Credal Ensemble Distillation for Uncertainty Quantification
作者: Kaizheng Wang, Fabio Cuzzolin, David Moens, Hans Hallez
分类: cs.LG, cs.AI
发布日期: 2025-11-14
备注: An extended version for Credal Ensemble Distillation for Uncertainty Quantification, which has been accepted for publication at AAAI 2026
💡 一句话要点
提出Credal Ensemble Distillation (CED)框架,用于深度集成模型的知识蒸馏和不确定性量化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 不确定性量化 深度集成 知识蒸馏 credal集合 分布外检测
📋 核心要点
- 深度集成模型在不确定性量化方面表现出色,但其高计算成本限制了实际应用。
- Credal Ensemble Distillation (CED)通过知识蒸馏将集成模型压缩为单模型,降低推理成本。
- 实验表明,CED在不确定性估计方面与现有方法相当,同时显著降低了推理开销。
📝 摘要(中文)
深度集成模型(DE)已成为量化预测不确定性、区分偶然不确定性和认知不确定性的有效方法,从而增强模型的鲁棒性和可靠性。然而,它们在推理过程中高昂的计算和内存成本对广泛的实际部署构成了重大挑战。为了克服这个问题,我们提出了一种新的credal ensemble distillation (CED)框架,该框架将DE压缩成一个用于分类任务的单模型CREDIT。CREDIT不预测单一的softmax概率分布,而是预测类别的概率区间,这些区间定义了一个credal集合,即概率分布的凸集,用于不确定性量化。在分布外检测基准上的实验结果表明,与几种现有的基线相比,CED实现了优越或相当的不确定性估计,同时与DE相比,大大降低了推理开销。
🔬 方法详解
问题定义:深度集成模型(DE)在不确定性量化方面表现出色,能够区分偶然不确定性和认知不确定性。然而,DE需要维护多个模型,导致推理阶段计算和内存开销巨大,难以部署到资源受限的场景中。因此,如何降低DE的推理成本,同时保持其良好的不确定性量化能力,是一个亟待解决的问题。
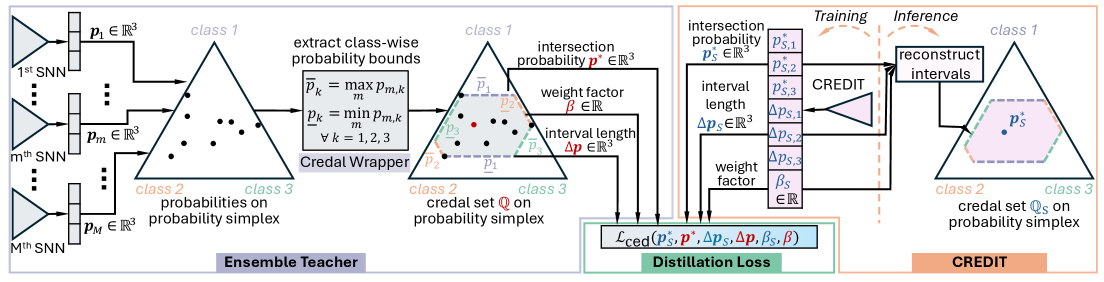
核心思路:论文的核心思路是通过知识蒸馏,将深度集成模型(教师模型)的知识转移到一个单模型(学生模型)中。与传统的知识蒸馏方法不同,该论文提出的方法不是让学生模型学习教师模型的softmax概率分布,而是学习一个credal集合,即类别的概率区间。这个概率区间能够反映模型的不确定性。
技术框架:CED框架主要包含两个阶段:1) 训练深度集成模型作为教师模型;2) 使用教师模型的预测结果训练单模型CREDIT作为学生模型。CREDIT模型的输出不是单一的softmax概率分布,而是每个类别的概率区间,这些区间构成一个credal集合。训练CREDIT模型的损失函数包括分类损失和credal损失,其中分类损失用于保证模型的分类精度,credal损失用于使CREDIT模型的概率区间尽可能地包含教师模型的预测结果。
关键创新:该论文的关键创新在于使用credal集合来表示模型的不确定性。与传统的softmax概率分布相比,credal集合能够更灵活地表示模型的不确定性,并且能够更好地捕捉到模型在分布外数据上的不确定性。此外,该论文还提出了一种新的credal损失函数,用于训练CREDIT模型,使其能够学习到教师模型的credal集合。
关键设计:CREDIT模型的网络结构可以根据具体的任务进行选择。在实验中,作者使用了与教师模型相同的网络结构。Credal损失函数的设计是关键,需要保证CREDIT模型的概率区间能够尽可能地包含教师模型的预测结果,同时避免概率区间过大,导致模型过于保守。具体的credal损失函数的设计细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
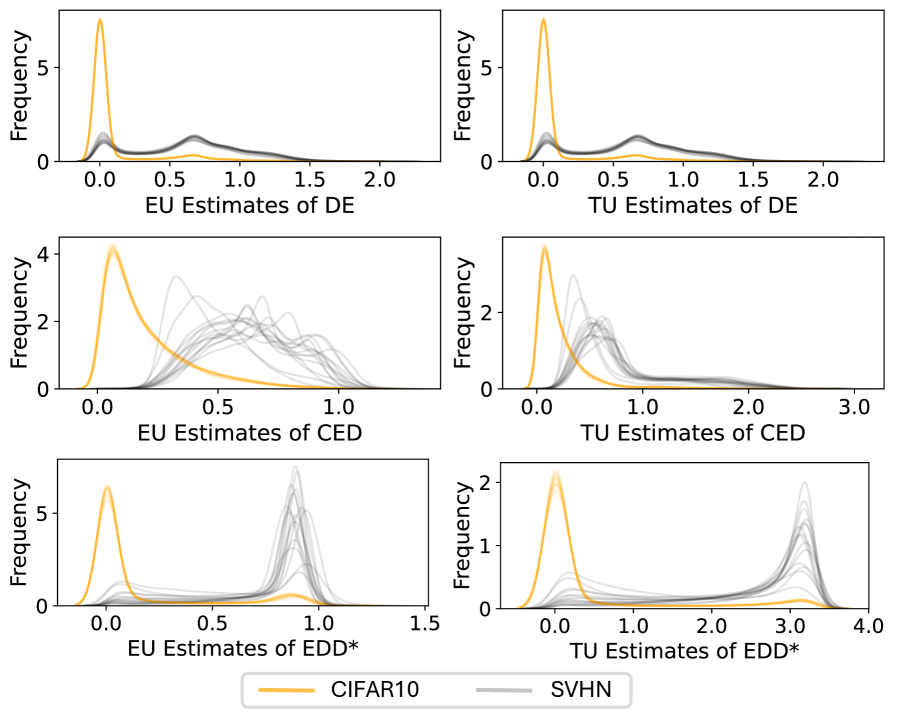
实验结果表明,CED在分布外检测任务上取得了优异的性能,与深度集成模型相比,在不确定性估计方面表现相当,同时显著降低了推理开销。具体而言,CED在多个基准数据集上取得了与深度集成模型相当或更好的AUROC指标,同时推理速度提升了数倍。
🎯 应用场景
该研究成果可应用于对模型可靠性要求较高的场景,例如自动驾驶、医疗诊断等。通过量化模型的不确定性,可以帮助决策者更好地理解模型的预测结果,并做出更明智的决策。此外,该方法还可以用于检测分布外数据,提高模型的鲁棒性。
📄 摘要(原文)
Deep ensembles (DE) have emerged as a powerful approach for quantifying predictive uncertainty and distinguishing its aleatoric and epistemic components, thereby enhancing model robustness and reliability. However, their high computational and memory costs during inference pose significant challenges for wide practical deployment. To overcome this issue, we propose credal ensemble distillation (CED), a novel framework that compresses a DE into a single model, CREDIT, for classification tasks. Instead of a single softmax probability distribution, CREDIT predicts class-wise probability intervals that define a credal set, a convex set of probability distributions, for uncertainty quantification. Empirical results on out-of-distribution detection benchmarks demonstrate that CED achieves superior or comparable uncertainty estimation compared to several existing baselines, while substantially reducing inference overhead compared to DE.