End-to-End Transformer Acceleration Through Processing-in-Memory Architectures
作者: Xiaoxuan Yang, Peilin Chen, Tergel Molom-Ochir, Yiran Chen
分类: cs.AR, cs.LG
发布日期: 2025-11-21
备注: ICM 2025
💡 一句话要点
提出基于存内计算架构的Transformer端到端加速方案,解决计算、访存和复杂度瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer加速 存内计算 键值缓存 注意力机制 低功耗 自然语言处理
📋 核心要点
- Transformer部署面临计算量大、访存频繁和注意力机制复杂度高等挑战。
- 利用存内计算重构Transformer,最小化片外数据传输,动态压缩KV缓存,并简化注意力计算。
- 实验表明,该存内计算设计在能效和延迟方面优于现有加速器和GPU。
📝 摘要(中文)
Transformer模型已成为自然语言处理和大型语言模型的核心,但其大规模部署面临三大挑战。首先,注意力机制需要大量的矩阵乘法和中间结果在内存和计算单元之间的频繁移动,导致高延迟和能量消耗。其次,在长上下文推理中,键值缓存(KV缓存)可能会不可预测地增长,甚至超过模型的权重大小,造成严重的内存和带宽瓶颈。第三,注意力机制相对于序列长度的二次复杂度放大了数据移动和计算开销,使得大规模推理效率低下。为了解决这些问题,本研究引入了存内计算解决方案,重构了注意力和前馈计算,以最大限度地减少片外数据传输,动态压缩和修剪KV缓存以管理内存增长,并将注意力重新解释为关联存储操作以降低复杂性和硬件占用。此外,我们针对最先进的加速器和通用GPU评估了我们的存内计算设计,证明了在能源效率和延迟方面的显著改进。总之,这些方法解决了计算开销、内存可扩展性和注意力复杂度,进一步实现了Transformer模型的高效端到端加速。
🔬 方法详解
问题定义:Transformer模型在自然语言处理任务中表现出色,但其大规模部署受限于计算开销、内存需求和注意力机制的复杂度。现有方法在处理长序列时,由于注意力机制的二次复杂度,导致计算量和内存访问量急剧增加,使得推理效率低下。此外,键值缓存(KV cache)的增长也带来了严重的内存瓶颈。
核心思路:论文的核心思路是利用存内计算(Processing-in-Memory, PIM)架构来解决Transformer模型的计算和访存瓶颈。通过将计算单元集成到内存中,可以显著减少数据在内存和计算单元之间的传输,从而降低延迟和功耗。此外,论文还提出了动态压缩和修剪KV缓存的方法,以减少内存占用。
技术框架:该方案主要包含三个关键部分:1) 基于PIM的注意力和前馈计算重构,旨在最小化片外数据传输;2) 动态KV缓存压缩和修剪,用于管理内存增长;3) 将注意力机制重新解释为关联存储操作,以降低计算复杂度和硬件占用。整体流程是将Transformer模型映射到PIM架构上,并利用提出的优化技术进行加速。
关键创新:论文的关键创新在于将存内计算应用于Transformer模型的加速,并结合了KV缓存压缩和注意力机制简化等多种优化策略。与传统的加速器设计相比,该方法能够更有效地利用内存带宽,并降低计算复杂度。将注意力机制视为关联存储操作也是一个重要的创新点,可以进一步降低硬件实现的复杂度。
关键设计:论文中关于PIM架构的具体设计细节未知,但可以推测其关键设计包括:1) 高带宽的内存接口,以支持大量数据的并行访问;2) 集成在内存中的计算单元,用于执行矩阵乘法和激活函数等操作;3) 动态KV缓存压缩和修剪算法,用于减少内存占用;4) 注意力机制的硬件实现,例如使用关联存储器来实现注意力计算。
🖼️ 关键图片
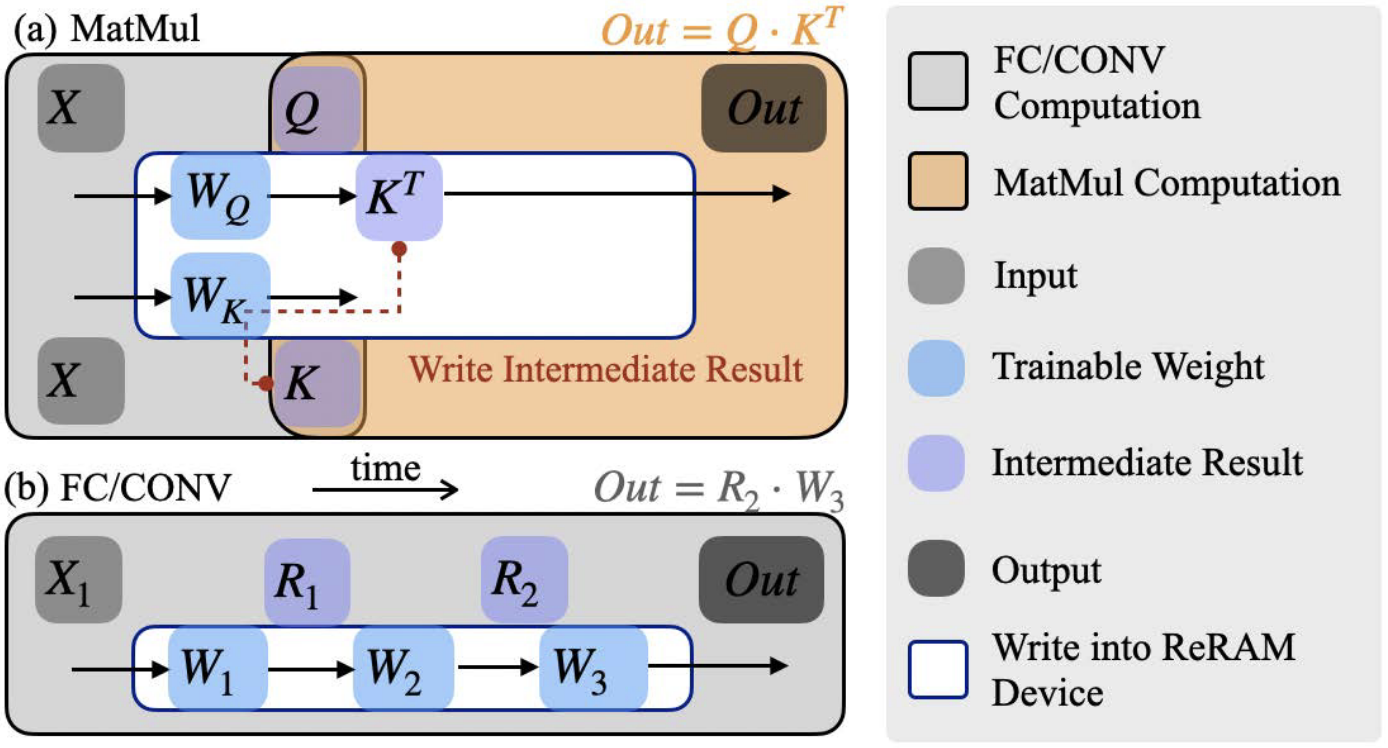
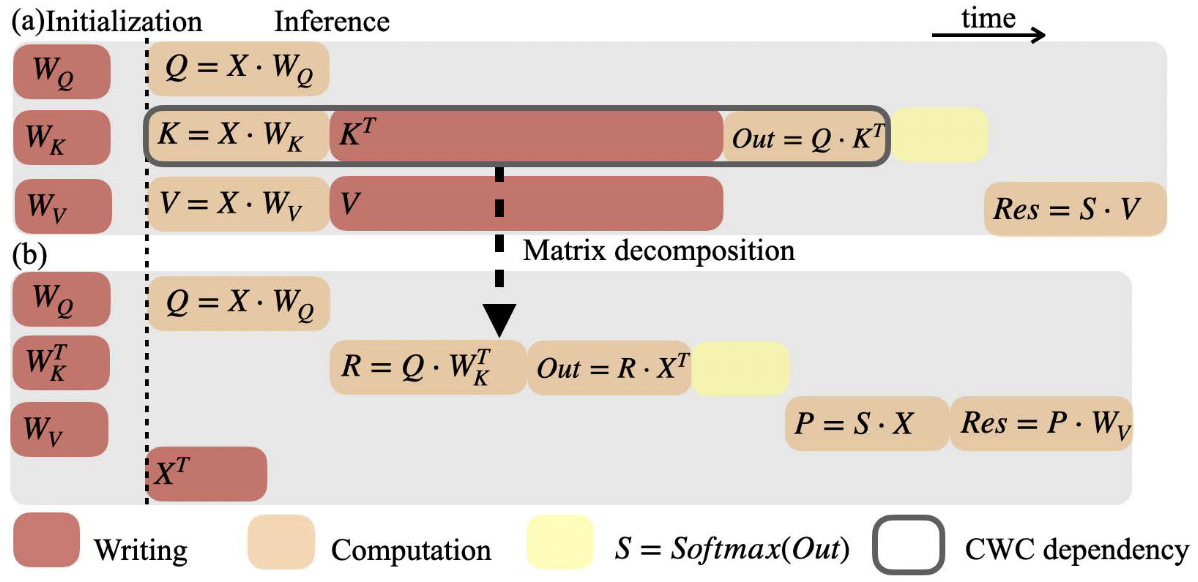
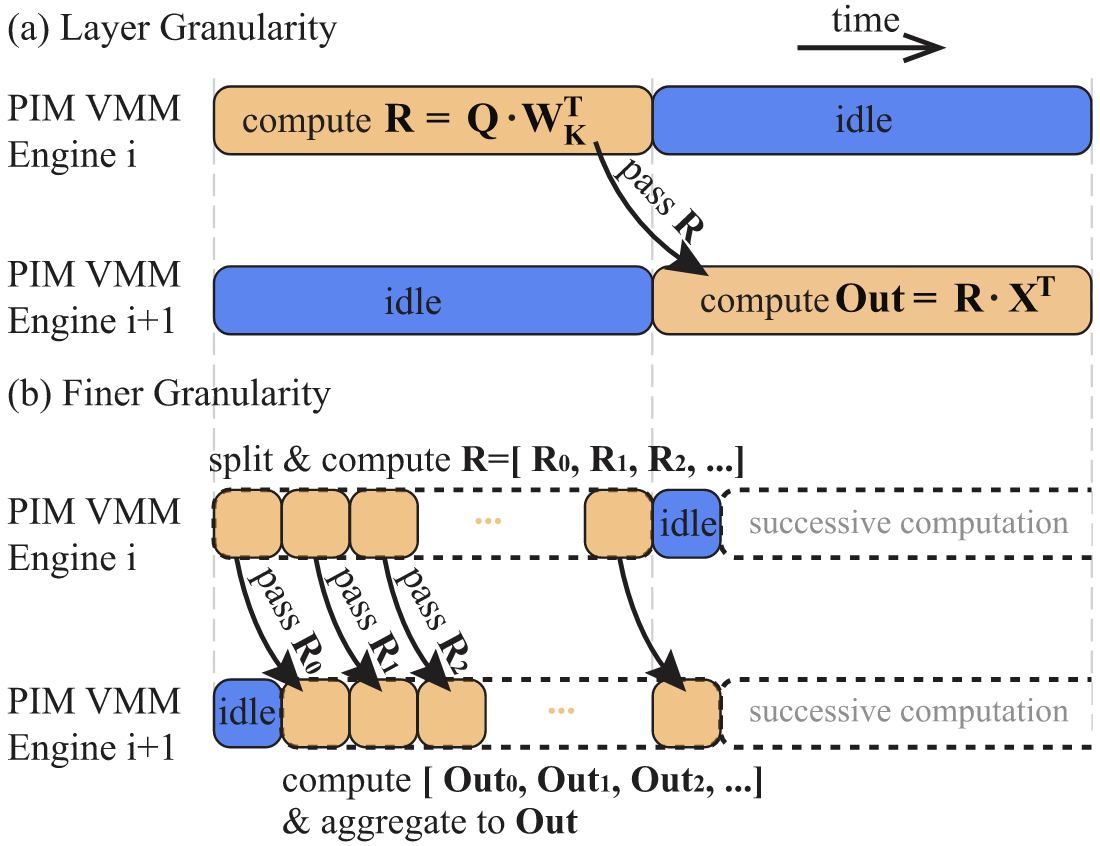
📊 实验亮点
论文通过实验验证了所提出的存内计算设计在能源效率和延迟方面的显著改进,但具体的性能数据和对比基线未知。可以推测,该设计在处理长序列时,能够显著降低延迟和功耗,并提高吞吐量。与传统的GPU和加速器相比,该方法在内存带宽利用率和计算效率方面具有优势。
🎯 应用场景
该研究成果可应用于各种需要高性能和低功耗的自然语言处理任务,例如:大规模语言模型推理、机器翻译、文本摘要、对话系统等。特别是在边缘设备和移动设备上部署Transformer模型时,该方法具有重要的应用价值,可以显著提高模型的推理速度和降低功耗,从而实现更高效的AI应用。
📄 摘要(原文)
Transformers have become central to natural language processing and large language models, but their deployment at scale faces three major challenges. First, the attention mechanism requires massive matrix multiplications and frequent movement of intermediate results between memory and compute units, leading to high latency and energy costs. Second, in long-context inference, the key-value cache (KV cache) can grow unpredictably and even surpass the model's weight size, creating severe memory and bandwidth bottlenecks. Third, the quadratic complexity of attention with respect to sequence length amplifies both data movement and compute overhead, making large-scale inference inefficient. To address these issues, this work introduces processing-in-memory solutions that restructure attention and feed-forward computation to minimize off-chip data transfers, dynamically compress and prune the KV cache to manage memory growth, and reinterpret attention as an associative memory operation to reduce complexity and hardware footprint. Moreover, we evaluate our processing-in-memory design against state-of-the-art accelerators and general-purpose GPUs, demonstrating significant improvements in energy efficiency and latency. Together, these approaches address computation overhead, memory scalability, and attention complexity, further enabling efficient, end-to-end acceleration of Transformer models.