LLM4XCE: Large Language Models for Extremely Large-Scale Massive MIMO Channel Estimation
作者: Renbin Li, Shuangshuang Li, Peihao Dong
分类: cs.LG, cs.AI
发布日期: 2025-11-28
💡 一句话要点
提出LLM4XCE,利用大语言模型解决超大规模MIMO信道估计难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超大规模MIMO 信道估计 大语言模型 语义通信 混合场信道
📋 核心要点
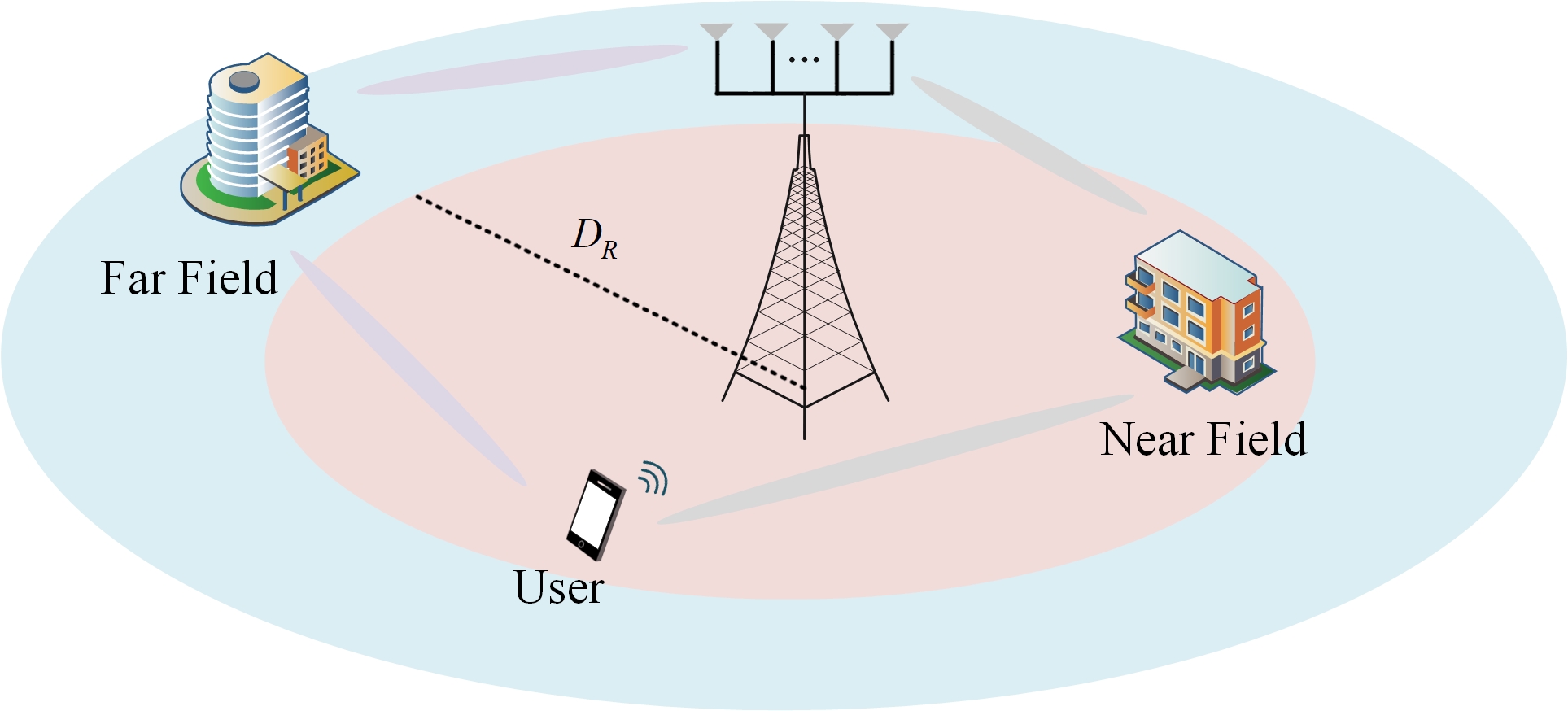
- 传统信道估计方法在XL-MIMO混合场条件下泛化能力不足,难以准确估计信道。
- LLM4XCE利用LLM的语义建模能力,通过学习信道的空间表示来提升估计精度。
- 实验表明,LLM4XCE在混合场条件下显著优于现有方法,提升了信道估计的精度和泛化能力。
📝 摘要(中文)
超大规模多输入多输出(XL-MIMO)是第六代(6G)网络的关键技术,它提供了巨大的空间自由度。然而,混合场信道中近场和远场效应的共存给精确估计带来了重大挑战,传统方法通常难以有效地泛化。近年来,大型语言模型(LLM)通过微调在下游任务上取得了令人印象深刻的性能,这与语义通信向面向任务的理解而非比特级精度的转变相一致。受此启发,我们提出了用于XL-MIMO信道估计的大型语言模型(LLM4XCE),这是一种新颖的信道估计框架,它利用大型语言模型的语义建模能力来恢复下游任务的基本空间信道表示。该模型集成了精心设计的嵌入模块与并行特征-空间注意力机制,能够深度融合导频特征和空间结构,从而为LLM输入构建语义丰富的表示。通过仅微调Transformer的顶部两层,我们的方法有效地捕获了导频数据中的潜在依赖关系,同时确保了高训练效率。大量的仿真表明,LLM4XCE在混合场条件下显著优于现有的最先进方法,实现了卓越的估计精度和泛化性能。
🔬 方法详解
问题定义:论文旨在解决超大规模MIMO系统中,由于近场和远场效应共存导致的信道估计难题。传统方法难以有效泛化到这种混合场环境,导致信道估计精度下降,影响通信性能。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语义建模能力,将信道估计问题转化为一个语义理解和推理的任务。通过学习信道的空间表示,LLM可以更好地捕捉信道中的复杂依赖关系,从而提高估计精度。
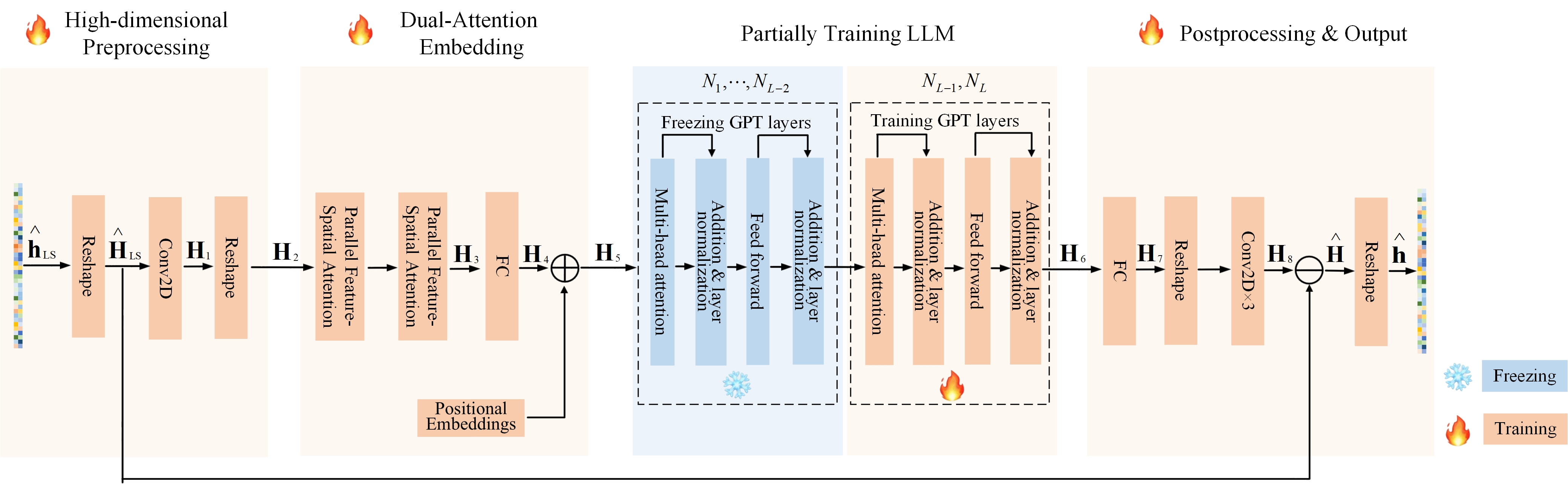
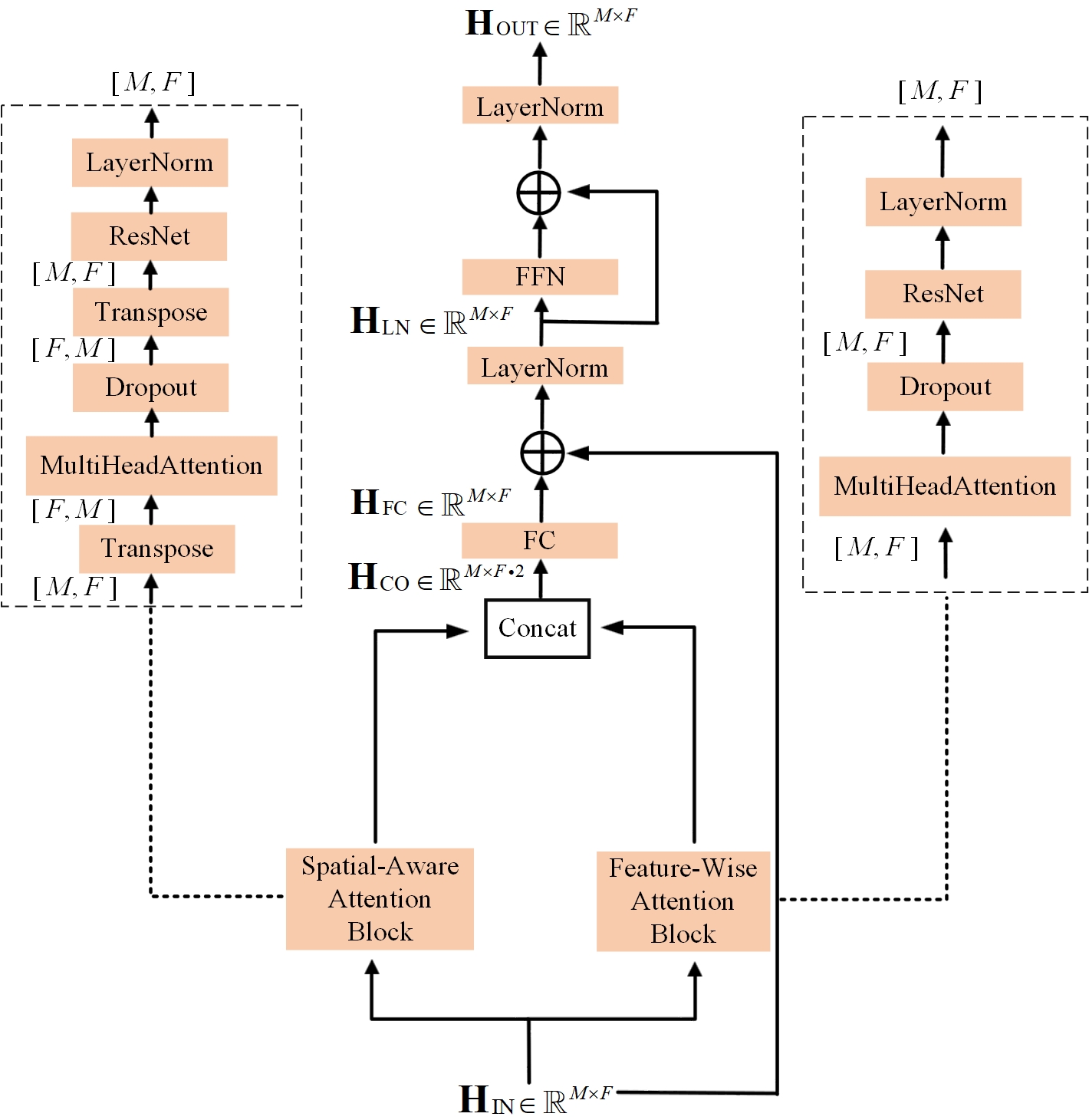
技术框架:LLM4XCE框架主要包含以下几个模块:1) 嵌入模块:用于将导频信号和空间信息编码成LLM可以理解的向量表示。2) 并行特征-空间注意力模块:用于深度融合导频特征和空间结构,构建语义丰富的表示。3) 微调的LLM:利用预训练的LLM,并通过微调顶部两层Transformer来适应信道估计任务。
关键创新:该方法最重要的创新在于将LLM引入到信道估计领域,利用LLM的语义建模能力来解决传统方法难以处理的混合场信道估计问题。与现有方法相比,LLM4XCE能够更好地捕捉信道中的复杂依赖关系,从而提高估计精度和泛化能力。
关键设计:关键设计包括:1) 精心设计的嵌入模块,用于将导频信号和空间信息编码成LLM可以理解的向量表示。2) 并行特征-空间注意力模块,用于深度融合导频特征和空间结构。3) 仅微调LLM的顶部两层Transformer,以保证训练效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM4XCE在混合场条件下显著优于现有最先进的信道估计方法。具体而言,LLM4XCE在信道估计精度和泛化性能方面均取得了显著提升,验证了该方法在解决超大规模MIMO信道估计难题方面的有效性。
🎯 应用场景
LLM4XCE可应用于6G无线通信系统中的超大规模MIMO信道估计,提升通信质量和系统容量。该方法在自动驾驶、虚拟现实等对通信质量要求高的场景中具有潜在应用价值。未来,该研究思路可以推广到其他无线通信场景,例如毫米波通信、太赫兹通信等。
📄 摘要(原文)
Extremely large-scale massive multiple-input multiple-output (XL-MIMO) is a key enabler for sixth-generation (6G) networks, offering massive spatial degrees of freedom. Despite these advantages, the coexistence of near-field and far-field effects in hybrid-field channels presents significant challenges for accurate estimation, where traditional methods often struggle to generalize effectively. In recent years, large language models (LLMs) have achieved impressive performance on downstream tasks via fine-tuning, aligning with the semantic communication shift toward task-oriented understanding over bit-level accuracy. Motivated by this, we propose Large Language Models for XL-MIMO Channel Estimation (LLM4XCE), a novel channel estimation framework that leverages the semantic modeling capabilities of large language models to recover essential spatial-channel representations for downstream tasks. The model integrates a carefully designed embedding module with Parallel Feature-Spatial Attention, enabling deep fusion of pilot features and spatial structures to construct a semantically rich representation for LLM input. By fine-tuning only the top two Transformer layers, our method effectively captures latent dependencies in the pilot data while ensuring high training efficiency. Extensive simulations demonstrate that LLM4XCE significantly outperforms existing state-of-the-art methods under hybrid-field conditions, achieving superior estimation accuracy and generalization performance.