LFM2 Technical Report
作者: Alexander Amini, Anna Banaszak, Harold Benoit, Arthur Böök, Tarek Dakhran, Song Duong, Alfred Eng, Fernando Fernandes, Marc Härkönen, Anne Harrington, Ramin Hasani, Saniya Karwa, Yuri Khrustalev, Maxime Labonne, Mathias Lechner, Valentine Lechner, Simon Lee, Zetian Li, Noel Loo, Jacob Marks, Edoardo Mosca, Samuel J. Paech, Paul Pak, Rom N. Parnichkun, Alex Quach, Ryan Rogers, Daniela Rus, Nayan Saxena, Bettina Schlager, Tim Seyde, Jimmy T. H. Smith, Aditya Tadimeti, Neehal Tumma
分类: cs.LG, cs.AI
发布日期: 2025-11-28
💡 一句话要点
LFM2:面向边缘设备高效部署的Liquid Foundation Models,兼顾速度与性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 语言模型 模型压缩 知识蒸馏 硬件在环 多模态学习 低延迟推理
📋 核心要点
- 现有大模型在边缘设备部署面临延迟高、内存占用大的挑战,限制了其在资源受限场景的应用。
- LFM2通过硬件在环架构搜索,设计紧凑的混合骨干网络,结合门控短卷积和分组查询注意力,优化模型结构。
- LFM2系列模型在多个基准测试中表现出色,例如LFM2-2.6B在IFEval和GSM8K上分别达到79.56%和82.41%。
📝 摘要(中文)
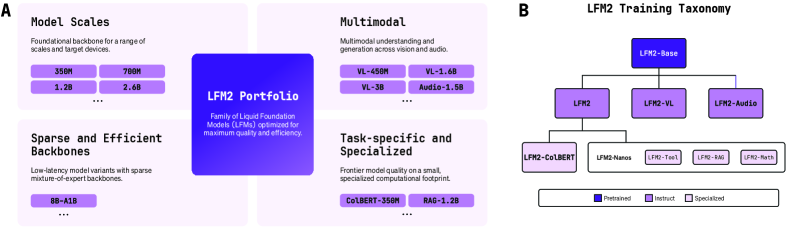
本文介绍了LFM2,一系列专为高效的设备端部署和强大的任务能力而设计的Liquid Foundation Models。通过在边缘延迟和内存约束下进行硬件在环架构搜索,我们获得了一个紧凑的混合骨干网络,它结合了门控短卷积和少量分组查询注意力块,与类似大小的模型相比,在CPU上实现了高达2倍的预填充和解码速度。LFM2系列涵盖3.5亿-83亿参数,包括稠密模型(3.5亿、7亿、12亿、26亿)和一个混合专家变体(总计83亿,激活15亿),所有模型都具有32K的上下文长度。LFM2的训练流程包括一个缓和的、解耦的Top-K知识蒸馏目标,避免了支持不匹配;具有难度排序数据的课程学习;以及一个由监督微调、长度归一化偏好优化和模型合并组成的三阶段后训练方案。LFM2模型经过10-12T tokens的预训练,在各种基准测试中取得了优异的成绩;例如,LFM2-2.6B在IFEval上达到了79.56%,在GSM8K上达到了82.41%。我们进一步构建了多模态和检索变体:用于视觉语言任务的LFM2-VL,用于语音的LFM2-Audio,以及用于检索的LFM2-ColBERT。LFM2-VL通过token高效的视觉处理支持可调的准确性-延迟权衡,而LFM2-Audio分离了音频输入和输出路径,以实现与大3倍的模型竞争的实时语音到语音交互。LFM2-ColBERT为查询和文档提供了一个低延迟编码器,从而实现了跨多种语言的高性能检索。所有模型都发布了开放权重和ExecuTorch、llama.cpp和vLLM的部署包,使LFM2成为需要快速、内存高效的推理和强大任务能力的边缘应用的实用基础。
🔬 方法详解
问题定义:现有的大型语言模型通常参数量巨大,计算复杂度高,难以在边缘设备上高效部署。边缘设备通常具有有限的计算资源和内存,因此需要更小、更快的模型。此外,如何在保持模型性能的同时,降低模型大小和推理延迟是一个关键挑战。
核心思路:LFM2的核心思路是通过硬件在环的架构搜索,在边缘设备的约束下,自动寻找最优的模型结构。这种方法能够充分利用硬件特性,优化模型在特定设备上的性能。此外,LFM2还采用了知识蒸馏、课程学习和后训练等技术,进一步提升模型性能。
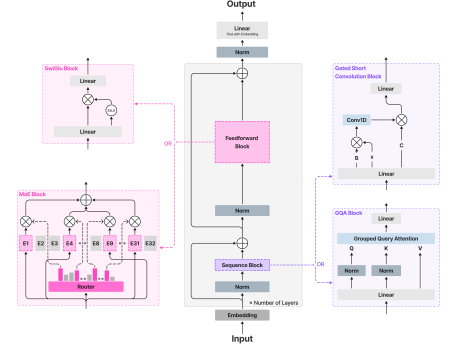
技术框架:LFM2的整体框架包括以下几个主要阶段:1) 硬件在环架构搜索:在边缘设备上进行模型结构的搜索,以优化延迟和内存占用。2) 模型训练:使用大规模数据集进行预训练,并采用知识蒸馏和课程学习等技术提升模型性能。3) 后训练:通过监督微调、长度归一化偏好优化和模型合并等技术,进一步优化模型在特定任务上的表现。4) 多模态扩展:构建视觉语言、语音和检索等变体,以支持更广泛的应用场景。
关键创新:LFM2的关键创新在于其硬件在环的架构搜索方法,该方法能够根据边缘设备的特性,自动优化模型结构,从而实现更高的效率。此外,LFM2还采用了缓和的、解耦的Top-K知识蒸馏目标,避免了支持不匹配的问题。
关键设计:LFM2的关键设计包括:1) 混合骨干网络:结合门控短卷积和分组查询注意力块,以实现高效的计算和信息传递。2) 缓和的、解耦的Top-K知识蒸馏目标:避免支持不匹配,提升蒸馏效果。3) 三阶段后训练方案:包括监督微调、长度归一化偏好优化和模型合并,以进一步优化模型性能。4) Token高效的视觉处理:在LFM2-VL中,采用token高效的视觉处理方法,以支持可调的准确性-延迟权衡。
🖼️ 关键图片
📊 实验亮点
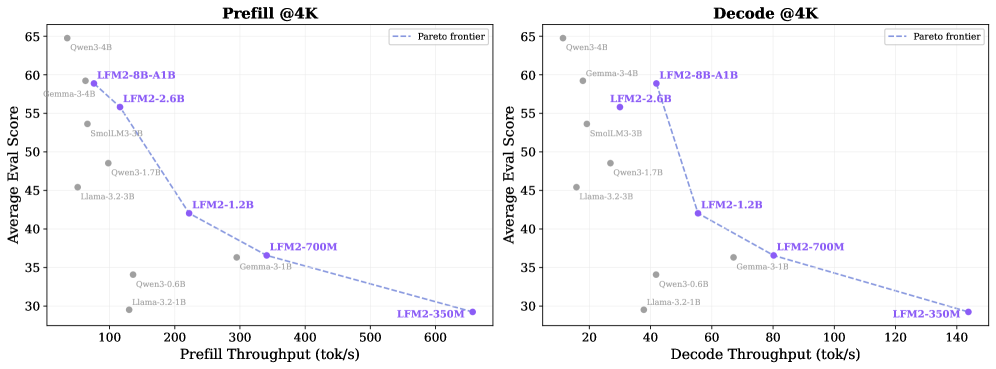
LFM2系列模型在多个基准测试中取得了优异的成绩。例如,LFM2-2.6B在IFEval上达到了79.56%,在GSM8K上达到了82.41%。与类似大小的模型相比,LFM2在CPU上实现了高达2倍的预填充和解码速度。LFM2-Audio在实时语音到语音交互方面,可以与大3倍的模型竞争。
🎯 应用场景
LFM2适用于各种边缘计算场景,例如智能手机、物联网设备和机器人等。它可以用于设备端的自然语言处理、语音识别、图像识别和检索等任务。LFM2的低延迟和高效率使其能够支持实时应用,例如语音助手、智能客服和实时翻译等。未来,LFM2有望成为边缘智能的重要基础设施。
📄 摘要(原文)
We present LFM2, a family of Liquid Foundation Models designed for efficient on-device deployment and strong task capabilities. Using hardware-in-the-loop architecture search under edge latency and memory constraints, we obtain a compact hybrid backbone that combines gated short convolutions with a small number of grouped query attention blocks, delivering up to 2x faster prefill and decode on CPUs compared to similarly sized models. The LFM2 family covers 350M-8.3B parameters, including dense models (350M, 700M, 1.2B, 2.6B) and a mixture-of-experts variant (8.3B total, 1.5B active), all with 32K context length. LFM2's training pipeline includes a tempered, decoupled Top-K knowledge distillation objective that avoids support mismatch; curriculum learning with difficulty-ordered data; and a three-stage post-training recipe of supervised fine-tuning, length-normalized preference optimization, and model merging. Pre-trained on 10-12T tokens, LFM2 models achieve strong results across diverse benchmarks; for example, LFM2-2.6B reaches 79.56% on IFEval and 82.41% on GSM8K. We further build multimodal and retrieval variants: LFM2-VL for vision-language tasks, LFM2-Audio for speech, and LFM2-ColBERT for retrieval. LFM2-VL supports tunable accuracy-latency tradeoffs via token-efficient visual processing, while LFM2-Audio separates audio input and output pathways to enable real-time speech-to-speech interaction competitive with models 3x larger. LFM2-ColBERT provides a low-latency encoder for queries and documents, enabling high-performance retrieval across multiple languages. All models are released with open weights and deployment packages for ExecuTorch, llama.cpp, and vLLM, making LFM2 a practical base for edge applications that need fast, memory-efficient inference and strong task capabilities.