Transformers with RL or SFT Provably Learn Sparse Boolean Functions, But Differently
作者: Bochen Lyu, Yiyang Jia, Xiaohao Cai, Zhanxing Zhu
分类: cs.LG, stat.ML
发布日期: 2025-11-22
备注: 43 pages, 5 figures
💡 一句话要点
理论分析:RL与SFT微调Transformer学习稀疏布尔函数的差异性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 强化学习 监督微调 思维链 稀疏布尔函数
📋 核心要点
- 现有研究缺乏对RL和SFT微调Transformer以获得CoT能力的理论理解,特别是二者机制上的差异。
- 本文通过分析学习$k$-稀疏布尔函数的Transformer,揭示了RL和SFT在学习CoT时的不同学习动态。
- 理论分析表明,RL同时学习整个CoT链,而SFT则按步骤学习,为理解CoT能力提供了理论基础。
📝 摘要(中文)
Transformer可以通过微调获得思维链(CoT)能力,从而解决复杂的推理任务。强化学习(RL)和监督微调(SFT)是实现这一目标的主要方法,但其潜在机制和差异在理论上尚不清楚。本文针对使用单层Transformer和类似于CoT的中间监督学习$k$-稀疏布尔函数,研究了这些方面。特别地,我们考虑可以递归分解为固定2-稀疏布尔函数的$k$-稀疏布尔函数。我们分析了通过RL或SFT与CoT微调Transformer的学习动态,以确定其可证明地学习这些函数的充分条件。我们验证了这些条件适用于三个基本示例,包括$k$-PARITY、$k$-AND和$k$-OR,从而证明了两种方法的可学习性。值得注意的是,我们揭示了RL和SFT表现出不同的学习行为:RL同时学习整个CoT链,而SFT逐步学习CoT链。总的来说,我们的发现为RL和SFT的潜在机制以及它们如何在Transformer中触发CoT能力提供了理论见解。
🔬 方法详解
问题定义:论文旨在从理论上理解RL和SFT两种微调方法,如何使Transformer获得Chain-of-Thought (CoT) 能力,特别是针对学习$k$-稀疏布尔函数这一特定任务。现有方法缺乏对这两种微调方式内在机制差异的深入理解,阻碍了CoT能力更有效的开发和应用。
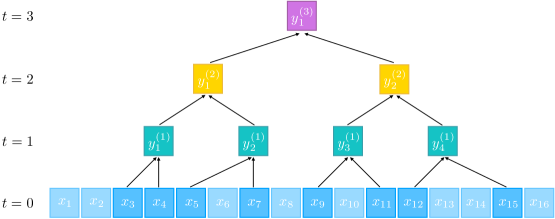
核心思路:论文的核心思路是通过分析Transformer学习$k$-稀疏布尔函数的动态过程,来揭示RL和SFT在学习CoT时的不同行为模式。具体而言,论文关注可以递归分解为2-稀疏布尔函数的$k$-稀疏布尔函数,并推导了两种微调方法成功学习这些函数的充分条件。这种分析方法能够将复杂的CoT学习问题简化为可控的理论模型,从而更容易进行分析。
技术框架:论文使用一个单层Transformer模型,并采用中间监督的方式,模拟CoT的过程。模型的输入是$k$-稀疏布尔函数的输入,输出是CoT的中间步骤和最终结果。论文分别分析了使用RL和SFT微调该Transformer模型的学习动态,推导了模型能够成功学习目标函数的充分条件。
关键创新:论文的关键创新在于揭示了RL和SFT在学习CoT时的本质区别:RL倾向于同时学习整个CoT链,而SFT则倾向于逐步学习CoT链。这一发现为理解这两种微调方法的优势和劣势提供了重要的理论依据。
关键设计:论文考虑了三种具体的$k$-稀疏布尔函数:$k$-PARITY、$k$-AND和$k$-OR。通过对这三种函数的分析,验证了理论推导的充分条件在实际情况下的有效性。论文还详细分析了RL和SFT在学习过程中的梯度变化和参数更新情况,从而更深入地理解了两种方法的学习动态。具体的参数设置和损失函数等技术细节在论文中进行了详细描述(此处未给出具体细节,请参考原文)。
🖼️ 关键图片

📊 实验亮点
论文通过理论分析证明了RL和SFT都可以使Transformer学习$k$-稀疏布尔函数,并揭示了二者在学习CoT时的不同行为模式。具体而言,RL同时学习整个CoT链,而SFT则按步骤学习。这些结论在$k$-PARITY、$k$-AND和$k$-OR三个基本示例上得到了验证,为理解RL和SFT微调Transformer的内在机制提供了重要的理论依据。
🎯 应用场景
该研究的理论发现有助于更好地理解和选择合适的微调方法(RL或SFT)来提升Transformer模型的推理能力。潜在的应用领域包括自然语言处理、知识图谱推理、以及需要复杂逻辑推理的各种人工智能任务。未来的研究可以基于这些理论见解,设计更有效的微调策略,从而提升模型的性能和泛化能力。
📄 摘要(原文)
Transformers can acquire Chain-of-Thought (CoT) capabilities to solve complex reasoning tasks through fine-tuning. Reinforcement learning (RL) and supervised fine-tuning (SFT) are two primary approaches to this end, yet their underlying mechanisms and differences remain theoretically unclear. In this work, we examine these aspects specifically for learning $k$-sparse Boolean functions with a one-layer transformer and intermediate supervision that is akin to CoT. In particular, we consider $k$-sparse Boolean functions that can be recursively decomposed into fixed 2-sparse Boolean functions. We analyze the learning dynamics of fine-tuning the transformer via either RL or SFT with CoT to identify sufficient conditions for it to provably learn these functions. We verify that these conditions hold for three basic examples, including $k$-PARITY, $k$-AND, and $k$-OR, thus demonstrating the learnability of both approaches. Notably, we reveal that RL and SFT exhibit distinct learning behaviors: RL learns the whole CoT chain simultaneously, whereas SFT learns the CoT chain step-by-step. Overall, our findings provide theoretical insights into the underlying mechanisms of RL and SFT as well as how they differ in triggering the CoT capabilities of transformers.