ThetaEvolve: Test-time Learning on Open Problems
作者: Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, Yelong Shen
分类: cs.LG, cs.CL
发布日期: 2025-11-28
备注: 30 pages, link: https://github.com/ypwang61/ThetaEvolve
🔗 代码/项目: GITHUB
💡 一句话要点
ThetaEvolve:面向开放问题的测试时学习框架,实现持续进化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时学习 强化学习 开放优化问题 大型语言模型 持续进化
📋 核心要点
- 现有方法依赖闭源LLM集成,模型无法内化演化策略,限制了开放问题的解决。
- ThetaEvolve通过测试时学习,结合上下文学习和强化学习,使模型能从经验中持续进化。
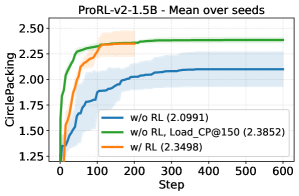
- 实验表明,ThetaEvolve能使小型开源模型在开放问题上达到新的最佳已知界限,并具备泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展推动了数学发现的突破,AlphaEvolve就是一个例子,它是一个闭源系统,通过进化程序来改进开放问题的界限。然而,它依赖于前沿LLM的集成来实现新的界限,并且是一个纯粹的推理系统,模型无法内化演化策略。我们介绍了ThetaEvolve,一个开源框架,它简化并扩展了AlphaEvolve,以在测试时有效地扩展上下文学习和强化学习(RL),允许模型不断从其改进开放优化问题的经验中学习。ThetaEvolve具有单个LLM、用于增强探索的大型程序数据库、用于更高吞吐量的批量采样、用于阻止停滞输出的惰性惩罚以及用于稳定训练信号的可选奖励塑造等功能。ThetaEvolve是第一个进化框架,使像DeepSeek-R1-0528-Qwen3-8B这样的小型开源模型能够在AlphaEvolve中提到的开放问题(圆形 packing 和第一自相关不等式)上实现新的已知最佳界限。此外,在两个模型和四个开放任务中,我们发现具有测试时RL的ThetaEvolve始终优于仅推理的基线,并且该模型确实学习了进化能力,因为经过RL训练的检查点在训练目标任务和其他未见任务上都表现出更快的进展和更好的最终性能。我们公开发布了我们的代码。
🔬 方法详解
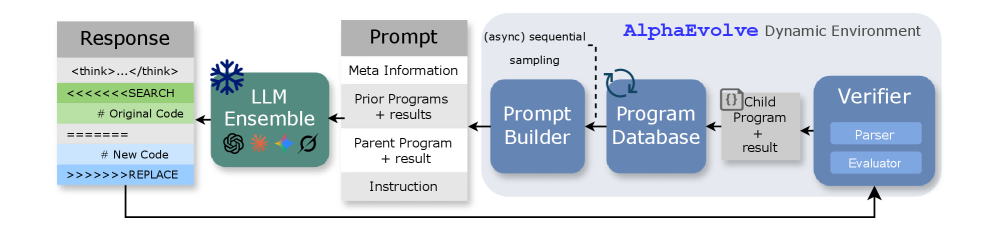
问题定义:论文旨在解决开放优化问题,例如圆形 packing 和第一自相关不等式。现有方法,如 AlphaEvolve,依赖于闭源的大型语言模型集成,计算成本高昂,且模型无法从经验中学习和进化,导致效率低下和泛化能力不足。
核心思路:ThetaEvolve 的核心思路是在测试时进行学习,通过结合上下文学习和强化学习,使模型能够从解决问题的过程中不断学习和进化。模型通过与环境交互,探索不同的解决方案,并根据反馈调整策略,从而逐步提高解决问题的能力。
技术框架:ThetaEvolve 的整体框架包括以下几个主要模块:1) 单个LLM:使用单个LLM作为核心推理引擎,降低计算成本。2) 大型程序数据库:存储已探索的程序,用于增强探索能力。3) 批量采样:提高吞吐量。4) 惰性惩罚:阻止模型输出停滞不前的结果。5) 可选奖励塑造:提供稳定的训练信号。在测试时,模型首先利用上下文学习初始化策略,然后通过强化学习不断优化策略,最终找到更好的解决方案。
关键创新:ThetaEvolve 的关键创新在于测试时学习框架,它允许模型在解决问题的过程中不断学习和进化。与传统的离线训练方法不同,ThetaEvolve 能够利用实际问题中的反馈信号,动态调整模型参数,从而提高解决问题的效率和泛化能力。此外,ThetaEvolve 使用单个LLM,降低了计算成本,使其更易于部署和使用。
关键设计:ThetaEvolve 的关键设计包括:1) 奖励函数的设计:奖励函数用于评估模型生成的程序的质量,并引导模型朝着更好的解决方案进化。论文中使用了奖励塑造技术,以提供更稳定和有效的训练信号。2) 探索策略:模型需要探索不同的程序,以找到更好的解决方案。论文中使用了大型程序数据库和批量采样技术,以增强探索能力。3) 惰性惩罚:为了避免模型生成停滞不前的结果,论文中引入了惰性惩罚,鼓励模型探索新的解决方案。
🖼️ 关键图片
📊 实验亮点
ThetaEvolve 使小型开源模型 DeepSeek-R1-0528-Qwen3-8B 在圆形 packing 和第一自相关不等式等开放问题上实现了新的已知最佳界限。在两个模型和四个开放任务中,具有测试时RL的ThetaEvolve始终优于仅推理的基线,证明了模型学习到了进化能力,且RL训练的检查点在训练目标任务和其他未见任务上都表现出更快的进展和更好的最终性能。
🎯 应用场景
ThetaEvolve 可应用于各种开放优化问题,例如数学发现、算法设计、科学研究等。通过持续进化,模型能够自动发现新的解决方案,提高解决问题的效率和质量。该框架具有广泛的应用前景,有望推动相关领域的发展。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled breakthroughs in mathematical discovery, exemplified by AlphaEvolve, a closed-source system that evolves programs to improve bounds on open problems. However, it relies on ensembles of frontier LLMs to achieve new bounds and is a pure inference system that models cannot internalize the evolving strategies. We introduce ThetaEvolve, an open-source framework that simplifies and extends AlphaEvolve to efficiently scale both in-context learning and Reinforcement Learning (RL) at test time, allowing models to continually learn from their experiences in improving open optimization problems. ThetaEvolve features a single LLM, a large program database for enhanced exploration, batch sampling for higher throughput, lazy penalties to discourage stagnant outputs, and optional reward shaping for stable training signals, etc. ThetaEvolve is the first evolving framework that enable a small open-source model, like DeepSeek-R1-0528-Qwen3-8B, to achieve new best-known bounds on open problems (circle packing and first auto-correlation inequality) mentioned in AlphaEvolve. Besides, across two models and four open tasks, we find that ThetaEvolve with RL at test-time consistently outperforms inference-only baselines, and the model indeed learns evolving capabilities, as the RL-trained checkpoints demonstrate faster progress and better final performance on both trained target task and other unseen tasks. We release our code publicly: https://github.com/ypwang61/ThetaEvolve