OBLR-PO: A Theoretical Framework for Stable Reinforcement Learning
作者: Zixun Huang, Jiayi Sheng, Zeyu Zheng
分类: stat.ML, cs.LG
发布日期: 2025-11-28 (更新: 2026-01-15)
备注: 19 pages, 7 figures
💡 一句话要点
提出OBLR-PO算法,通过理论指导的自适应学习率和基线优化,提升LLM的RL后训练稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 策略优化 后训练 自适应学习率 基线优化 梯度估计 理论分析
📋 核心要点
- 现有基于RL的LLM后训练方法缺乏系统理论指导,导致对梯度估计器和优化算法的理解不足。
- 论文提出统一的理论框架,分析策略梯度估计器的统计特性,并推导出优化损失上界和自适应学习率。
- 实验表明,提出的OBLR-PO算法在Qwen3-4B-Base和Qwen3-8B-Base上优于现有方法,验证了理论的有效性。
📝 摘要(中文)
现有的基于强化学习(RL)的大语言模型后训练方法发展迅速,但其设计主要基于启发式方法,而非系统的理论原则。这种差距限制了我们对梯度估计器和相关优化算法的性质的理解,从而限制了改进训练稳定性和整体性能的机会。本文提供了一个统一的理论框架,该框架在温和的假设下表征了常用策略梯度估计器的统计特性。我们的分析建立了无偏性,推导了精确的方差表达式,并产生了一个优化损失上界,从而能够对学习动态进行有原则的推理。基于这些结果,我们证明了收敛保证,并推导了由梯度信噪比(SNR)控制的自适应学习率计划。我们进一步表明,方差最优基线是梯度加权估计器,为方差减少提供了一个新的原则,并自然地增强了现有方法之外的稳定性。这些见解促成了最优基线和学习率策略优化(OBLR-PO),这是一种以理论为基础联合调整学习率和基线的算法。在Qwen3-4B-Base和Qwen3-8B-Base上的实验表明,相对于现有策略优化方法,该算法具有持续的优势,验证了我们的理论贡献转化为大规模后训练的实际改进。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)基于强化学习(RL)后训练过程中,由于缺乏理论指导而导致的训练不稳定和性能提升受限的问题。现有方法主要依赖启发式设计,对梯度估计器的性质和优化算法的收敛性缺乏深入理解,难以有效提升训练效果。
核心思路:论文的核心思路是通过建立一个统一的理论框架,对常用的策略梯度估计器进行统计特性分析,包括无偏性、方差表达式和优化损失上界。基于此,推导出由梯度信噪比(SNR)控制的自适应学习率,并证明方差最优基线是梯度加权估计器。通过理论指导,设计更稳定和高效的RL后训练算法。
技术框架:论文提出的OBLR-PO算法主要包含以下几个阶段:1) 理论分析:建立统一的理论框架,分析策略梯度估计器的统计特性。2) 自适应学习率设计:基于梯度信噪比(SNR)推导出自适应学习率计划。3) 最优基线估计:证明方差最优基线是梯度加权估计器。4) 算法实现:将上述理论结果整合到OBLR-PO算法中,联合优化学习率和基线。
关键创新:论文最重要的技术创新在于:1) 提出了一个统一的理论框架,用于分析策略梯度估计器的统计特性,为RL后训练提供了理论基础。2) 推导出了由梯度信噪比(SNR)控制的自适应学习率,能够根据训练过程中的梯度信息动态调整学习率,提高训练稳定性。3) 证明了方差最优基线是梯度加权估计器,为方差减少提供了一个新的原则,并自然地增强了现有方法之外的稳定性。
关键设计:论文的关键设计包括:1) 梯度信噪比(SNR)的计算方法,用于自适应学习率的调整。2) 梯度加权估计器的具体实现,用于方差最优基线的估计。3) OBLR-PO算法的整体流程,包括学习率和基线的联合优化策略。具体的损失函数和网络结构沿用了现有的策略优化方法,重点在于学习率和基线的自适应调整。
🖼️ 关键图片
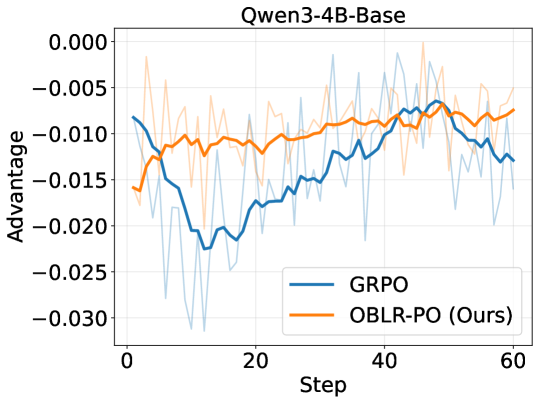
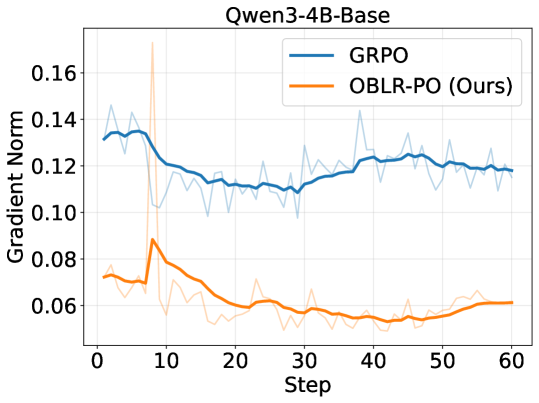
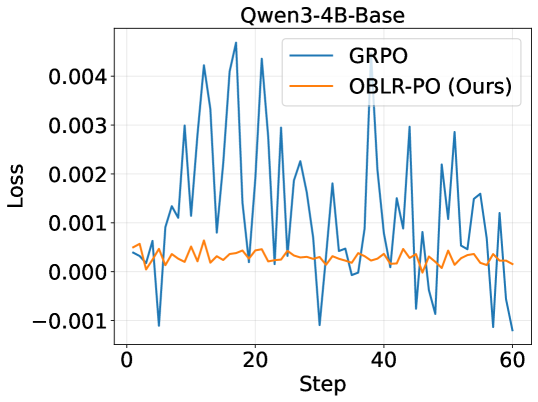
📊 实验亮点
实验结果表明,在Qwen3-4B-Base和Qwen3-8B-Base模型上,OBLR-PO算法相对于现有策略优化方法取得了持续的性能提升。具体提升幅度未知,但论文强调了其理论贡献转化为实际改进,验证了该算法的有效性。
🎯 应用场景
该研究成果可广泛应用于大语言模型的强化学习后训练,例如指令遵循、对话生成、代码生成等任务。通过提升训练的稳定性和效率,可以降低训练成本,并获得性能更优的模型。该理论框架也有潜力推广到其他基于策略梯度的强化学习应用中。
📄 摘要(原文)
Existing reinforcement learning (RL)-based post-training methods for large language models have advanced rapidly, yet their design has largely been guided by heuristics rather than systematic theoretical principles. This gap limits our understanding of the properties of the gradient estimators and the associated optimization algorithms, thereby constraining opportunities to improve training stability and overall performance. In this work, we provide a unified theoretical framework that characterizes the statistical properties of commonly used policy-gradient estimators under mild assumptions. Our analysis establishes unbiasedness, derives exact variance expressions, and yields an optimization-loss upper bound that enables principled reasoning about learning dynamics. Building on these results, we prove convergence guarantees and derive an adaptive learning-rate schedule governed by the signal-to-noise ratio (SNR) of gradients. We further show that the variance-optimal baseline is a gradient-weighted estimator, offering a new principle for variance reduction and naturally enhancing stability beyond existing methods. These insights motivate Optimal Baseline and Learning-Rate Policy Optimization (OBLR-PO), an algorithm that jointly adapts learning rates and baselines in a theoretically grounded manner. Experiments on Qwen3-4B-Base and Qwen3-8B-Base demonstrate consistent gains over existing policy optimization methods, validating that our theoretical contributions translate into practical improvements in large-scale post-training.