Dissecting Quantum Reinforcement Learning: A Systematic Evaluation of Key Components
作者: Javier Lazaro, Juan-Ignacio Vazquez, Pablo Garcia-Bringas
分类: quant-ph, cs.LG
发布日期: 2025-11-21
💡 一句话要点
系统评估量子强化学习关键组件,揭示混合量子-经典架构的内在机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 参数化量子电路 数据重上传 输出重用 量子纠缠
📋 核心要点
- 现有量子强化学习方法面临训练不稳定、贫瘠高原等问题,难以有效分离各组件的贡献。
- 论文通过系统实验评估数据嵌入、ansatz设计和后处理模块等关键组件,剖析混合量子-经典架构。
- 实验表明,输出重用在混合架构中表现独特,数据重上传提升训练稳定性,而过强纠缠可能降低优化效果。
📝 摘要(中文)
基于参数化量子电路(PQC)的量子强化学习(QRL)是量子计算和强化学习(RL)交叉领域中一个很有前景的方向。PQC的设计创建了混合量子-经典模型,但由于训练不稳定、贫瘠高原(BPs)以及难以分离各个pipeline组件的贡献,其实际应用仍然不确定。本文通过对三个关键方面进行系统的实验评估来剖析基于PQC的QRL架构:(i)数据嵌入策略,以数据重上传(DR)作为一种高级方法;(ii)ansatz设计,特别是纠缠的作用;(iii)量子测量后的后处理模块,重点关注未被充分探索的输出重用(OR)技术。使用统一的PPO-CartPole框架,我们在相同条件下对混合和经典智能体进行受控比较。结果表明,OR虽然是纯粹的经典方法,但在混合pipeline中表现出不同的行为,DR提高了可训练性和稳定性,而更强的纠缠会降低优化效果,抵消经典增益。这些发现共同提供了量子和经典贡献之间相互作用的受控经验证据,并为QRL中的系统基准测试和组件分析建立了一个可重现的框架。
🔬 方法详解
问题定义:论文旨在解决量子强化学习(QRL)中,由于混合量子-经典架构的复杂性,难以理解和优化各个组件贡献的问题。现有方法难以分离数据嵌入、量子线路结构(ansatz)和后处理等模块对整体性能的影响,导致训练不稳定,容易陷入贫瘠高原,阻碍了QRL的实际应用。
核心思路:论文的核心思路是通过系统性的实验评估,解耦QRL pipeline中的各个关键组件,量化它们对性能的影响。通过控制变量,在统一的PPO-CartPole框架下,比较不同组件配置的混合量子-经典智能体和纯经典智能体,从而揭示量子和经典计算在QRL中的相互作用。
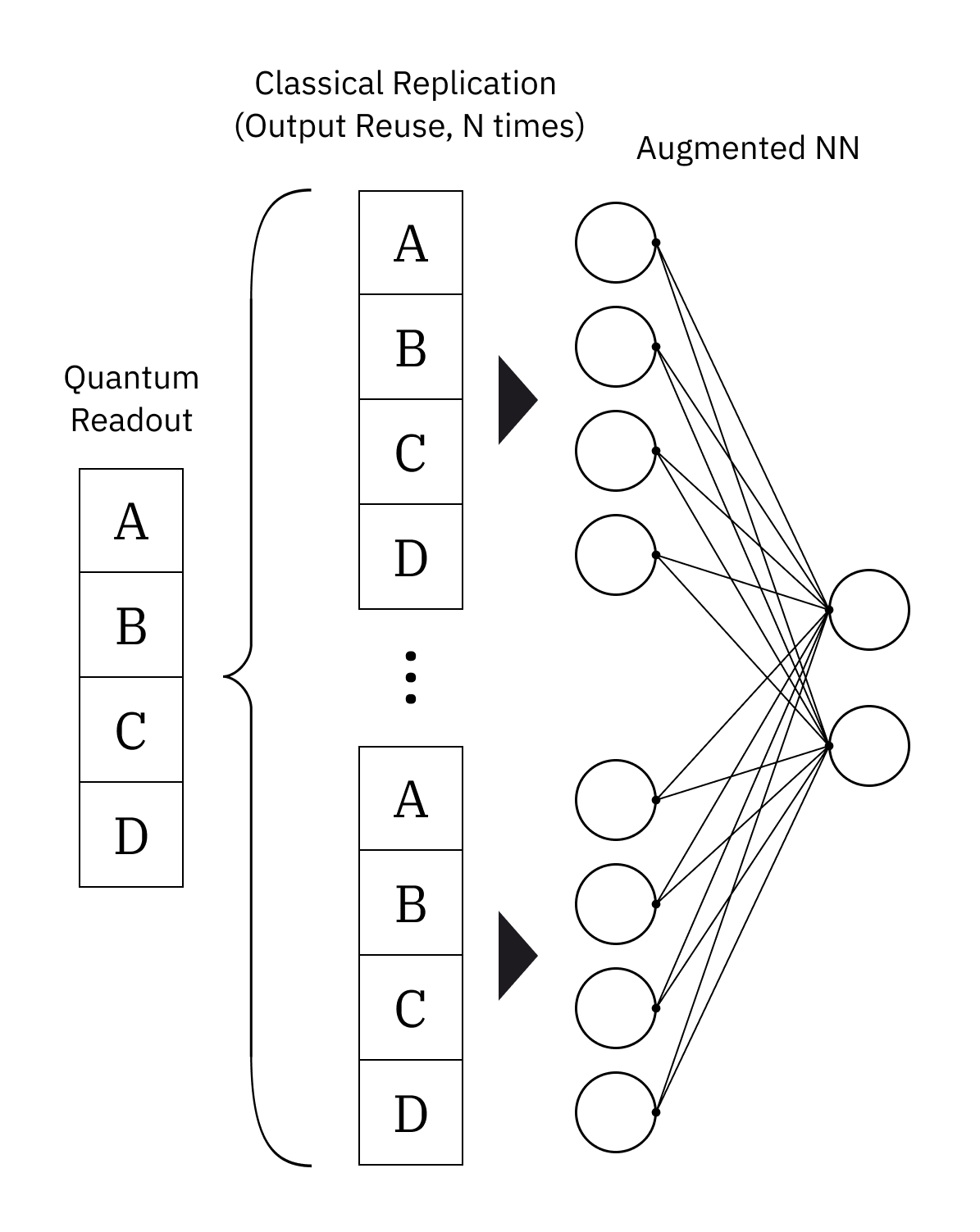
技术框架:论文采用PPO-CartPole作为统一的强化学习环境。QRL智能体的构建包含三个主要模块:1) 数据嵌入模块,负责将经典数据编码到量子态中,重点研究了Data Reuploading (DR)策略;2) 参数化量子电路(PQC)作为策略网络,其结构(ansatz)的设计考虑了纠缠的影响;3) 量子测量后的后处理模块,主要研究了Output Reuse (OR)技术。通过控制这些模块的配置,进行受控实验。
关键创新:论文的关键创新在于对QRL pipeline进行系统性的组件分析,并量化了各个组件对性能的影响。特别地,论文深入研究了数据重上传(DR)在提高训练稳定性和可训练性方面的作用,以及输出重用(OR)在混合架构中的独特行为。此外,论文还揭示了过强的量子纠缠可能对优化产生负面影响。
关键设计:论文的关键设计包括:1) 使用PPO算法作为强化学习的训练框架,保证了实验的可比性;2) 采用CartPole环境作为基准测试环境;3) 对比了不同数据嵌入策略(包括DR)、不同量子线路结构(ansatz,控制纠缠程度)和不同后处理方法(包括OR);4) 使用相同的超参数和训练流程,确保实验的公平性;5) 通过统计显著性检验来验证实验结果的可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,数据重上传(DR)显著提高了QRL的训练稳定性和可训练性。输出重用(OR)在混合量子-经典架构中表现出与纯经典架构不同的行为。此外,实验还发现,过强的量子纠缠可能会降低优化效果,抵消经典计算带来的增益。这些发现为QRL的组件优化提供了重要的经验证据。
🎯 应用场景
该研究成果可应用于量子控制、量子化学、金融建模等领域,通过优化量子强化学习算法,提升复杂决策问题的解决能力。研究结果有助于设计更高效的混合量子-经典算法,推动量子计算在实际问题中的应用。
📄 摘要(原文)
Parameterised quantum circuit (PQC) based Quantum Reinforcement Learning (QRL) has emerged as a promising paradigm at the intersection of quantum computing and reinforcement learning (RL). By design, PQCs create hybrid quantum-classical models, but their practical applicability remains uncertain due to training instabilities, barren plateaus (BPs), and the difficulty of isolating the contribution of individual pipeline components. In this work, we dissect PQC based QRL architectures through a systematic experimental evaluation of three aspects recurrently identified as critical: (i) data embedding strategies, with Data Reuploading (DR) as an advanced approach; (ii) ansatz design, particularly the role of entanglement; and (iii) post-processing blocks after quantum measurement, with a focus on the underexplored Output Reuse (OR) technique. Using a unified PPO-CartPole framework, we perform controlled comparisons between hybrid and classical agents under identical conditions. Our results show that OR, though purely classical, exhibits distinct behaviour in hybrid pipelines, that DR improves trainability and stability, and that stronger entanglement can degrade optimisation, offsetting classical gains. Together, these findings provide controlled empirical evidence of the interplay between quantum and classical contributions, and establish a reproducible framework for systematic benchmarking and component-wise analysis in QRL.