Leak@$k$: Unlearning Does Not Make LLMs Forget Under Probabilistic Decoding
作者: Hadi Reisizadeh, Jiajun Ruan, Yiwei Chen, Soumyadeep Pal, Sijia Liu, Mingyi Hong
分类: cs.LG
发布日期: 2025-11-07
💡 一句话要点
揭示LLM在概率解码下遗忘失效:提出Leak@$k$评估知识泄漏
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 遗忘学习 知识泄漏 概率解码 元评估指标
📋 核心要点
- 现有LLM遗忘方法在确定性解码下表现良好,但在更现实的概率解码下,敏感信息仍然容易泄露。
- 论文提出Leak@$k$指标,通过评估模型在概率解码生成多个样本时,遗忘知识重新出现的可能性,来量化遗忘效果。
- 实验表明,现有遗忘方法在TOFU、MUSE和WMDP等基准测试中存在知识泄漏,需要更鲁棒的遗忘技术。
📝 摘要(中文)
大型语言模型(LLM)中的遗忘学习对于合规性以及构建避免生成私有、有害、非法或受版权保护内容的伦理生成式AI系统至关重要。尽管取得了快速进展,但本文表明,实际上几乎所有现有的遗忘方法都未能实现真正的遗忘。具体而言,虽然在确定性(贪婪)解码下对这些“已遗忘”模型的评估通常表明使用标准基准成功地移除了知识(正如文献中所做的那样),但我们表明,当使用标准概率解码对模型进行采样时,敏感信息会可靠地重新出现。为了严格捕捉这种漏洞,我们引入了 exttt{leak@$k$},这是一种新的元评估指标,用于量化从模型中生成$k$个样本时,在实际解码策略下,被遗忘知识重新出现的可能性。使用三个广泛采用的基准TOFU、MUSE和WMDP,我们使用新定义的 exttt{leak@$k$}指标进行了首次大规模、系统的遗忘可靠性研究。我们的研究结果表明,知识泄漏在各种方法和任务中持续存在,这表明当前最先进的遗忘技术仅提供有限的遗忘,并强调迫切需要更强大的LLM遗忘方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)遗忘学习中存在的知识泄漏问题。现有遗忘方法在确定性解码(如贪婪解码)下评估时,似乎能够有效移除目标知识,但在实际应用中,LLM通常采用概率解码策略生成文本。因此,现有评估方法无法真实反映遗忘效果,导致敏感信息在概率解码下仍然可能泄露。
核心思路:论文的核心思路是,通过模拟LLM在实际应用中的概率解码过程,评估遗忘后的模型是否仍然能够生成包含目标知识的文本。如果模型在多次采样后仍然能够生成包含目标知识的文本,则认为遗忘失败,存在知识泄漏。
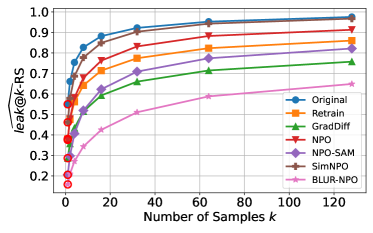
技术框架:论文提出了一个名为Leak@$k$的元评估指标,用于量化知识泄漏。该指标的计算流程如下:1. 对遗忘后的LLM进行$k$次概率解码采样,生成$k$个文本样本。2. 评估这$k$个样本中是否包含目标知识。3. Leak@$k$指标的值为包含目标知识的样本数量与$k$的比值,表示知识泄漏的概率。
关键创新:论文的关键创新在于提出了Leak@$k$指标,该指标能够更真实地反映LLM遗忘学习的效果。与现有评估方法相比,Leak@$k$指标考虑了LLM在实际应用中采用的概率解码策略,能够更准确地评估知识泄漏的风险。
关键设计:Leak@$k$指标的关键参数是采样次数$k$。$k$越大,评估结果越可靠,但计算成本也越高。论文中使用了三个广泛采用的基准数据集TOFU、MUSE和WMDP进行实验,并针对不同的数据集和任务,选择了合适的$k$值。
🖼️ 关键图片
📊 实验亮点
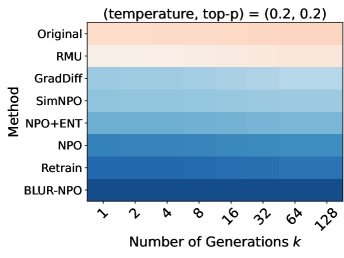
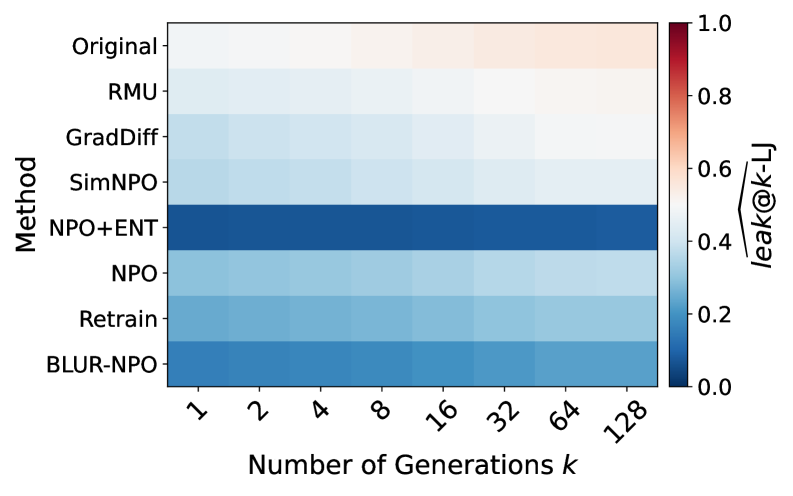
实验结果表明,现有最先进的遗忘方法在TOFU、MUSE和WMDP等基准测试中均存在显著的知识泄漏。例如,即使在经过遗忘处理后,模型仍然能够以较高的概率生成包含目标知识的文本。这表明现有遗忘技术仅提供有限的遗忘,需要进一步改进。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性与合规性,例如在处理用户隐私数据、生成内容审核、版权保护等领域。通过更准确地评估和改进遗忘学习方法,可以有效防止模型泄露敏感信息,降低法律风险,并促进负责任的AI发展。
📄 摘要(原文)
Unlearning in large language models (LLMs) is critical for regulatory compliance and for building ethical generative AI systems that avoid producing private, toxic, illegal, or copyrighted content. Despite rapid progress, in this work we show that \textit{almost all} existing unlearning methods fail to achieve true forgetting in practice. Specifically, while evaluations of these `unlearned' models under deterministic (greedy) decoding often suggest successful knowledge removal using standard benchmarks (as has been done in the literature), we show that sensitive information reliably resurfaces when models are sampled with standard probabilistic decoding. To rigorously capture this vulnerability, we introduce \texttt{leak@$k$}, a new meta-evaluation metric that quantifies the likelihood of forgotten knowledge reappearing when generating $k$ samples from the model under realistic decoding strategies. Using three widely adopted benchmarks, TOFU, MUSE, and WMDP, we conduct the first large-scale, systematic study of unlearning reliability using our newly defined \texttt{leak@$k$} metric. Our findings demonstrate that knowledge leakage persists across methods and tasks, underscoring that current state-of-the-art unlearning techniques provide only limited forgetting and highlighting the urgent need for more robust approaches to LLM unlearning.