Deterministic Inference across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch
作者: Ziyang Zhang, Xinheng Ding, Jiayi Yuan, Rixin Liu, Huizi Mao, Jiarong Xing, Zirui Liu
分类: cs.LG, cs.CL, stat.ML
发布日期: 2025-11-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出树形结构不变核TBIK,解决大模型推理时因张量并行策略不同导致结果不一致的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 确定性推理 张量并行 大型语言模型 强化学习 浮点运算 归约顺序 树形结构不变核
📋 核心要点
- 现有LLM推理框架在不同张量并行规模下,由于浮点运算和归约顺序问题,导致相同输入产生不同输出,影响确定性。
- 论文提出树形结构不变核(TBIK),通过统一的分层二叉树结构对齐GPU内部和GPU之间的归约顺序,保证结果一致性。
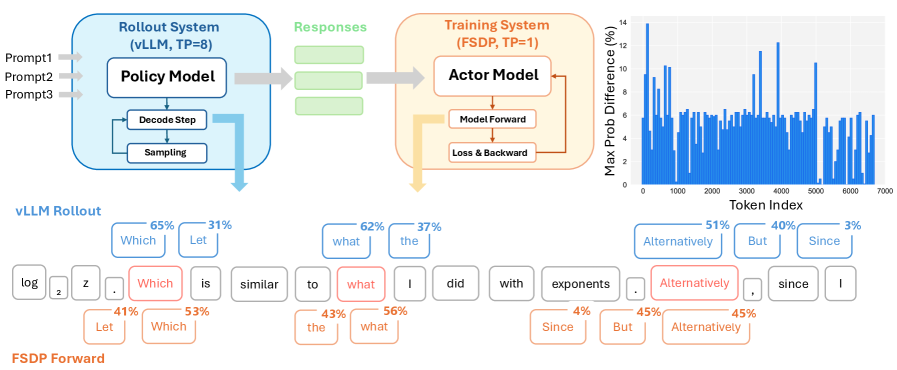
- 实验表明,TBIK在不同TP规模下实现了零概率发散和按位可重复性,并在RL训练中保证了vLLM和FSDP结果的一致性。
📝 摘要(中文)
确定性推理对于大型语言模型(LLM)应用,如LLM作为评判者、多智能体系统和强化学习(RL)等,变得越来越重要。然而,现有的LLM服务框架表现出非确定性行为:即使在贪婪解码下,当系统配置(例如,张量并行(TP)大小、批大小)发生变化时,相同的输入也可能产生不同的输出。这源于浮点运算的非结合性和GPU之间不一致的归约顺序。虽然之前的工作已经通过批次不变核解决了与批大小相关的非确定性问题,但跨不同TP大小的确定性仍然是一个开放问题,特别是在RL设置中,训练引擎通常使用完全分片数据并行(即TP = 1),而rollout引擎依赖于多GPU TP以最大化推理吞吐量,从而在两者之间产生自然的不匹配。这种精度不匹配问题可能导致次优性能,甚至导致RL训练崩溃。我们识别并分析了TP引起的不一致的根本原因,并提出了树形结构不变核(TBIK),这是一组TP不变的矩阵乘法和归约原语,保证了无论TP大小如何,都能获得按位相同的结果。我们的关键见解是通过统一的分层二叉树结构来对齐GPU内部和GPU之间的归约顺序。我们在Triton中实现了这些内核,并将它们集成到vLLM和FSDP中。实验证实了跨不同TP大小的确定性推理的零概率发散和按位可重复性。此外,我们还在具有不同并行策略的RL训练管道中实现了vLLM和FSDP之间的按位相同的结果。代码可在https://github.com/nanomaoli/llm_reproducibility获得。
🔬 方法详解
问题定义:现有的大型语言模型推理框架在不同的张量并行(TP)规模下,即使是相同的输入,也可能产生不同的输出。这是由于浮点运算的非结合性以及GPU之间归约顺序的不一致造成的。这种不确定性在强化学习(RL)等场景中尤为关键,因为训练和推理阶段通常使用不同的TP规模,导致精度不匹配,进而影响模型性能甚至导致训练崩溃。
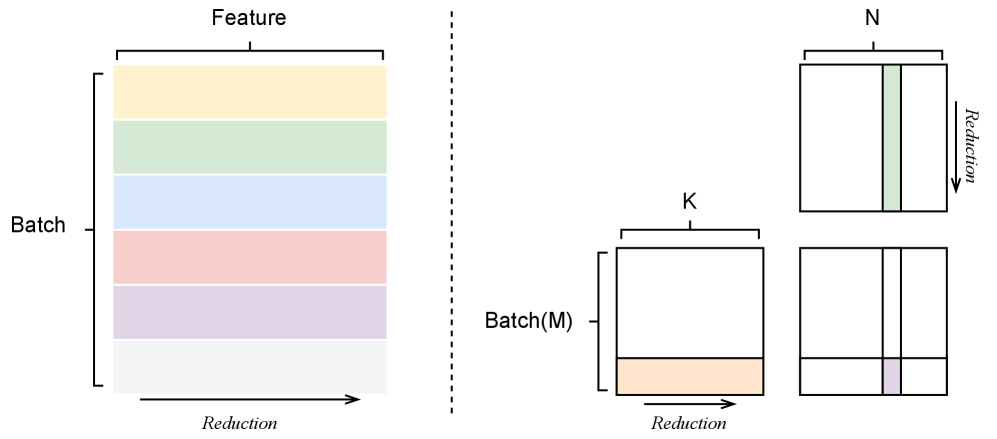
核心思路:论文的核心思路是通过统一的归约顺序来保证不同TP规模下的计算结果一致性。具体来说,论文设计了一种基于树形结构的归约方法,确保无论TP规模如何,GPU内部和GPU之间的归约顺序都是一致的。这种方法避免了因不同TP规模导致的归约顺序差异,从而消除了非确定性。
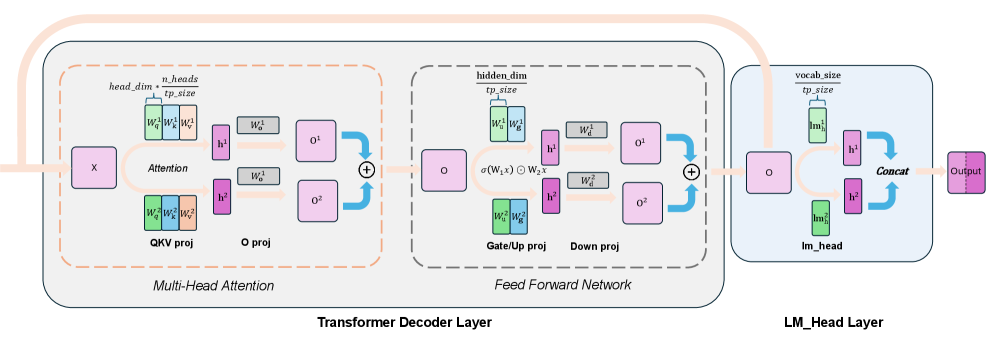
技术框架:论文提出了Tree-Based Invariant Kernels (TBIK),包含TP不变的矩阵乘法和归约原语。该框架的核心是使用分层二叉树结构来对齐GPU内部和GPU之间的归约顺序。具体流程如下:首先,将数据在各个GPU上进行分片;然后,在每个GPU内部进行局部归约;接着,通过二叉树结构在GPU之间进行全局归约。这种分层结构保证了无论TP规模如何变化,归约的顺序都是一致的。
关键创新:论文最关键的创新点在于提出了基于树形结构的归约方法,解决了不同TP规模下归约顺序不一致的问题。与现有方法相比,TBIK能够保证无论TP规模如何,都能获得按位相同的结果,从而实现了确定性推理。
关键设计:TBIK的关键设计在于二叉树结构的构建和归约操作的实现。论文使用Triton编程语言实现了TBIK,并将其集成到vLLM和FSDP中。在具体实现中,需要仔细设计二叉树的结构,确保每个GPU都能参与到归约过程中,并且归约的顺序是正确的。此外,还需要优化归约操作的性能,以减少额外的计算开销。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TBIK能够实现跨不同TP规模的确定性推理,概率发散为零,并达到按位可重复性。此外,在强化学习训练流程中,使用TBIK能够保证vLLM和FSDP在不同并行策略下得到完全一致的结果,验证了TBIK在实际应用中的有效性。
🎯 应用场景
该研究成果可广泛应用于对确定性要求较高的LLM应用场景,例如LLM作为评判者进行评估、多智能体系统中的决策制定,以及强化学习中的策略训练。通过消除TP规模带来的不确定性,可以提高这些应用的可靠性和稳定性,并促进LLM在更多领域的应用。
📄 摘要(原文)
Deterministic inference is increasingly critical for large language model (LLM) applications such as LLM-as-a-judge evaluation, multi-agent systems, and Reinforcement Learning (RL). However, existing LLM serving frameworks exhibit non-deterministic behavior: identical inputs can yield different outputs when system configurations (e.g., tensor parallel (TP) size, batch size) vary, even under greedy decoding. This arises from the non-associativity of floating-point arithmetic and inconsistent reduction orders across GPUs. While prior work has addressed batch-size-related nondeterminism through batch-invariant kernels, determinism across different TP sizes remains an open problem, particularly in RL settings, where the training engine typically uses Fully Sharded Data Parallel (i.e., TP = 1) while the rollout engine relies on multi-GPU TP to maximize the inference throughput, creating a natural mismatch between the two. This precision mismatch problem may lead to suboptimal performance or even collapse for RL training. We identify and analyze the root causes of TP-induced inconsistency and propose Tree-Based Invariant Kernels (TBIK), a set of TP-invariant matrix multiplication and reduction primitives that guarantee bit-wise identical results regardless of TP size. Our key insight is to align intra- and inter-GPU reduction orders through a unified hierarchical binary tree structure. We implement these kernels in Triton and integrate them into vLLM and FSDP. Experiments confirm zero probability divergence and bit-wise reproducibility for deterministic inference across different TP sizes. Also, we achieve bit-wise identical results between vLLM and FSDP in RL training pipelines with different parallel strategy. Code is available at https://github.com/nanomaoli/llm_reproducibility.