You Need Reasoning to Learn Reasoning: The Limitations of Label-Free RL in Weak Base Models
作者: Shuvendu Roy, Hossein Hajimirsadeghi, Mengyao Zhai, Golnoosh Samei
分类: cs.LG, cs.AI
发布日期: 2025-11-07
备注: 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: MATH-AI
🔗 代码/项目: GITHUB
💡 一句话要点
研究表明,无监督强化学习提升小模型推理能力受限,并提出课程学习与数据筛选方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无监督强化学习 推理能力 课程学习 数据筛选 小型语言模型 思维链 自反思
📋 核心要点
- 现有无监督强化学习方法在提升小模型推理能力方面存在局限性,依赖于模型预先存在的推理能力。
- 提出一种基于课程学习的无监督强化学习方法,逐步引入更难的问题,并筛选训练数据。
- 实验结果表明,该方法在不同模型大小和推理能力上均能实现一致的性能提升。
📝 摘要(中文)
最近,大型语言模型展示了无监督强化学习(RL)在提升推理能力方面的潜力,无需外部监督。然而,这些无标签RL方法在推理能力较弱的小型基础模型上的泛化性仍未被探索。本文系统地研究了无标签RL方法在不同模型大小和推理强度(从0.5B到7B参数)上的性能。实证分析揭示了关键的局限性:无标签RL高度依赖于基础模型预先存在的推理能力,对于较弱的模型,性能通常会降至基线水平以下。我们发现,较小的模型无法生成足够长或多样化的思维链推理,从而无法进行有效的自我反思,并且训练数据的难度在决定成功方面起着至关重要的作用。为了应对这些挑战,我们提出了一种简单而有效的无标签RL方法,该方法利用课程学习来逐步引入更难的问题,并在训练期间屏蔽无多数结果的rollout。此外,我们引入了一个数据管理流程来生成具有预定义难度的样本。我们的方法展示了所有模型大小和推理能力的一致改进,为更强大的无监督RL提供了一条途径,可以引导资源受限模型中的推理能力。代码已开源。
🔬 方法详解
问题定义:论文旨在解决无监督强化学习方法在提升小型语言模型推理能力时遇到的困难。现有方法,尤其是在大型语言模型上表现良好的方法,在小型模型上效果不佳,甚至可能导致性能下降。这是因为小型模型的推理能力有限,无法生成足够高质量的思维链数据进行自我反思和学习。现有方法没有考虑到模型本身推理能力的差异,以及训练数据难度对学习效果的影响。
核心思路:论文的核心思路是,无监督强化学习需要与模型的推理能力相匹配。对于推理能力较弱的模型,需要采用更循序渐进的学习方式,从简单到复杂,逐步提升其推理能力。同时,需要对训练数据进行筛选,避免引入过多噪声或难度过高的数据,从而提高学习效率和稳定性。
技术框架:论文提出的方法主要包含两个关键模块:课程学习和数据筛选。课程学习模块通过逐步增加训练数据的难度,引导模型逐步掌握更复杂的推理技能。数据筛选模块则用于过滤掉质量较差或难度过高的训练数据,例如,屏蔽掉没有多数结果的rollout。这两个模块协同工作,共同提升无监督强化学习的效果。
关键创新:论文的关键创新在于将课程学习和数据筛选引入到无监督强化学习中,并针对小型语言模型的特点进行了优化。与传统的无监督强化学习方法相比,该方法能够更好地适应不同模型的推理能力,并提高学习效率和稳定性。此外,论文还提出了一个数据管理流程来生成具有预定义难度的样本,进一步提升了训练数据的质量。
关键设计:课程学习的具体实现方式是,根据问题的难度对训练数据进行排序,然后按照难度递增的顺序进行训练。数据筛选的具体实现方式是,对于每个训练样本,如果多个rollout的结果不一致,则将其过滤掉。此外,论文还设计了一个损失函数,用于鼓励模型生成更长、更连贯的思维链。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
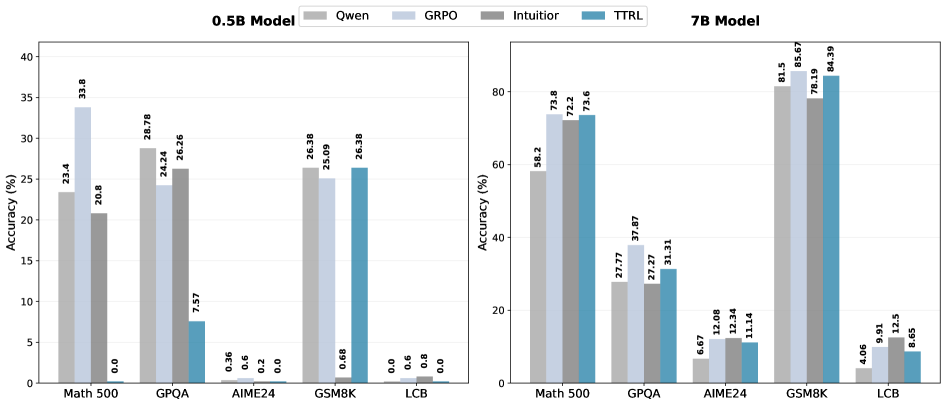
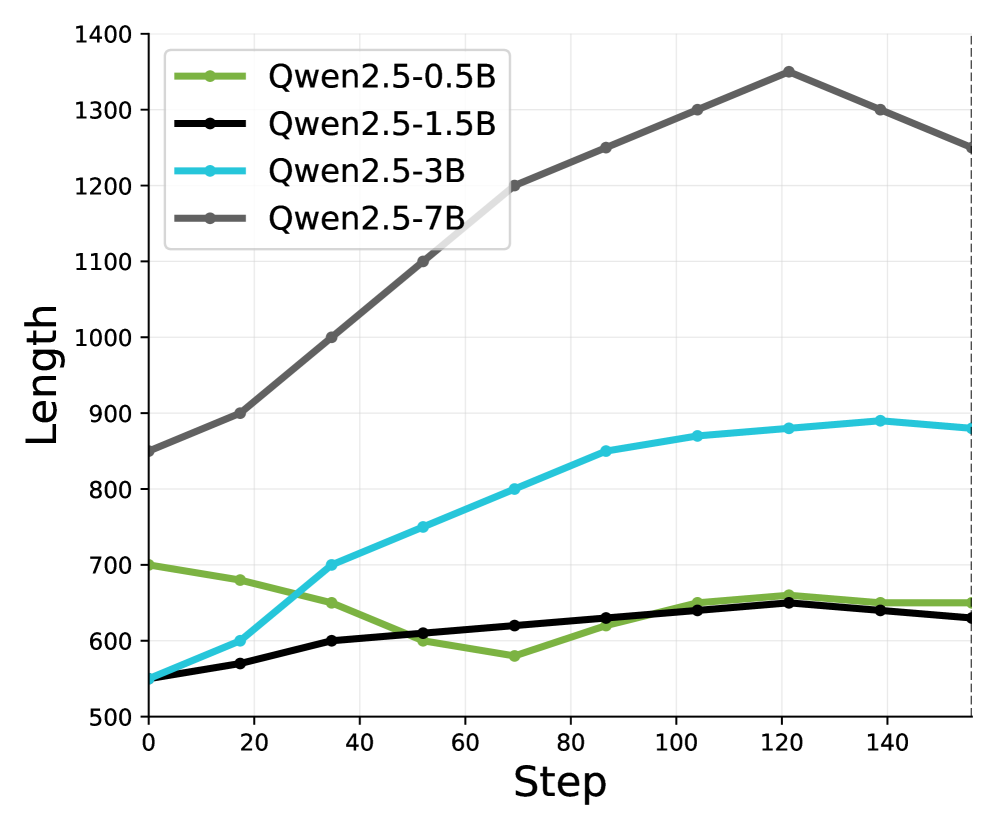
📊 实验亮点
实验结果表明,所提出的方法在不同模型大小(0.5B到7B参数)和推理能力上均能实现一致的性能提升。与基线方法相比,该方法能够显著提高小型语言模型的推理准确率,尤其是在难度较高的推理任务上。例如,在某些任务上,该方法可以将模型的推理准确率提高10%以上。
🎯 应用场景
该研究成果可应用于提升资源受限设备上的AI推理能力,例如在移动设备、嵌入式系统等算力有限的平台上部署更强大的AI应用。通过该方法,可以在无需大量标注数据的情况下,提升小型语言模型的推理能力,降低AI应用的开发和部署成本,并促进AI技术在更广泛领域的应用。
📄 摘要(原文)
Recent advances in large language models have demonstrated the promise of unsupervised reinforcement learning (RL) methods for enhancing reasoning capabilities without external supervision. However, the generalizability of these label-free RL approaches to smaller base models with limited reasoning capabilities remains unexplored. In this work, we systematically investigate the performance of label-free RL methods across different model sizes and reasoning strengths, from 0.5B to 7B parameters. Our empirical analysis reveals critical limitations: label-free RL is highly dependent on the base model's pre-existing reasoning capability, with performance often degrading below baseline levels for weaker models. We find that smaller models fail to generate sufficiently long or diverse chain-of-thought reasoning to enable effective self-reflection, and that training data difficulty plays a crucial role in determining success. To address these challenges, we propose a simple yet effective method for label-free RL that utilizes curriculum learning to progressively introduce harder problems during training and mask no-majority rollouts during training. Additionally, we introduce a data curation pipeline to generate samples with predefined difficulty. Our approach demonstrates consistent improvements across all model sizes and reasoning capabilities, providing a path toward more robust unsupervised RL that can bootstrap reasoning abilities in resource-constrained models. We make our code available at https://github.com/BorealisAI/CuMa