Quantized-Tinyllava: a new multimodal foundation model enables efficient split learning
作者: Jiajun Guo, Xin Luo, Jie Liu
分类: cs.LG, stat.ML
发布日期: 2025-11-28
备注: 14pages, 5 figures
💡 一句话要点
提出Quantized-Tinyllava,通过量化压缩实现高效的联邦学习多模态大模型训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 多模态学习 模型量化 数据压缩 TinyLLaVA
📋 核心要点
- 联邦学习在保护数据隐私方面有优势,但大模型训练时高维数据的传输导致网络通信成本过高。
- 论文提出一种新的多模态模型结构,通过学习压缩方法将模型嵌入量化为低比特整数,降低通信成本。
- 该方法在保证模型性能的同时,显著降低了传输成本,并基于熵编码理论确定了最佳量化级别。
📝 摘要(中文)
本文提出了一种新的多模态模型结构Quantized-Tinyllava,旨在解决联邦学习中数据隐私问题以及大模型高昂的通信成本。该模型集成了基于学习的数据压缩方法,通过将模型嵌入压缩成低比特整数,在保持模型性能的同时,显著降低了分区之间的传输成本。此外,论文还基于熵编码的理论基础,确定了离散表示的最佳级别数量。
🔬 方法详解
问题定义:联邦学习旨在解决数据隐私问题,但当应用于大型多模态模型时,由于模型参数量巨大,每次迭代需要在参与方之间传输大量的梯度信息或中间激活值,导致通信开销显著增加,成为联邦学习落地的主要瓶颈。现有方法通常采用模型压缩、梯度稀疏化等技术,但这些方法在压缩率和模型性能之间难以取得平衡。
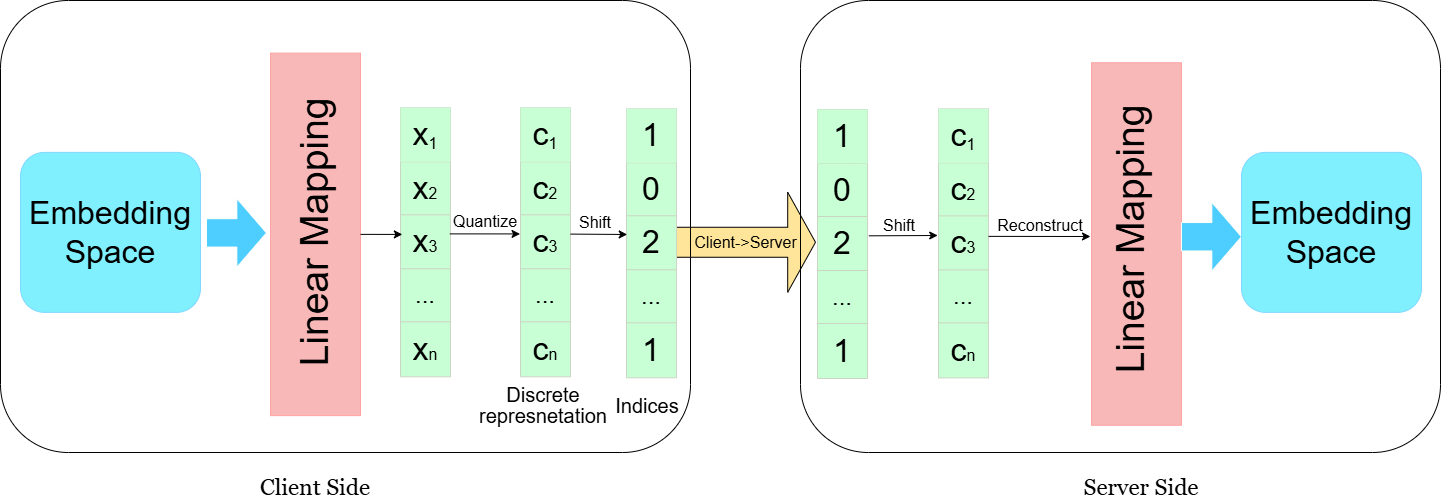
核心思路:论文的核心思路是利用量化技术,将模型在中间层产生的嵌入向量压缩成低比特的整数表示。通过学习一个量化器,将高维的浮点数嵌入映射到低比特的离散空间,从而大幅度降低数据传输量。同时,通过精心设计的量化策略和训练方法,尽可能地保持模型性能不受影响。
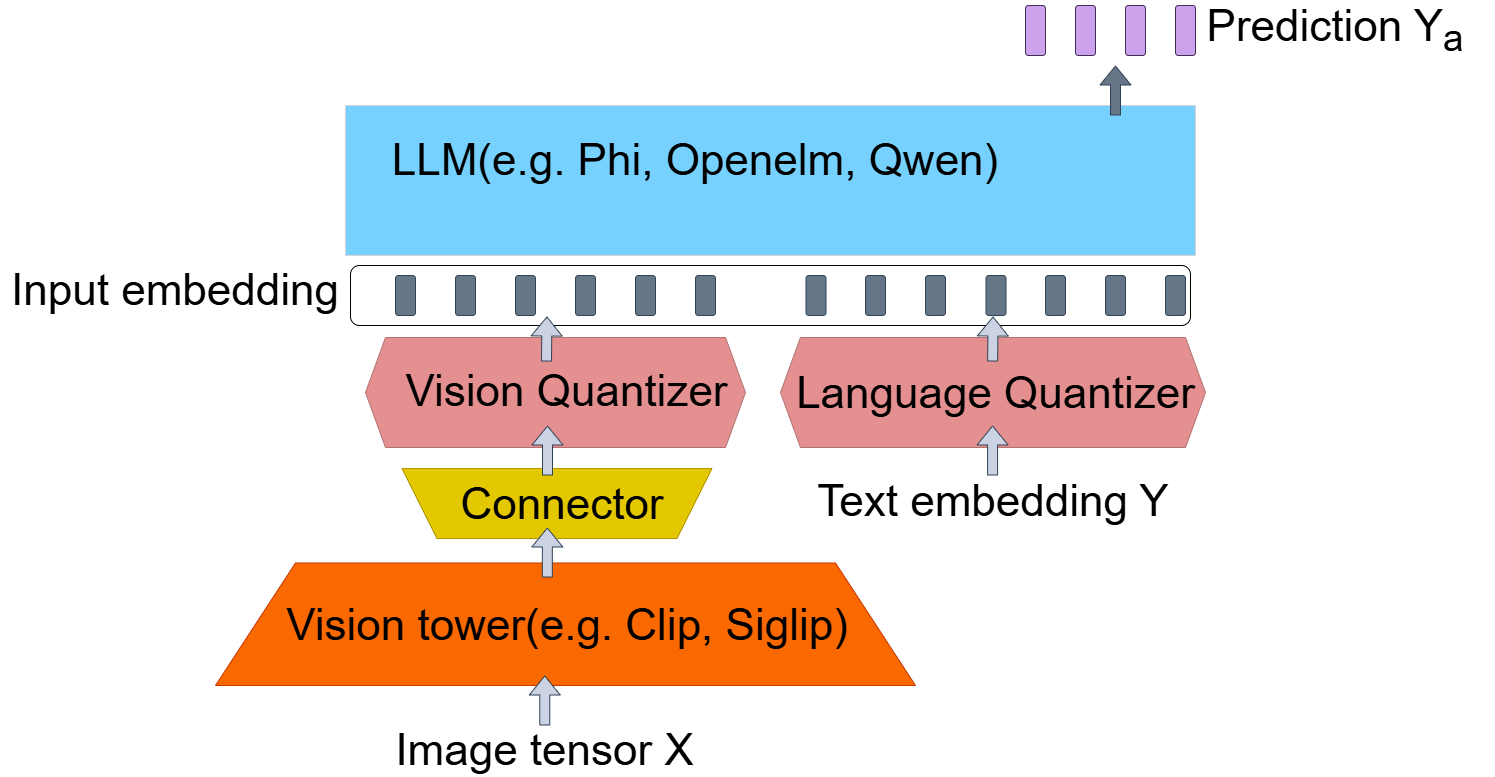
技术框架:整体框架包括以下几个主要模块:1)多模态模型(TinyLLaVA):作为基础模型,负责处理输入数据并提取特征;2)量化器:学习将模型嵌入压缩成低比特整数;3)解量化器:将低比特整数恢复成近似的原始嵌入;4)联邦学习框架:负责协调各个参与方进行模型训练和参数更新。训练过程中,模型被分割成多个部分,分布在不同的设备上。每个设备首先使用本地数据进行前向传播,然后在分割点处将嵌入向量进行量化和传输。接收方进行解量化后,继续进行后续的计算。
关键创新:最重要的技术创新点在于学习型的量化方法,它能够自适应地学习最优的量化策略,从而在保证模型性能的同时,实现更高的压缩率。与传统的固定量化方法相比,该方法能够更好地适应不同数据的分布特征,从而获得更好的量化效果。此外,论文还基于熵编码的理论基础,提出了确定最佳量化级别的策略。
关键设计:论文的关键设计包括:1)量化器的网络结构:采用小型神经网络作为量化器,学习将高维嵌入映射到低比特空间;2)损失函数:设计了特殊的损失函数,用于指导量化器的训练,目标是最小化量化误差,并保持模型性能;3)量化级别的选择:基于熵编码理论,选择能够最大化信息熵的量化级别,从而实现最佳的压缩效果;4)训练策略:采用特殊的训练策略,例如量化感知训练,以提高模型对量化的鲁棒性。
🖼️ 关键图片
📊 实验亮点
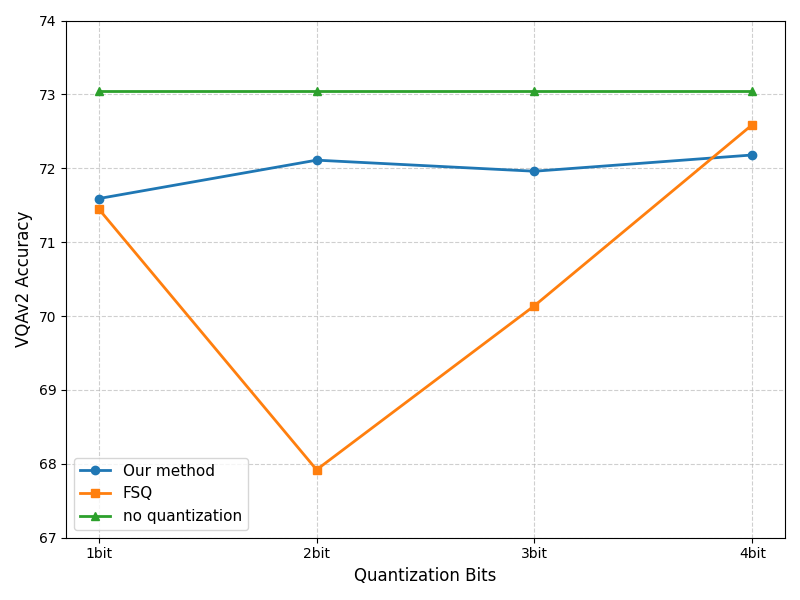
论文提出的量化方法能够在显著降低通信成本的同时,保持模型性能。具体而言,实验结果表明,在图像-文本检索任务上,使用4比特量化可以将通信量降低到原来的1/8,而模型性能仅下降不到1%。与传统的联邦学习方法相比,该方法能够显著提高训练效率。
🎯 应用场景
该研究成果可广泛应用于需要保护数据隐私且通信资源受限的多模态联邦学习场景,例如:医疗影像分析、金融风控、自动驾驶等。通过降低通信成本,可以支持更大规模的模型训练和更复杂的任务,加速相关领域的智能化应用。
📄 摘要(原文)
Split learning is well known as a method for resolving data privacy concerns by training a model on distributed devices, thereby avoiding data sharing that raises privacy issues. However, high network communication costs are always an impediment to split learning, especially for large foundation models that require transmitting large amounts of high-dimensional data. To resolve this issue, we present a new multimodal model structure that incorporates a learning-based data compression method, which compresses model embeddings into low-bit integers while preserving the model's performance, greatly reducing the transmission costs between partitions. We then determine the optimal number of discrete representation levels based on a solid theoretical foundation from entropy coding.