引入off-policy更新以加速收敛时,结合梯度裁剪和路由回放对于减轻策略陈旧性引起的不稳定性至关重要。值得注意的是,一旦训练稳定下来,无论冷启动初始化如何,长时间的优化始终会产生相当的最终性能。
🎯 应用场景
该研究成果可应用于各种需要使用LLM进行决策的强化学习任务,例如对话生成、文本摘要、代码生成等。通过稳定训练过程,可以提高LLM在这些任务中的性能和可靠性,使其能够更好地完成复杂的目标。
📄 摘要(原文)
This paper proposes a novel formulation for reinforcement learning (RL) with large language models, explaining why and under what conditions the true sequence-level reward can be optimized via a surrogate token-level objective in policy gradient methods such as REINFORCE. Specifically, through a first-order approximation, we show that this surrogate becomes increasingly valid only when both the training-inference discrepancy and policy staleness are minimized. This insight provides a principled explanation for the crucial role of several widely adopted techniques in stabilizing RL training, including importance sampling correction, clipping, and particularly Routing Replay for Mixture-of-Experts (MoE) models. Through extensive experiments with a 30B MoE model totaling hundreds of thousands of GPU hours, we show that for on-policy training, the basic policy gradient algorithm with importance sampling correction achieves the highest training stability. When off-policy updates are introduced to accelerate convergence, combining clipping and Routing Replay becomes essential to mitigate the instability caused by policy staleness. Notably, once training is stabilized, prolonged optimization consistently yields comparable final performance regardless of cold-start initialization. We hope that the shared insights and the developed recipes for stable RL training will facilitate future research.