Better LLM Reasoning via Dual-Play
作者: Zhengxin Zhang, Chengyu Huang, Aochong Oliver Li, Claire Cardie
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-11-14 (更新: 2026-01-15)
备注: 33 pages, 17 figures, 17 tables
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PasoDoble:一种基于双人对抗博弈的无监督LLM推理能力提升方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 对抗学习 双人博弈 无监督学习
📋 核心要点
- 现有LLM推理能力提升方法依赖大量外部监督数据,成本高昂且泛化性受限。
- PasoDoble通过双人对抗博弈,让Proposer和Solver相互学习,无需人工标注即可提升推理能力。
- 实验表明,PasoDoble能有效提升LLM的推理性能,在无监督条件下达到甚至超越有监督方法的效果。
📝 摘要(中文)
大型语言模型(LLMs)通过基于可验证奖励的强化学习(RLVR)取得了显著进展,但仍然严重依赖外部监督(例如,人工标注)。对抗学习,特别是通过自博弈,提供了一种有希望的替代方案,使模型能够迭代地从自身学习,从而减少对外部监督的依赖。双人博弈通过为两个模型分配专门的角色并训练它们相互对抗,从而扩展了对抗学习,促进了持续的竞争和相互进化。尽管前景广阔,但将双人博弈训练应用于LLM仍然有限,这主要是由于它们容易受到奖励黑客和训练不稳定性的影响。本文介绍了一种新颖的LLM双人博弈框架PasoDoble。PasoDoble以对抗方式训练两个从相同基础模型初始化的模型:一个Proposer,生成带有真实答案的具有挑战性的问题;以及一个Solver,尝试解决这些问题。我们利用预训练数据集中的知识来丰富Proposer,以确保问题的质量和多样性。为了避免奖励黑客,Proposer仅因生成能够推动Solver能力上限的有效问题而获得奖励,而Solver因正确解决这些问题而获得奖励,并且两者被联合更新。为了进一步提高训练稳定性,我们引入了一种可选的离线范式,该范式解耦了Proposer和Solver的更新,交替更新每个模型几个步骤,同时保持另一个模型固定。值得注意的是,PasoDoble在训练期间无需监督。实验结果表明,PasoDoble可以提高LLM的推理性能。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的推理能力提升通常依赖于大量的外部监督数据,例如人工标注的问答对。这种方法成本高昂,且模型的泛化能力受到限制,难以适应新的领域和任务。此外,基于奖励的强化学习方法容易出现奖励黑客现象,导致模型学习到不期望的行为。
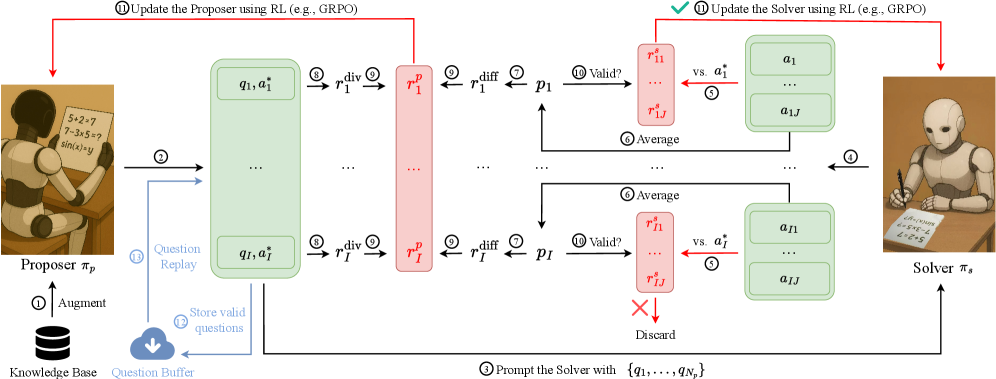
核心思路:PasoDoble的核心思路是利用双人对抗博弈的思想,让两个模型相互学习,从而在没有外部监督的情况下提升LLM的推理能力。具体来说,一个模型(Proposer)负责生成具有挑战性的问题,另一个模型(Solver)负责解决这些问题。通过不断地对抗和学习,Proposer能够生成更难的问题,而Solver能够解决更复杂的问题,从而共同提升推理能力。
技术框架:PasoDoble的整体框架包含两个主要模块:Proposer和Solver。Proposer负责生成问题和对应的答案,Solver负责解决Proposer提出的问题。训练过程可以分为在线和离线两种模式。在线模式下,Proposer和Solver同步更新;离线模式下,Proposer和Solver交替更新,即先固定Solver更新Proposer,再固定Proposer更新Solver。这种离线更新方式有助于提高训练的稳定性。
关键创新:PasoDoble的关键创新在于其双人对抗博弈的训练方式,以及针对LLM特点设计的奖励机制和训练策略。与传统的自博弈方法不同,PasoDoble为两个模型分配了不同的角色,并设计了专门的奖励函数,鼓励Proposer生成高质量的问题,并鼓励Solver解决这些问题。此外,PasoDoble还引入了离线更新模式,以提高训练的稳定性。
关键设计:Proposer的奖励函数设计为:只有当Proposer生成的问题是有效且能够推动Solver能力上限时,Proposer才能获得奖励。Solver的奖励函数设计为:只有当Solver正确解决了Proposer提出的问题时,Solver才能获得奖励。为了保证Proposer生成的问题的质量和多样性,PasoDoble利用预训练数据集中的知识来丰富Proposer。此外,PasoDoble还采用了多种训练技巧,例如梯度裁剪和学习率衰减,以提高训练的稳定性和收敛速度。
🖼️ 关键图片
📊 实验亮点
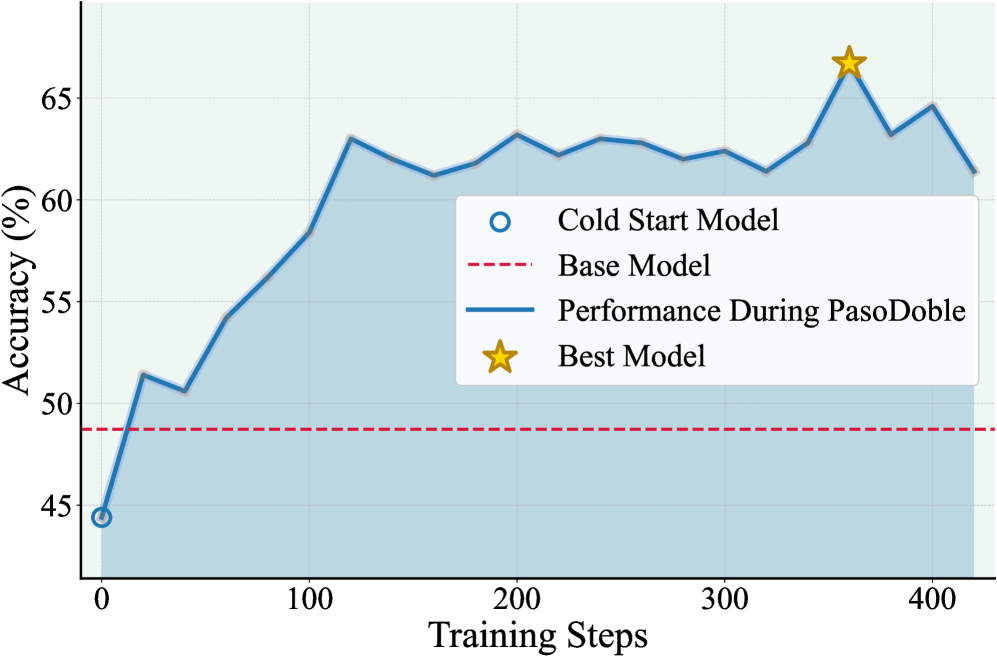
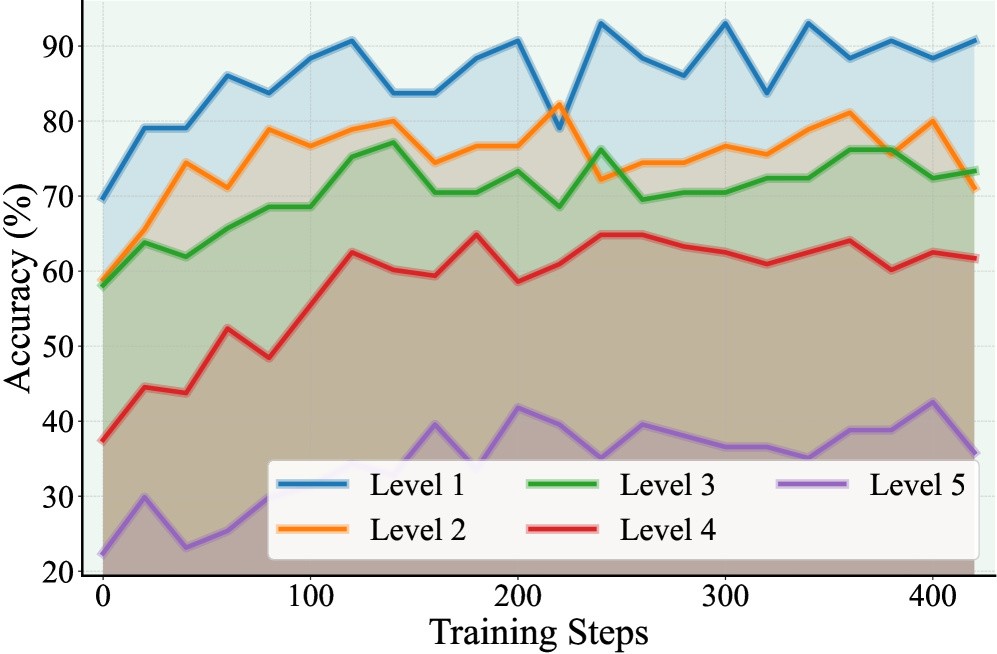
实验结果表明,PasoDoble在多个推理任务上取得了显著的性能提升。例如,在某些任务上,PasoDoble的性能甚至超过了使用监督数据训练的模型。此外,PasoDoble还表现出了良好的泛化能力,能够在不同的领域和任务上取得一致的性能提升。
🎯 应用场景
PasoDoble可应用于各种需要LLM具备强大推理能力的场景,例如智能问答、知识图谱推理、代码生成等。该方法无需人工标注数据,降低了训练成本,并提高了模型在不同领域和任务上的泛化能力。未来,PasoDoble可以与其他技术相结合,例如强化学习和迁移学习,进一步提升LLM的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable progress through Reinforcement Learning with Verifiable Rewards (RLVR), yet still rely heavily on external supervision (e.g., curated labels). Adversarial learning, particularly through self-play, offers a promising alternative that enables models to iteratively learn from themselves - thus reducing reliance on external supervision. Dual-play extends adversarial learning by assigning specialized roles to two models and training them against each other, fostering sustained competition and mutual evolution. Despite its promise, adapting dual-play training to LLMs remains limited, largely due to their susceptibility to reward hacking and training instability. In this paper, we introduce PasoDoble, a novel LLM dual-play framework. PasoDoble adversarially trains two models initialized from the same base model: a Proposer, which generates challenging questions with ground-truth answers, and a Solver, which attempts to solve them. We enrich the Proposer with knowledge from a pre-training dataset to ensure the questions' quality and diversity. To avoid reward hacking, the Proposer is rewarded for producing only valid questions that push the Solver's limit, while the Solver is rewarded for solving them correctly, and both are updated jointly. To further enhance training stability, we introduce an optional offline paradigm that decouples Proposer and Solver updates, alternately updating each for several steps while holding the other fixed. Notably, PasoDoble operates without supervision during training. Experimental results show that PasoDoble can improve the reasoning performance of LLMs. Our project page is available at https://hcy123902.github.io/PasoDoble.