Distributionally Robust Self Paced Curriculum Reinforcement Learning
作者: Anirudh Satheesh, Keenan Powell, Vaneet Aggarwal
分类: cs.LG
发布日期: 2025-11-07 (更新: 2025-11-12)
💡 一句话要点
提出DR-SPCRL,通过自步课程学习调整鲁棒性预算,提升强化学习在分布偏移下的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分布鲁棒强化学习 自步课程学习 鲁棒性预算 强化学习 分布偏移
📋 核心要点
- 传统强化学习在真实世界部署时,面临分布偏移带来的性能下降问题,分布鲁棒强化学习(DRRL)试图解决此问题。
- DR-SPCRL将鲁棒性预算视为一个连续的课程,根据智能体的学习进度自适应调整,平衡名义性能和鲁棒性。
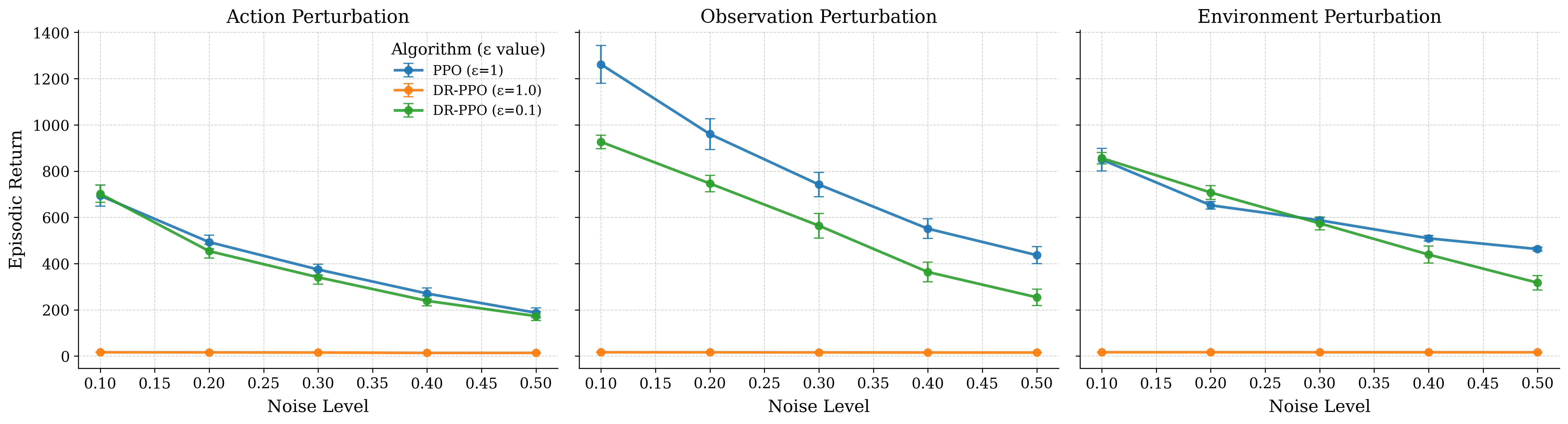
- 实验表明,DR-SPCRL在多个环境中稳定了训练,并显著提升了在扰动下的性能,平均情节回报提升11.8%。
📝 摘要(中文)
强化学习的一个核心挑战是,在受控环境中训练的策略在部署到真实世界的环境中时,常常由于分布偏移而失效。分布鲁棒强化学习(DRRL)通过在由鲁棒性预算ε定义的不确定性集合内优化最坏情况下的性能来解决这个问题。然而,固定ε会导致性能和鲁棒性之间的权衡:小的值产生高的名义性能但鲁棒性较弱,而大的值可能导致不稳定和过于保守的策略。我们提出了分布鲁棒自步课程强化学习(DR-SPCRL),该方法通过将ε视为连续的课程来克服这个限制。DR-SPCRL根据智能体的进展自适应地调度鲁棒性预算,从而在名义性能和鲁棒性能之间实现平衡。在多个环境中的实验结果表明,DR-SPCRL不仅稳定了训练,而且实现了卓越的鲁棒性-性能权衡,与固定或启发式调度策略相比,在不同的扰动下,平均情节回报提高了11.8%,并且达到了相应名义RL算法性能的约1.9倍。
🔬 方法详解
问题定义:论文旨在解决强化学习算法在真实世界部署时,由于训练环境与实际环境存在分布差异而导致的性能下降问题。现有的分布鲁棒强化学习方法(DRRL)通常采用固定的鲁棒性预算ε,这导致了性能和鲁棒性之间的权衡困境:较小的ε值虽然能保证名义性能,但鲁棒性较差;而较大的ε值则可能导致训练不稳定和策略过于保守。
核心思路:论文的核心思路是将DRRL中的鲁棒性预算ε视为一个可以动态调整的参数,并采用自步课程学习(Self-Paced Curriculum Learning)的思想,根据智能体的学习进度自适应地调整ε的值。通过这种方式,算法可以在训练初期侧重于名义性能的提升,随着训练的进行逐渐增加鲁棒性,从而在性能和鲁棒性之间取得更好的平衡。
技术框架:DR-SPCRL的整体框架可以概括为以下几个步骤: 1. 初始化:初始化强化学习智能体、环境以及鲁棒性预算ε的初始值。 2. 策略学习:使用当前的鲁棒性预算ε训练强化学习策略。 3. 鲁棒性预算更新:根据智能体的学习进度(例如,回报的变化、策略的稳定性等)自适应地调整鲁棒性预算ε的值。 4. 重复步骤2和3,直到训练收敛或达到预定的训练步数。
关键创新:DR-SPCRL的关键创新在于将分布鲁棒强化学习与自步课程学习相结合,提出了一种动态调整鲁棒性预算的策略。与传统的固定鲁棒性预算的方法相比,DR-SPCRL能够更好地适应智能体的学习过程,从而在性能和鲁棒性之间取得更好的平衡。此外,该方法还避免了手动调整鲁棒性预算的繁琐过程,提高了算法的易用性。
关键设计:DR-SPCRL的关键设计包括: 1. 鲁棒性预算更新策略:论文需要设计一种有效的策略来根据智能体的学习进度更新鲁棒性预算ε。这可能涉及到使用某种指标来衡量智能体的学习进度,例如回报的变化、策略的稳定性等。 2. 鲁棒性预算的上下界:为了避免鲁棒性预算过大或过小,论文需要设置ε的上下界。 3. 强化学习算法的选择:DR-SPCRL可以与各种强化学习算法相结合,例如Q-learning、SARSA、Actor-Critic等。论文需要选择一种合适的强化学习算法作为DR-SPCRL的基础。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DR-SPCRL在多个环境中均取得了显著的性能提升。与固定鲁棒性预算或启发式调度策略相比,DR-SPCRL在不同的扰动下,平均情节回报提高了11.8%。此外,DR-SPCRL还达到了相应名义RL算法性能的约1.9倍。这些结果表明,DR-SPCRL能够有效地提高强化学习算法的鲁棒性和性能。
🎯 应用场景
DR-SPCRL在机器人控制、自动驾驶、金融交易等领域具有广泛的应用前景。在这些领域中,环境通常是复杂且动态变化的,因此需要智能体具备较强的鲁棒性。DR-SPCRL能够有效地提高智能体在这些环境中的适应能力,从而提高其性能和可靠性。此外,该方法还可以应用于对抗性强化学习中,提高智能体抵御恶意攻击的能力。
📄 摘要(原文)
A central challenge in reinforcement learning is that policies trained in controlled environments often fail under distribution shifts at deployment into real-world environments. Distributionally Robust Reinforcement Learning (DRRL) addresses this by optimizing for worst-case performance within an uncertainty set defined by a robustness budget $ε$. However, fixing $ε$ results in a tradeoff between performance and robustness: small values yield high nominal performance but weak robustness, while large values can result in instability and overly conservative policies. We propose Distributionally Robust Self-Paced Curriculum Reinforcement Learning (DR-SPCRL), a method that overcomes this limitation by treating $ε$ as a continuous curriculum. DR-SPCRL adaptively schedules the robustness budget according to the agent's progress, enabling a balance between nominal and robust performance. Empirical results across multiple environments demonstrate that DR-SPCRL not only stabilizes training but also achieves a superior robustness-performance trade-off, yielding an average 11.8\% increase in episodic return under varying perturbations compared to fixed or heuristic scheduling strategies, and achieving approximately 1.9$\times$ the performance of the corresponding nominal RL algorithms.