ReBaPL: Repulsive Bayesian Prompt Learning
作者: Yassir Bendou, Omar Ezzahir, Eduardo Fernandes Montesuma, Gabriel Mahuas, Victoria Shevchenko, Mike Gartrell
分类: cs.LG
发布日期: 2025-11-21
备注: Under review
💡 一句话要点
提出ReBaPL,通过排斥贝叶斯提示学习提升大模型在下游任务中的泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示学习 贝叶斯方法 后验推断 泛化能力 表示学习
📋 核心要点
- 传统prompt tuning方法易过拟合,且泛化能力弱,难以适应分布外数据。
- ReBaPL通过贝叶斯框架,结合循环步长SGHMC和表示空间排斥力,探索更全面的提示后验分布。
- 实验表明,ReBaPL在多个基准数据集上优于现有prompt learning方法,提升了泛化性能。
📝 摘要(中文)
本文提出了一种新的贝叶斯提示学习方法,名为Repulsive Bayesian Prompt Learning (ReBaPL),旨在有效探索提示词复杂且通常为多模态的后验分布。该方法将循环步长调度与随机梯度哈密顿蒙特卡洛(SGHMC)算法相结合,实现探索新模式和优化现有模式的交替阶段。此外,引入了一种排斥力,该排斥力源于对不同提示产生的表示分布计算的概率度量(包括最大均值差异和Wasserstein距离)的势函数。这种表示空间排斥力可以使探索多样化,并防止过早地崩溃到单一模式。我们的方法可以更全面地表征提示后验分布,从而提高泛化能力。与之前的贝叶斯提示学习方法相比,我们的方法为任何基于最大似然估计的现有提示学习方法提供了一种模块化的即插即用贝叶斯扩展。我们在多个基准数据集上验证了ReBaPL的有效性,表明其性能优于最先进的提示学习方法。
🔬 方法详解
问题定义:现有prompt tuning方法,尤其是基于最大似然估计的方法,容易陷入局部最优,导致过拟合,并且在面对分布外数据时泛化能力较差。贝叶斯prompt learning旨在通过对prompt的后验分布进行建模来解决这个问题,但如何有效地探索复杂的多模态后验分布仍然是一个挑战。
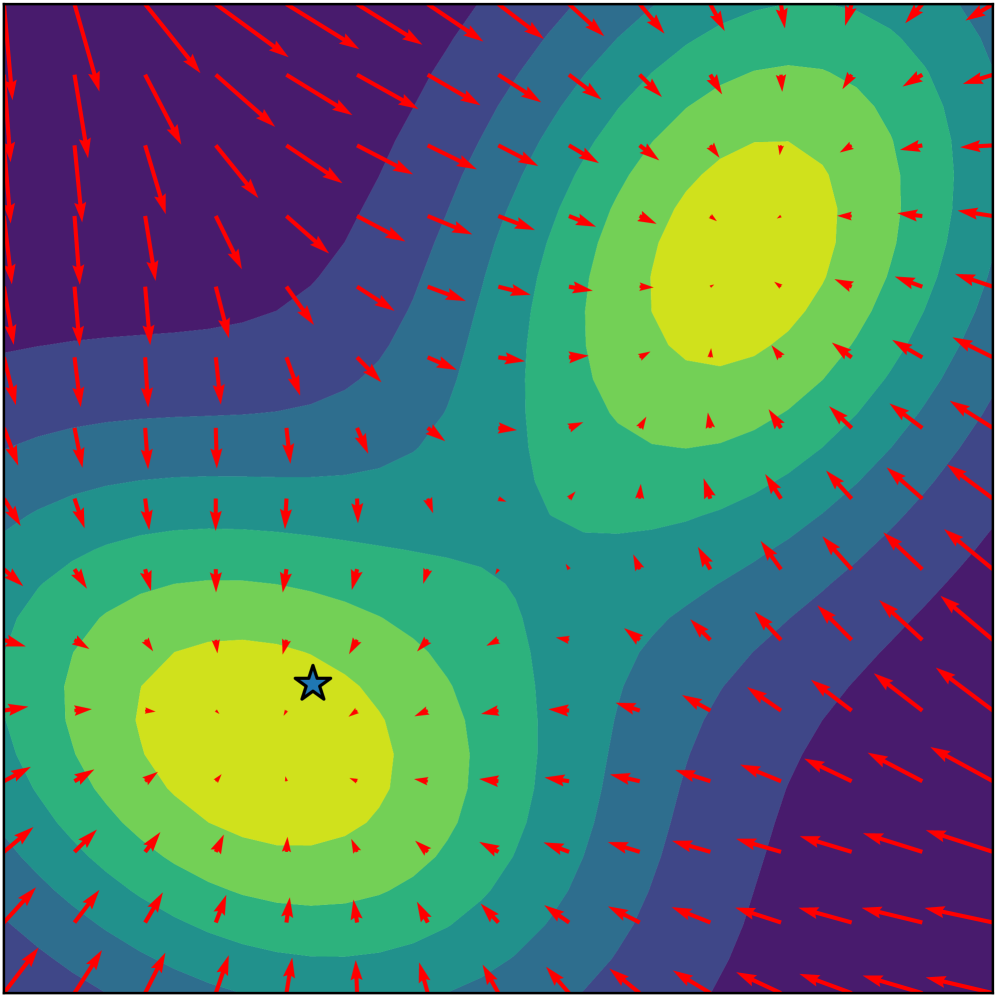
核心思路:ReBaPL的核心思路是通过引入一种排斥力,促使算法探索prompt的后验分布的不同模式,防止过早收敛到单一模式。同时,结合循环步长调度SGHMC算法,交替进行探索和优化,从而更全面地表征prompt的后验分布,提高泛化能力。
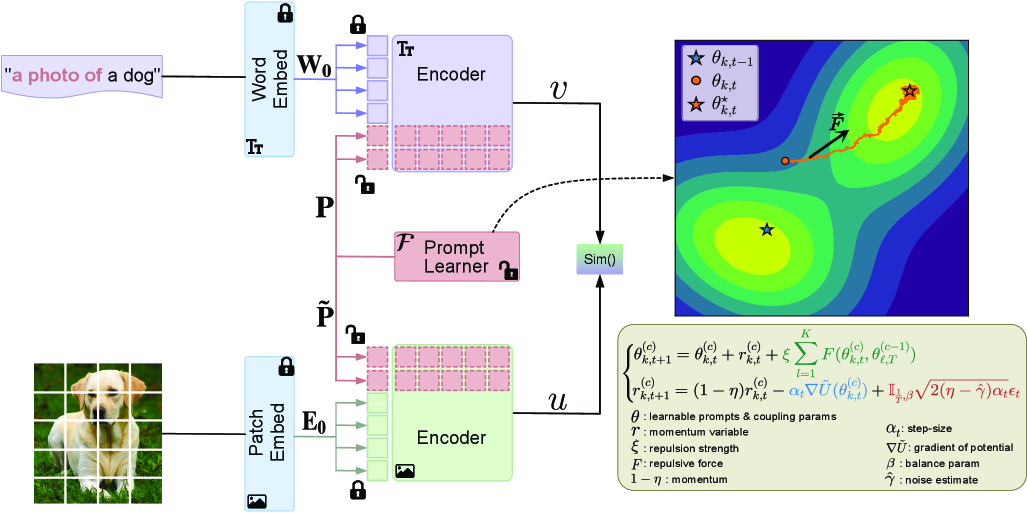
技术框架:ReBaPL的整体框架可以分为以下几个主要模块:1) 基于现有prompt learning方法(如Prefix Tuning)进行初始化;2) 使用SGHMC算法进行prompt的后验推断,其中步长采用循环调度策略;3) 计算不同prompt产生的表示之间的概率度量(如MMD或Wasserstein距离),并基于此定义排斥力;4) 将排斥力加入到SGHMC的更新过程中,引导算法探索不同的prompt模式。
关键创新:ReBaPL的关键创新在于引入了表示空间排斥力。与传统的贝叶斯方法不同,ReBaPL不仅仅依赖于似然函数来引导搜索,而是通过计算不同prompt产生的表示之间的差异,来鼓励算法探索不同的prompt模式。这种排斥力可以有效地防止算法陷入局部最优,并提高泛化能力。此外,ReBaPL提供了一种模块化的即插即用贝叶斯扩展,可以方便地应用于各种现有的prompt learning方法。
关键设计:ReBaPL的关键设计包括:1) 循环步长调度策略,用于控制SGHMC算法的探索和优化过程;2) 表示空间排斥力的计算方式,可以选择不同的概率度量(如MMD或Wasserstein距离)来衡量不同prompt产生的表示之间的差异;3) 排斥力的强度参数,用于控制排斥力对SGHMC更新的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ReBaPL在多个基准数据集上取得了优于现有prompt learning方法的性能。例如,在某些数据集上,ReBaPL相比于基线方法取得了显著的性能提升,证明了其在探索prompt后验分布和提高泛化能力方面的有效性。具体的性能数据和提升幅度在论文中有详细的展示。
🎯 应用场景
ReBaPL可应用于各种需要利用大型预训练模型进行下游任务微调的场景,尤其是在数据分布复杂或存在分布偏移的情况下。例如,在自然语言处理领域,可以用于文本分类、情感分析、机器翻译等任务;在计算机视觉领域,可以用于图像分类、目标检测、图像生成等任务。该方法能够提升模型在实际应用中的鲁棒性和泛化能力。
📄 摘要(原文)
Prompt learning has emerged as an effective technique for fine-tuning large-scale foundation models for downstream tasks. However, conventional prompt tuning methods are prone to overfitting and can struggle with out-of-distribution generalization. To address these limitations, Bayesian prompt learning has been proposed, which frames prompt optimization as a Bayesian inference problem to enhance robustness. This paper introduces Repulsive Bayesian Prompt Learning (ReBaPL), a novel method for Bayesian prompt learning, designed to efficiently explore the complex and often multimodal posterior landscape of prompts. Our method integrates a cyclical step-size schedule with a stochastic gradient Hamiltonian Monte Carlo (SGHMC) algorithm, enabling alternating phases of exploration to discover new modes, and exploitation to refine existing modes. Furthermore, we introduce a repulsive force derived from a potential function over probability metrics (including Maximum Mean Discrepancy and Wasserstein distance) computed on the distributions of representations produced by different prompts. This representation-space repulsion diversifies exploration and prevents premature collapse to a single mode. Our approach allows for a more comprehensive characterization of the prompt posterior distribution, leading to improved generalization. In contrast to prior Bayesian prompt learning methods, our method provides a modular plug-and-play Bayesian extension of any existing prompt learning method based on maximum likelihood estimation. We demonstrate the efficacy of ReBaPL on several benchmark datasets, showing superior performance over state-of-the-art methods for prompt learning.