MedFedPure: A Medical Federated Framework with MAE-based Detection and Diffusion Purification for Inference-Time Attacks
作者: Mohammad Karami, Mohammad Reza Nemati, Aidin Kazemi, Ali Mikaeili Barzili, Hamid Azadegan, Behzad Moshiri
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-11-07
💡 一句话要点
MedFedPure:一种基于MAE检测和扩散净化的医学联邦学习框架,用于防御推理时攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 对抗攻击防御 医学影像 掩码自动编码器 扩散模型 脑肿瘤检测 隐私保护
📋 核心要点
- 现有联邦学习模型在医学影像领域易受推理时对抗攻击影响,可能导致严重误诊,且现有防御方法难以适应联邦学习分散性。
- MedFedPure框架通过个性化联邦学习、MAE异常检测和扩散模型净化,在不影响隐私和准确性的前提下,防御对抗攻击。
- 在Br35H脑MRI数据集上的实验表明,MedFedPure在强对抗攻击下将模型性能从49.50%提升至87.33%,同时保持97.67%的清洁准确率。
📝 摘要(中文)
人工智能在医学影像领域,特别是使用磁共振成像(MRI)进行脑肿瘤检测方面,展现出巨大潜力。然而,当模型通过联邦学习(FL)进行协作训练时,在推理时仍然容易受到攻击,而联邦学习是一种保护患者隐私的方法。对抗性攻击可以微妙地改变医学扫描,这些改变对人眼来说是不可见的,但足以误导AI模型,可能导致严重的误诊。现有的防御方法通常假设集中式数据,并且难以应对联邦医学环境中分散和多样化的性质。在这项工作中,我们提出了MedFedPure,一个个性化的联邦学习防御框架,旨在保护诊断AI模型在推理时免受攻击,同时不影响隐私或准确性。MedFedPure结合了三个关键要素:(1)一个个性化的FL模型,适应每个机构的独特数据分布;(2)一个掩码自动编码器(MAE),通过暴露隐藏的扰动来检测可疑输入;(3)一个自适应的基于扩散的净化模块,选择性地清理仅被标记的扫描,然后再进行分类。总之,这些步骤提供了强大的保护,同时保持了正常、良性图像的完整性。我们在Br35H脑MRI数据集上评估了MedFedPure。结果表明,对抗鲁棒性显著提高,在强攻击下性能从49.50%提高到87.33%,同时保持了97.67%的高清洁准确率。通过在诊断期间本地和实时运行,我们的框架为在临床工作流程中部署安全、可信和保护隐私的AI工具提供了一条切实可行的途径。
🔬 方法详解
问题定义:论文旨在解决联邦学习在医学影像领域应用时,模型在推理阶段容易受到对抗攻击的问题。现有的防御方法通常是为集中式数据设计的,无法很好地适应联邦学习中数据分散、异构的特点,并且可能影响患者隐私。
核心思路:论文的核心思路是构建一个个性化的联邦学习防御框架,该框架能够在本地检测和净化对抗样本,从而提高模型的鲁棒性,同时保护患者隐私。该框架结合了个性化联邦学习、掩码自动编码器(MAE)和自适应扩散模型,以实现对对抗攻击的有效防御。
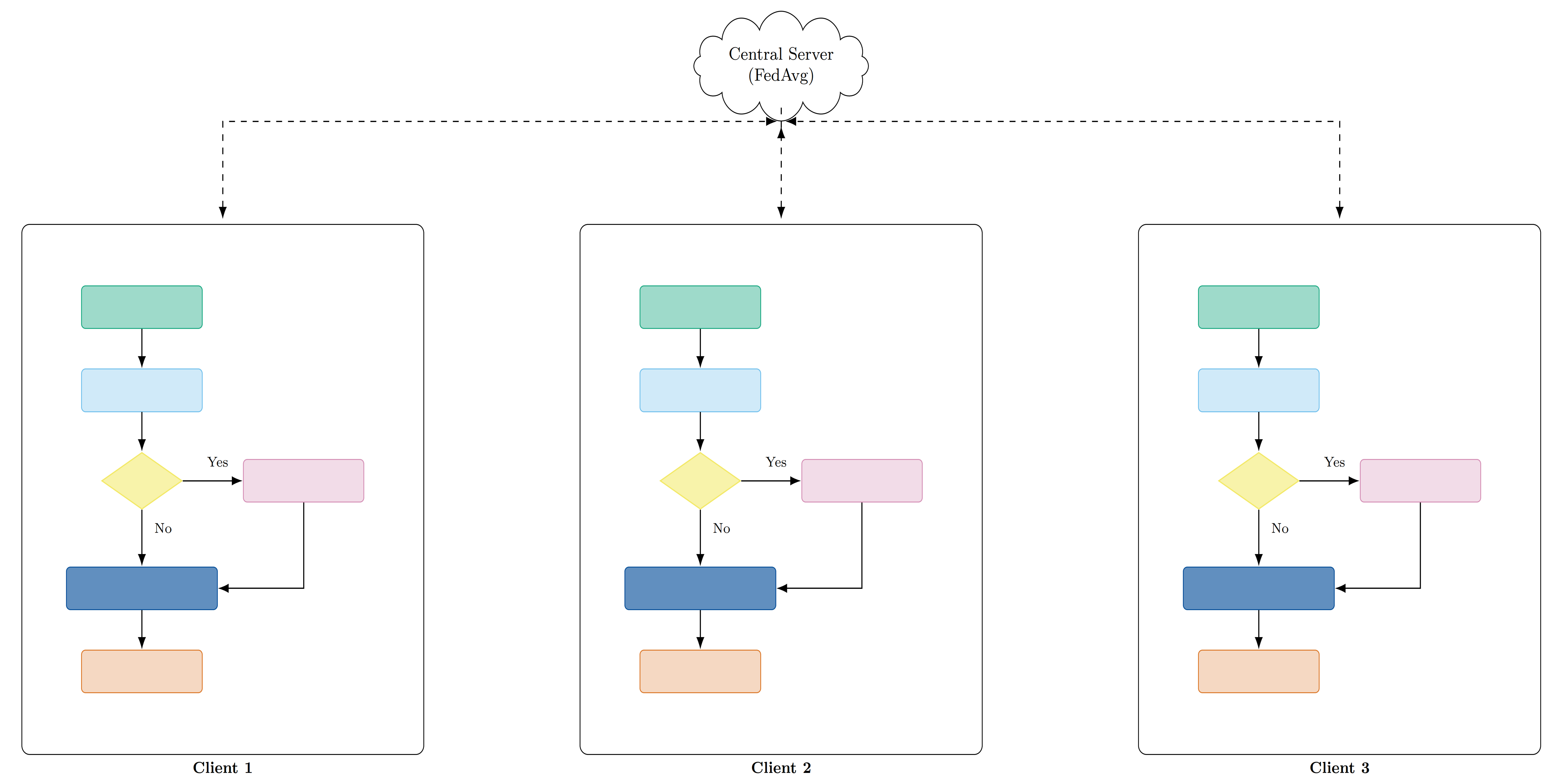
技术框架:MedFedPure框架包含三个主要模块:1) 个性化联邦学习模型:每个机构训练一个适应本地数据分布的模型。2) 基于MAE的异常检测器:使用MAE重建输入图像,通过比较重建误差来检测可疑的对抗样本。3) 自适应扩散净化模块:仅对被MAE标记为可疑的样本进行扩散净化,以去除对抗扰动。整体流程是,首先使用个性化联邦学习模型进行初步预测,然后使用MAE检测对抗样本,最后使用扩散模型净化对抗样本,并再次使用联邦学习模型进行预测。
关键创新:该论文的关键创新在于将MAE和扩散模型结合起来,用于联邦学习环境下的对抗攻击防御。MAE用于快速检测可疑样本,而扩散模型则用于精确净化这些样本。这种结合既保证了防御的效率,又提高了防御的准确性。此外,该框架是完全本地化的,不需要共享原始数据,从而保护了患者隐私。
关键设计:MAE使用预训练的ViT(Vision Transformer)作为编码器和解码器,通过mask掉部分输入图像并重建,来学习图像的潜在表示。重建误差被用作异常分数,用于判断输入是否为对抗样本。扩散模型使用DDPM(Denoising Diffusion Probabilistic Models),通过逐步添加噪声并将图像转换为高斯噪声,然后反向去噪,从而去除对抗扰动。一个关键的设计是自适应性,即只对被MAE标记为可疑的样本进行扩散净化,从而避免对正常样本造成不必要的修改。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MedFedPure在Br35H脑MRI数据集上显著提高了对抗鲁棒性。在强对抗攻击下,模型性能从49.50%提升至87.33%,提升幅度显著。同时,该框架保持了97.67%的高清洁准确率,表明其在防御对抗攻击的同时,不会对正常样本的诊断造成负面影响。这些结果验证了MedFedPure框架的有效性和实用性。
🎯 应用场景
MedFedPure框架可应用于各种医学影像诊断场景,例如脑肿瘤检测、病灶分割等。该研究的实际价值在于提高了联邦学习在医疗领域的安全性和可靠性,有助于在保护患者隐私的前提下,实现更准确、更可靠的AI辅助诊断。未来,该框架可以推广到其他联邦学习应用领域,例如金融、物联网等。
📄 摘要(原文)
Artificial intelligence (AI) has shown great potential in medical imaging, particularly for brain tumor detection using Magnetic Resonance Imaging (MRI). However, the models remain vulnerable at inference time when they are trained collaboratively through Federated Learning (FL), an approach adopted to protect patient privacy. Adversarial attacks can subtly alter medical scans in ways invisible to the human eye yet powerful enough to mislead AI models, potentially causing serious misdiagnoses. Existing defenses often assume centralized data and struggle to cope with the decentralized and diverse nature of federated medical settings. In this work, we present MedFedPure, a personalized federated learning defense framework designed to protect diagnostic AI models at inference time without compromising privacy or accuracy. MedFedPure combines three key elements: (1) a personalized FL model that adapts to the unique data distribution of each institution; (2) a Masked Autoencoder (MAE) that detects suspicious inputs by exposing hidden perturbations; and (3) an adaptive diffusion-based purification module that selectively cleans only the flagged scans before classification. Together, these steps offer robust protection while preserving the integrity of normal, benign images. We evaluated MedFedPure on the Br35H brain MRI dataset. The results show a significant gain in adversarial robustness, improving performance from 49.50% to 87.33% under strong attacks, while maintaining a high clean accuracy of 97.67%. By operating locally and in real time during diagnosis, our framework provides a practical path to deploying secure, trustworthy, and privacy-preserving AI tools in clinical workflows. Index Terms: cancer, tumor detection, federated learning, masked autoencoder, diffusion, privacy