Sample Complexity of Distributionally Robust Off-Dynamics Reinforcement Learning with Online Interaction
作者: Yiting He, Zhishuai Liu, Weixin Wang, Pan Xu
分类: cs.LG, cs.AI, cs.RO, stat.ML
发布日期: 2025-11-07
备注: 53 pages, 6 figures, 3 tables. Published in Proceedings of the 42nd International Conference on Machine Learning (ICML 2025)
期刊: Proceedings of the 42nd International Conference on Machine Learning, PMLR 267:22595-22646, 2025
💡 一句话要点
提出基于在线交互的分布鲁棒离策略强化学习算法,解决探索难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 鲁棒马尔可夫决策过程 在线学习 分布鲁棒性 离策略学习
📋 核心要点
- 现有离策略强化学习方法通常假设可以访问生成模型或预收集数据集,忽略了在线探索的挑战。
- 论文提出一种在线交互的分布鲁棒强化学习算法,通过至上访问比率来衡量训练与部署环境的差异。
- 该算法在基于f-散度的转移不确定性下实现了亚线性遗憾,并通过实验验证了理论结果。
📝 摘要(中文)
离策略强化学习(RL)中,训练和部署环境的转移动态不同,可以被建模为在鲁棒马尔可夫决策过程(RMDP)中学习,其中转移动态存在不确定性。现有文献大多假设可以访问生成模型,允许任意状态-动作查询,或者预先收集的数据集对部署环境有良好的状态覆盖,从而绕过了探索的挑战。本文研究了一个更现实和更具挑战性的场景,即智能体只能与训练环境进行在线交互。为了捕捉在线RMDP中探索的内在难度,我们引入了至上访问比率,这是一个衡量训练动态和部署动态之间不匹配的新指标。我们证明,如果这个比率是无界的,在线学习将变得非常困难。我们提出了第一个计算高效的算法,该算法在基于f-散度的转移不确定性的在线RMDP中实现了亚线性遗憾。我们还建立了匹配的遗憾下界,表明我们的算法在至上访问比率和交互次数上都达到了最优依赖性。最后,我们通过全面的数值实验验证了我们的理论结果。
🔬 方法详解
问题定义:论文旨在解决离策略强化学习中,训练环境和部署环境转移动态存在差异,且智能体只能通过与训练环境在线交互进行学习的问题。现有方法要么假设可以访问生成模型,要么依赖于预先收集的具有良好状态覆盖的数据集,这在实际应用中往往难以满足,忽略了在线探索的挑战。
核心思路:论文的核心思路是,通过引入“至上访问比率”这一新指标,来量化训练环境和部署环境之间转移动态的差异。该指标能够捕捉在线RMDP中探索的内在难度。基于此,设计一种能够有效探索并适应环境差异的强化学习算法。
技术框架:论文提出的算法框架主要包括以下几个阶段:1) 在线交互:智能体与训练环境进行交互,收集经验数据。2) 模型估计:利用收集到的数据,估计转移动态的不确定性,并构建鲁棒MDP模型。3) 策略优化:在鲁棒MDP模型下,优化策略,以应对环境的不确定性。4) 迭代更新:重复以上步骤,不断改进策略。
关键创新:论文最重要的技术创新在于:1) 提出了“至上访问比率”这一新指标,用于量化训练环境和部署环境之间的差异,为分析在线RMDP的难度提供了理论基础。2) 设计了一种计算高效的算法,该算法在基于f-散度的转移不确定性的在线RMDP中实现了亚线性遗憾,并在至上访问比率和交互次数上都达到了最优依赖性。
关键设计:论文的关键设计包括:1) 使用f-散度来度量转移动态的不确定性,这使得算法能够处理更广泛的不确定性类型。2) 算法的遗憾界与至上访问比率相关,这意味着算法能够自适应地调整探索策略,以应对不同的环境差异。3) 算法的计算复杂度较低,使其能够应用于实际问题。
🖼️ 关键图片

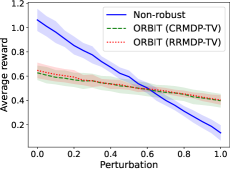
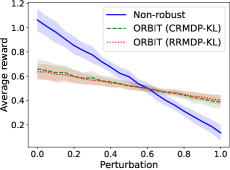
📊 实验亮点
论文通过数值实验验证了理论结果。实验结果表明,该算法在在线RMDP中能够实现亚线性遗憾,并且在至上访问比率和交互次数上都达到了最优依赖性。这表明该算法在处理环境差异和在线探索方面具有显著优势。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。在这些领域中,训练环境和实际部署环境往往存在差异,智能体需要在与环境交互的过程中不断学习和适应。该算法能够提高智能体在未知环境中的鲁棒性和泛化能力,降低部署成本。
📄 摘要(原文)
Off-dynamics reinforcement learning (RL), where training and deployment transition dynamics are different, can be formulated as learning in a robust Markov decision process (RMDP) where uncertainties in transition dynamics are imposed. Existing literature mostly assumes access to generative models allowing arbitrary state-action queries or pre-collected datasets with a good state coverage of the deployment environment, bypassing the challenge of exploration. In this work, we study a more realistic and challenging setting where the agent is limited to online interaction with the training environment. To capture the intrinsic difficulty of exploration in online RMDPs, we introduce the supremal visitation ratio, a novel quantity that measures the mismatch between the training dynamics and the deployment dynamics. We show that if this ratio is unbounded, online learning becomes exponentially hard. We propose the first computationally efficient algorithm that achieves sublinear regret in online RMDPs with $f$-divergence based transition uncertainties. We also establish matching regret lower bounds, demonstrating that our algorithm achieves optimal dependence on both the supremal visitation ratio and the number of interaction episodes. Finally, we validate our theoretical results through comprehensive numerical experiments.