PerfMamba: Performance Analysis and Pruning of Selective State Space Models
作者: Abdullah Al Asif, Mobina Kashaniyan, Sixing Yu, Juan Pablo Muñoz, Ali Jannesari
分类: cs.LG
发布日期: 2025-11-28
备注: Accepted in Bench 2025
💡 一句话要点
PerfMamba:通过性能分析和剪枝优化选择性状态空间模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 选择性状态空间模型 Mamba 性能分析 模型剪枝 序列建模 计算效率 内存优化
📋 核心要点
- 现有选择性SSM的运行时行为、资源利用和扩展性理解不足,限制了其优化部署和架构改进。
- 通过性能分析发现SSM组件是计算瓶颈,提出剪枝低活跃度状态的优化方法。
- 实验表明,该剪枝方法在保持精度的前提下,显著提升了吞吐量并降低了内存占用。
📝 摘要(中文)
序列建模的最新进展表明,选择性状态空间模型(SSM)是Transformer架构的有希望的替代方案,它在理论上具有计算效率和序列处理优势。然而,对于选择性SSM在运行时行为、资源利用模式和缩放特性方面的全面理解仍然未知,这阻碍了它们的最佳部署和进一步的架构改进。本文对Mamba-1和Mamba-2进行了全面的实证研究,系统地分析了它们的性能,以评估有助于其在状态空间建模中效率的设计原则。针对64到16384个token的序列长度,详细分析了计算模式、内存访问、I/O特性和缩放属性。研究结果表明,SSM组件作为选择性SSM架构的核心部分,与Mamba块中的其他组件相比,需要大量的计算资源。基于这些见解,我们提出了一种剪枝技术,选择性地移除SSM组件中低活跃度的状态,在适度的剪枝范围内实现可衡量的吞吐量和内存增益,同时保持准确性。这种方法在不同的序列长度上实现了性能提升,实现了1.14倍的加速,并将内存使用量减少了11.50%。这些结果为设计更高效的SSM架构提供了有价值的指导,这些架构可以应用于广泛的实际应用。
🔬 方法详解
问题定义:论文旨在解决选择性状态空间模型(SSM)在实际应用中效率不高的问题。现有方法缺乏对SSM内部计算瓶颈的深入理解,导致无法充分利用其潜力。具体来说,论文关注Mamba-1和Mamba-2模型,并试图通过优化其SSM组件来提高整体性能。
核心思路:论文的核心思路是通过性能分析识别SSM组件中的低活跃度状态,并对其进行剪枝。这种选择性剪枝旨在减少计算量和内存占用,同时尽可能保持模型的准确性。作者认为,并非所有状态都对模型的预测有同等贡献,因此可以安全地移除一些状态而不会显著影响性能。
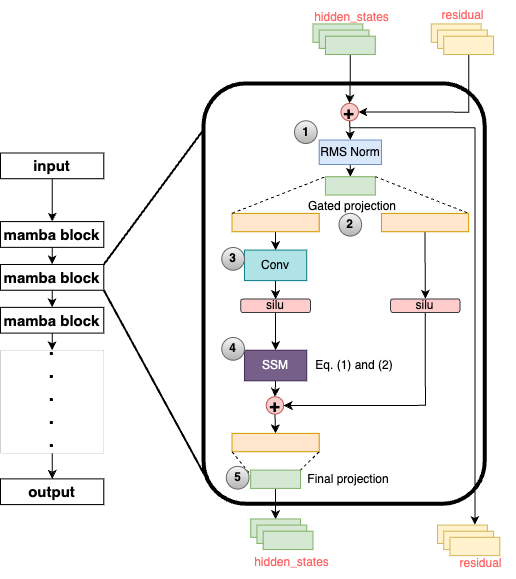
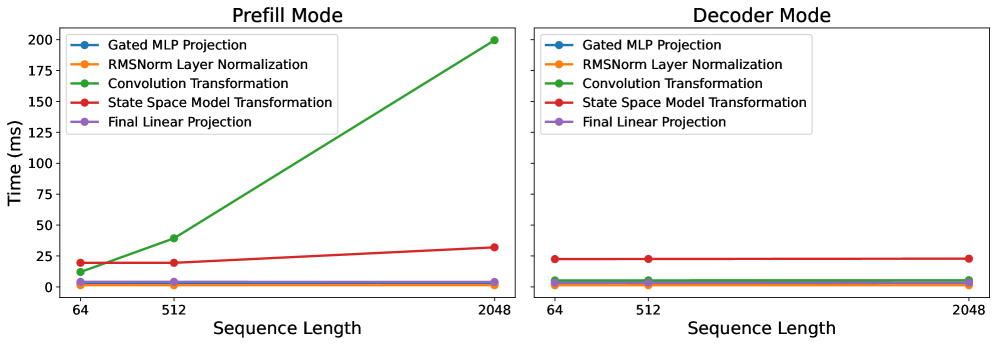
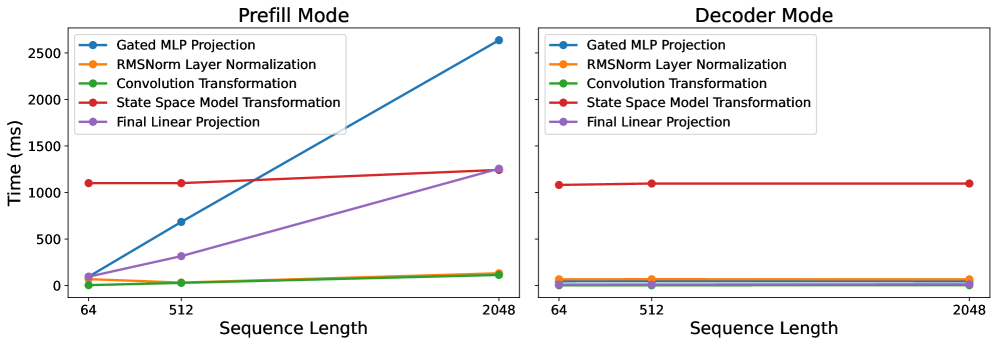
技术框架:论文首先对Mamba-1和Mamba-2进行详细的性能剖析,包括计算模式、内存访问和I/O特性。然后,基于性能分析的结果,提出了一种剪枝算法,该算法根据状态的活跃度选择性地移除状态。最后,通过实验评估剪枝后的模型在不同序列长度下的性能,包括吞吐量、内存占用和准确性。
关键创新:论文的关键创新在于提出了一种针对选择性SSM的剪枝方法,该方法能够有效地减少计算量和内存占用,同时保持模型的准确性。与传统的模型压缩方法不同,该方法专门针对SSM组件的特性进行设计,能够更有效地识别和移除冗余状态。
关键设计:论文的关键设计包括:1) 使用性能剖析工具来识别SSM组件中的计算瓶颈;2) 设计一种基于状态活跃度的剪枝算法,该算法能够选择性地移除低活跃度状态;3) 通过实验评估剪枝后的模型在不同序列长度下的性能,并与原始模型进行比较。具体的剪枝策略和阈值选择可能需要根据具体的模型和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的剪枝方法在不同的序列长度上实现了性能提升,实现了1.14倍的加速,并将内存使用量减少了11.50%。同时,该方法在适度的剪枝范围内保持了模型的准确性,表明其能够在提高效率的同时避免性能下降。这些结果验证了该方法的有效性,并表明其具有实际应用价值。
🎯 应用场景
该研究成果可应用于各种序列建模任务,例如自然语言处理、语音识别、时间序列预测等。通过优化选择性SSM的性能,可以使其在资源受限的环境中更易于部署,并能够处理更长的序列数据。此外,该研究还可以为设计更高效的SSM架构提供指导,从而推动序列建模领域的发展。
📄 摘要(原文)
Recent advances in sequence modeling have introduced selective SSMs as promising alternatives to Transformer architectures, offering theoretical computational efficiency and sequence processing advantages. A comprehensive understanding of selective SSMs in runtime behavior, resource utilization patterns, and scaling characteristics still remains unexplored, thus obstructing their optimal deployment and further architectural improvements. This paper presents a thorough empirical study of Mamba-1 and Mamba-2, systematically profiled for performance to assess the design principles that contribute to their efficiency in state-space modeling. A detailed analysis of computation patterns, memory access, I/O characteristics, and scaling properties was performed for sequence lengths ranging from 64 to 16384 tokens. Our findings show that the SSM component, a central part of the selective SSM architecture, demands a significant portion of computational resources compared to other components in the Mamba block. Based on these insights, we propose a pruning technique that selectively removes low-activity states within the SSM component, achieving measurable throughput and memory gains while maintaining accuracy within a moderate pruning regime. This approach results in performance improvements across varying sequence lengths, achieving a 1.14x speedup and reducing memory usage by 11.50\%. These results offer valuable guidance for designing more efficient SSM architectures that can be applied to a wide range of real-world applications.