Turning Adversaries into Allies: Reversing Typographic Attacks for Multimodal E-Commerce Product Retrieval
作者: Janet Jenq, Hongda Shen
分类: cs.LG
发布日期: 2025-11-07
💡 一句话要点
提出一种反转印刷攻击的视觉-文本压缩方法,提升电商多模态商品检索性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 视觉-语言模型 印刷攻击 视觉-文本压缩 电商 商品检索 图像渲染
📋 核心要点
- 现有的多模态商品检索系统易受印刷攻击,图像中嵌入的无关文本会误导模型。
- 该方法将商品标题、描述等文本信息渲染到图像上,实现视觉-文本压缩,增强图像-文本对齐。
- 实验表明,该方法在多个电商数据集和视觉模型上,均能提升单模态和多模态检索精度。
📝 摘要(中文)
电商平台中的多模态商品检索系统依赖于有效结合视觉和文本信号来提升搜索相关性和用户体验。然而,诸如CLIP之类的视觉-语言模型容易受到印刷攻击的影响,即嵌入在图像中的误导性或不相关的文本会扭曲模型预测。本文提出了一种新颖的方法,通过将相关的文本内容(例如,标题、描述)直接渲染到产品图像上来反转印刷攻击的逻辑,从而执行视觉-文本压缩,进而加强图像-文本对齐并提高多模态商品检索性能。我们在三个垂直领域的电商数据集(运动鞋、手提包和交易卡)上,使用六个最先进的视觉基础模型评估了我们的方法。实验表明,该方法在不同类别和模型系列中,都能持续提高单模态和多模态检索的准确性。我们的研究结果表明,以可视方式渲染产品元数据是一种简单而有效的增强方法,适用于电商应用中的零样本多模态检索。
🔬 方法详解
问题定义:论文旨在解决电商多模态商品检索中,视觉-语言模型易受印刷攻击影响的问题。现有的方法难以有效抵抗图像中嵌入的恶意或无关文本,导致检索结果偏差,影响用户体验。
核心思路:论文的核心思路是反转印刷攻击的逻辑,将相关的文本信息(如商品标题、描述)直接渲染到产品图像上。通过这种方式,将文本信息以视觉形式融入图像,实现视觉-文本压缩,从而增强图像和文本之间的对齐关系。
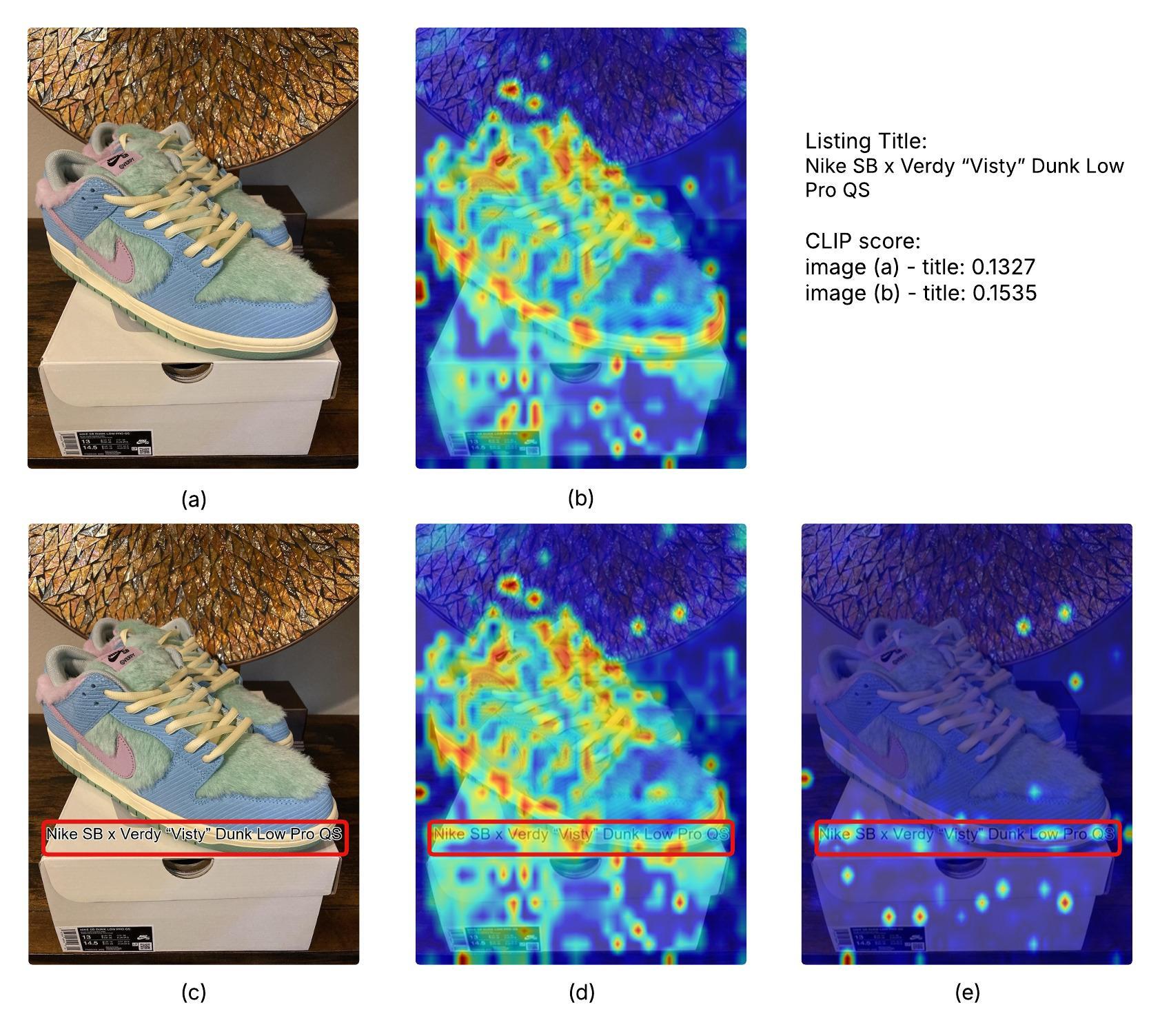
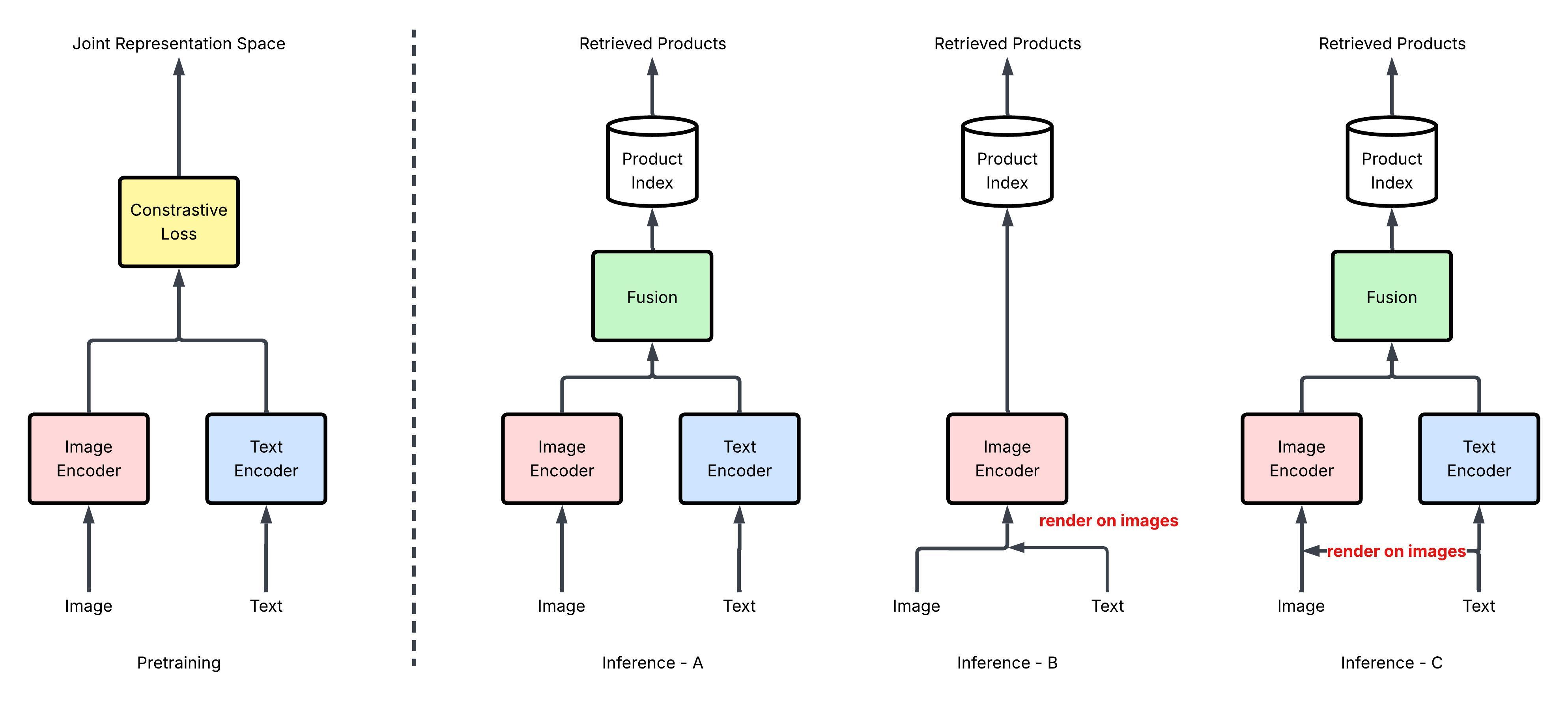
技术框架:该方法主要包含以下步骤:1) 选择需要渲染的文本信息(例如,商品标题、描述);2) 将文本信息以适当的字体、颜色和位置渲染到产品图像上,生成新的图像;3) 使用视觉基础模型(例如,CLIP)提取渲染后图像的视觉特征;4) 将提取的视觉特征与原始文本特征进行融合,用于多模态商品检索。
关键创新:该方法最重要的创新点在于将文本信息以视觉形式融入图像,从而实现视觉-文本压缩。这种方法有效地利用了图像的视觉表达能力,增强了图像和文本之间的关联性,提高了模型对印刷攻击的鲁棒性。与现有方法相比,该方法无需额外的对抗训练或数据增强,实现简单且效果显著。
关键设计:在文本渲染方面,需要仔细选择字体、颜色和位置,以确保文本信息清晰可读且不影响图像的整体美观。可以使用不同的字体大小和颜色来突出显示关键信息。在特征融合方面,可以使用不同的融合策略(例如,拼接、加权平均)来结合视觉特征和文本特征。具体的参数设置需要根据具体的数据集和模型进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在三个电商数据集(运动鞋、手提包和交易卡)上,使用六个视觉基础模型,均能显著提升单模态和多模态检索的准确性。例如,在某些数据集上,多模态检索的准确率提升超过5%。该方法无需额外的训练数据或复杂的模型结构,实现简单且效果显著。
🎯 应用场景
该研究成果可应用于电商平台的商品检索、推荐系统等领域,提升用户搜索体验,提高商品点击率和转化率。此外,该方法也可推广到其他多模态检索场景,例如图像搜索、视频搜索等,具有广泛的应用前景和实际价值。未来,可以探索更智能的文本渲染策略,例如根据图像内容自动调整文本位置和样式。
📄 摘要(原文)
Multimodal product retrieval systems in e-commerce platforms rely on effectively combining visual and textual signals to improve search relevance and user experience. However, vision-language models such as CLIP are vulnerable to typographic attacks, where misleading or irrelevant text embedded in images skews model predictions. In this work, we propose a novel method that reverses the logic of typographic attacks by rendering relevant textual content (e.g., titles, descriptions) directly onto product images to perform vision-text compression, thereby strengthening image-text alignment and boosting multimodal product retrieval performance. We evaluate our method on three vertical-specific e-commerce datasets (sneakers, handbags, and trading cards) using six state-of-the-art vision foundation models. Our experiments demonstrate consistent improvements in unimodal and multimodal retrieval accuracy across categories and model families. Our findings suggest that visually rendering product metadata is a simple yet effective enhancement for zero-shot multimodal retrieval in e-commerce applications.