Transformer-Driven Triple Fusion Framework for Enhanced Multimodal Author Intent Classification in Low-Resource Bangla
作者: Ariful Islam, Tanvir Mahmud, Md Rifat Hossen
分类: cs.LG, cs.CL
发布日期: 2025-11-28
备注: Accepted at the 28th International Conference on Computer and Information Technology (ICCIT 2025). To be published in IEEE proceedings
💡 一句话要点
提出BangACMM框架,通过Transformer驱动的三重融合提升低资源孟加拉语作者意图分类。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 作者意图分类 多模态融合 Transformer 低资源语言 孟加拉语 中间融合 社交媒体分析
📋 核心要点
- 现有方法在孟加拉语等低资源场景下,作者意图分类精度不足,未能充分利用多模态信息。
- 提出BangACMM框架,采用Transformer驱动的三重融合策略,有效整合文本和视觉特征,提升分类性能。
- 实验表明,BangACMM在Uddessho数据集上实现了84.11%的宏F1分数,显著优于现有方法。
📝 摘要(中文)
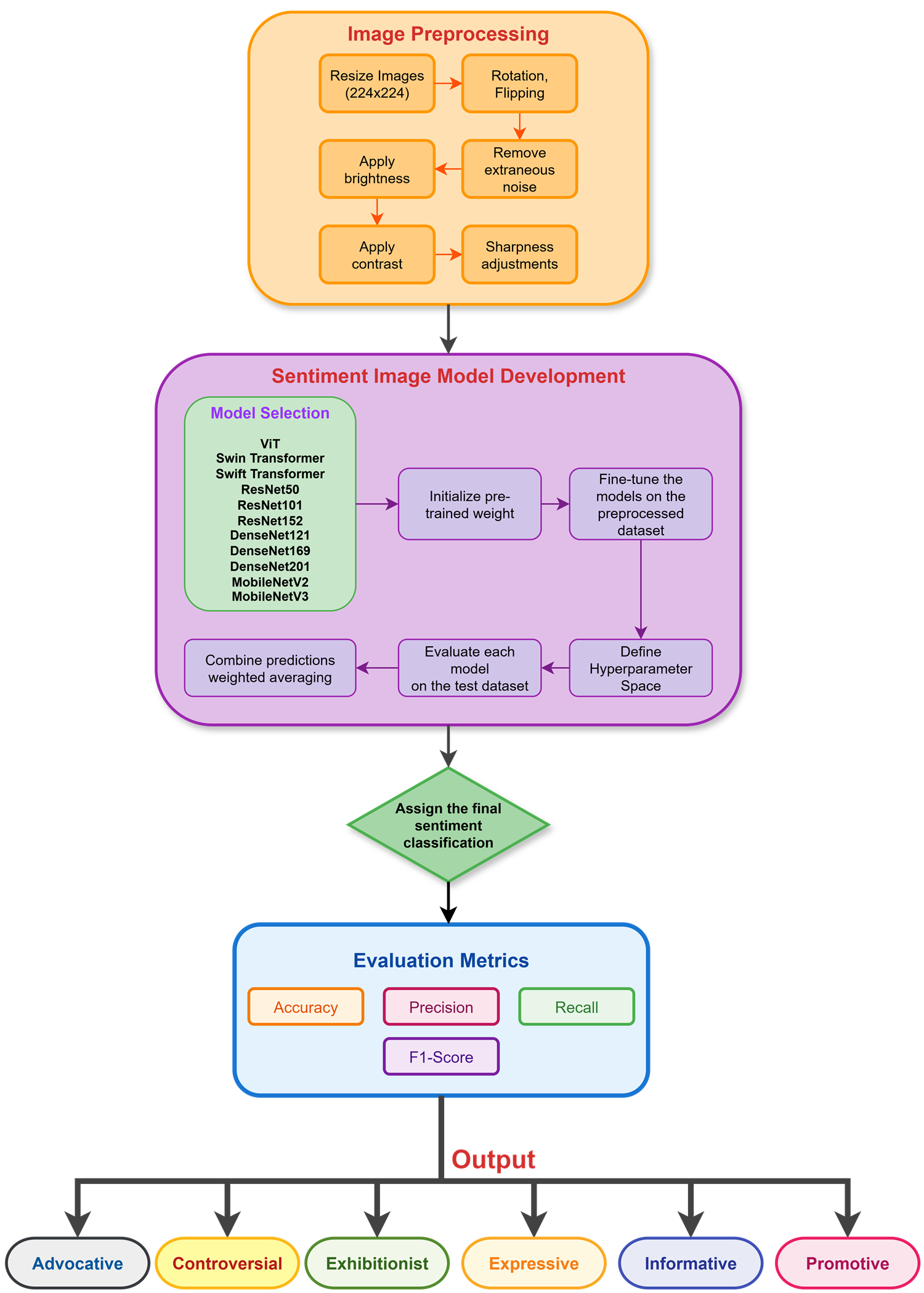
本文针对孟加拉语社交媒体帖子中的作者意图分类问题,利用文本和视觉数据。鉴于先前单模态方法的局限性,系统地评估了基于Transformer的语言模型(mBERT、DistilBERT、XLM-RoBERTa)和视觉架构(ViT、Swin、SwiftFormer、ResNet、DenseNet、MobileNet),使用了包含3048个帖子、涵盖六个实际意图类别的Uddessho数据集。提出了一种新颖的中间融合策略,该策略显著优于该任务上的早期和晚期融合。实验结果表明,中间融合,特别是与mBERT和Swin Transformer结合使用时,实现了84.11%的宏F1分数,与先前的孟加拉语多模态方法相比,提高了8.4个百分点,确立了新的state-of-the-art。分析表明,整合视觉上下文可以显著增强意图分类。中间层级的跨模态特征集成在模态特定表示和跨模态学习之间提供了最佳平衡。这项研究为孟加拉语和其他低资源语言建立了新的基准和方法标准。提出的框架命名为BangACMM(Bangla Author Content MultiModal)。
🔬 方法详解
问题定义:论文旨在解决低资源孟加拉语社交媒体内容中作者意图分类的问题。现有方法主要依赖于单模态信息,忽略了文本和视觉信息之间的互补性,导致分类精度不高。此外,直接应用在其他语言上表现良好的模型到孟加拉语上,效果往往不佳,需要针对该语言的特性进行优化。
核心思路:论文的核心思路是利用多模态融合,将文本和视觉信息结合起来,从而更准确地推断作者的意图。通过在中间层进行特征融合,可以更好地平衡模态特定表示和跨模态学习,从而获得更好的性能。同时,选择合适的Transformer模型和视觉模型,并进行有效的融合,是提升性能的关键。
技术框架:BangACMM框架包含以下几个主要模块:1) 文本编码器:使用预训练的Transformer模型(如mBERT、DistilBERT、XLM-RoBERTa)对文本信息进行编码。2) 视觉编码器:使用预训练的视觉模型(如ViT、Swin Transformer、ResNet等)对图像信息进行编码。3) 中间融合模块:将文本和视觉编码器的中间层特征进行融合。4) 分类器:使用融合后的特征进行作者意图分类。整体流程是,首先分别使用文本和视觉编码器提取特征,然后在中间层进行特征融合,最后使用分类器进行分类。
关键创新:论文的关键创新在于提出了中间融合策略。与传统的早期融合和晚期融合相比,中间融合可以在模态特定表示和跨模态学习之间取得更好的平衡。早期融合可能会丢失模态特定信息,而晚期融合则可能无法充分利用跨模态信息。中间融合通过在中间层进行特征融合,可以同时保留模态特定信息和利用跨模态信息。
关键设计:在中间融合模块中,论文使用了拼接(concatenation)操作将文本和视觉特征进行融合。具体来说,将文本编码器的某一层输出和视觉编码器的某一层输出进行拼接,然后输入到分类器中。论文还探索了不同的Transformer模型和视觉模型,并选择了mBERT和Swin Transformer作为最佳组合。损失函数使用了交叉熵损失函数,优化器使用了AdamW优化器。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BangACMM框架在Uddessho数据集上取得了显著的性能提升,宏F1分数达到了84.11%,与先前的孟加拉语多模态方法相比,提高了8.4个百分点,确立了新的state-of-the-art。中间融合策略被证明优于早期和晚期融合策略,mBERT和Swin Transformer的组合表现最佳。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过准确识别作者意图,可以过滤不良信息、了解用户情感倾向、提供个性化服务。对于孟加拉语等低资源语言,该研究具有重要的实际应用价值,有助于推动相关领域的发展。
📄 摘要(原文)
The expansion of the Internet and social networks has led to an explosion of user-generated content. Author intent understanding plays a crucial role in interpreting social media content. This paper addresses author intent classification in Bangla social media posts by leveraging both textual and visual data. Recognizing limitations in previous unimodal approaches, we systematically benchmark transformer-based language models (mBERT, DistilBERT, XLM-RoBERTa) and vision architectures (ViT, Swin, SwiftFormer, ResNet, DenseNet, MobileNet), utilizing the Uddessho dataset of 3,048 posts spanning six practical intent categories. We introduce a novel intermediate fusion strategy that significantly outperforms early and late fusion on this task. Experimental results show that intermediate fusion, particularly with mBERT and Swin Transformer, achieves 84.11% macro-F1 score, establishing a new state-of-the-art with an 8.4 percentage-point improvement over prior Bangla multimodal approaches. Our analysis demonstrates that integrating visual context substantially enhances intent classification. Cross-modal feature integration at intermediate levels provides optimal balance between modality-specific representation and cross-modal learning. This research establishes new benchmarks and methodological standards for Bangla and other low-resource languages. We call our proposed framework BangACMM (Bangla Author Content MultiModal).