DeepThinkVLA: Enhancing Reasoning Capability of Vision-Language-Action Models
作者: Cheng Yin, Yankai Lin, Wang Xu, Sikyuen Tam, Xiangrui Zeng, Zhiyuan Liu, Zhouping Yin
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-31
备注: 16 pages, 6 figures, conference
💡 一句话要点
DeepThinkVLA通过混合注意力机制和双阶段训练提升VLA模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人推理 思维链 混合注意力机制 强化学习
📋 核心要点
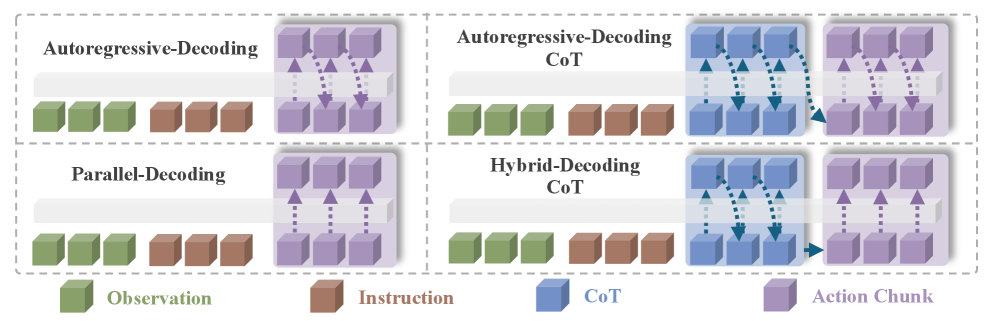
- 现有VLA模型使用单一解码器处理推理和动作,导致运动控制不佳,推理与动作间因果关系弱。
- DeepThinkVLA采用混合注意力解码器,先进行序列推理,再并行解码动作,并结合两阶段训练。
- 实验表明,DeepThinkVLA在LIBERO基准测试中达到97.0%的成功率,显著优于现有方法。
📝 摘要(中文)
本文提出DeepThinkVLA,旨在提升视觉-语言-动作(VLA)模型的推理能力,克服端到端机器人策略对数据的过度依赖。现有模型使用单一自回归解码器进行序列化的CoT推理和高维并行化的机器人动作,导致运动控制性能下降,且推理和动作之间缺乏强因果关系。DeepThinkVLA通过紧密集成的架构和训练策略解决这一冲突。该模型采用混合注意力解码器,利用因果注意力生成序列化的CoT,然后切换到双向注意力以快速并行地解码动作向量。此外,采用两阶段训练流程:首先使用监督微调(SFT)训练模型的基础推理能力,然后使用强化学习(RL)和任务成功奖励,使完整的推理-动作序列与期望结果对齐。实验结果表明,DeepThinkVLA在LIBERO基准测试中取得了97.0%的成功率,达到了最先进的性能。消融实验验证了设计的有效性:仅混合架构就比标准解码器高出15.5%,最终的RL阶段提供了关键的2%的性能提升。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型通常采用端到端的方式训练机器人策略,这需要大量的数据。为了提高模型的推理能力,引入了思维链(Chain-of-Thought, CoT)方法,但现有模型使用单一的自回归解码器同时处理序列化的CoT推理和高维、并行化的机器人动作。这种架构上的不匹配导致两个主要问题:一是运动控制性能下降,因为自回归解码器不适合并行生成动作;二是推理和动作之间缺乏强因果关系,模型难以学习到有效的策略。
核心思路:DeepThinkVLA的核心思路是通过解耦推理和动作生成过程,并使用专门设计的架构和训练策略来解决上述问题。具体来说,模型使用混合注意力解码器,首先利用因果注意力进行序列化的CoT推理,然后切换到双向注意力以快速并行地解码动作向量。此外,采用两阶段训练流程,首先使用监督微调(SFT)训练模型的基础推理能力,然后使用强化学习(RL)来对齐推理-动作序列与期望结果。
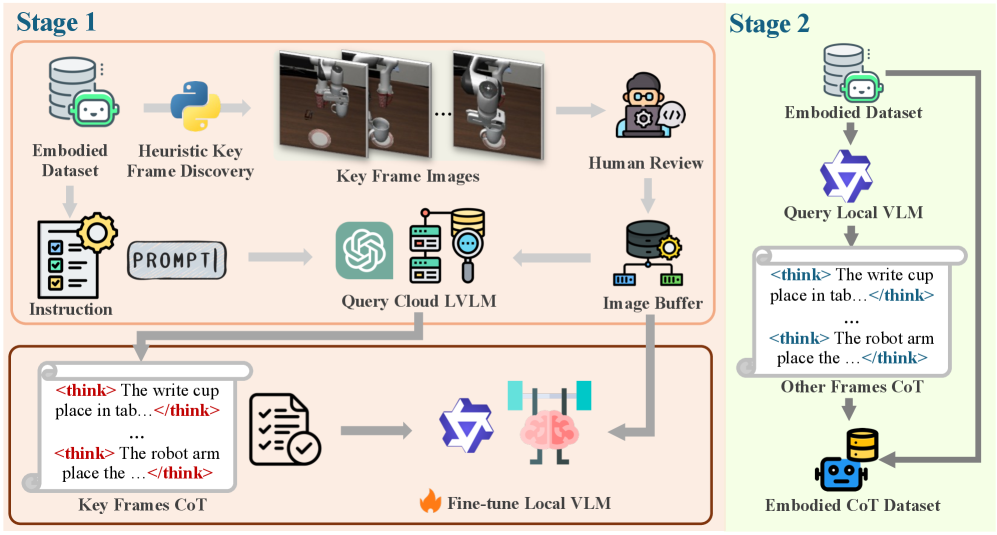
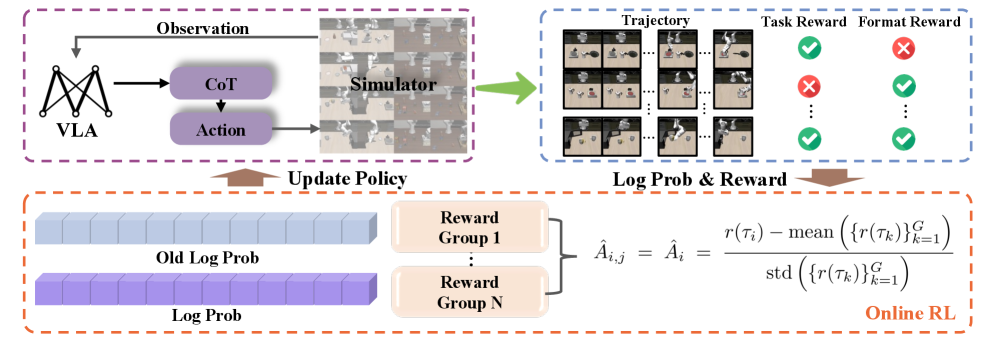
技术框架:DeepThinkVLA的整体架构包含一个视觉编码器、一个语言编码器和一个混合注意力解码器。视觉编码器和语言编码器分别用于提取图像和文本的特征。混合注意力解码器是该模型的核心组件,它首先使用因果注意力生成序列化的CoT推理步骤,然后切换到双向注意力以并行生成动作向量。训练过程分为两个阶段:第一阶段是监督微调(SFT),使用人工标注的CoT数据来训练模型的基础推理能力;第二阶段是强化学习(RL),使用任务成功奖励来优化模型的策略,使其能够生成有效的推理-动作序列。
关键创新:DeepThinkVLA的关键创新在于混合注意力解码器和两阶段训练策略。混合注意力解码器能够有效地解耦推理和动作生成过程,并分别使用适合的注意力机制进行处理。两阶段训练策略能够先训练模型的基础推理能力,然后再使用强化学习来对齐推理-动作序列与期望结果,从而提高模型的整体性能。
关键设计:混合注意力解码器包含一个因果注意力模块和一个双向注意力模块。因果注意力模块用于生成序列化的CoT推理步骤,它只允许模型关注之前的推理步骤。双向注意力模块用于并行生成动作向量,它允许模型关注所有的推理步骤。在训练过程中,SFT阶段使用交叉熵损失函数来训练模型的基础推理能力。RL阶段使用PPO算法来优化模型的策略,奖励函数基于任务的成功与否。
🖼️ 关键图片
📊 实验亮点
DeepThinkVLA在LIBERO基准测试中取得了97.0%的成功率,达到了最先进的性能。消融实验表明,仅混合架构就比标准解码器高出15.5%,最终的RL阶段提供了关键的2%的性能提升。这些结果表明,DeepThinkVLA的架构和训练策略能够有效地提升VLA模型的推理能力和任务完成度。
🎯 应用场景
DeepThinkVLA的研究成果可应用于各种机器人任务,例如家庭服务机器人、工业自动化机器人和自动驾驶汽车。通过提升机器人的推理能力,使其能够更好地理解环境、规划动作并完成复杂的任务。该研究还有助于开发更智能、更可靠的机器人系统,从而提高生产效率和生活质量。未来,该技术有望扩展到更广泛的领域,例如智能助手、虚拟现实和增强现实等。
📄 摘要(原文)
Enabling Vision-Language-Action (VLA) models to "think before acting" via Chain-of-Thought (CoT) is a promising path to overcoming the data-hungry nature of end-to-end robot policies. However, progress is stalled by a fundamental conflict: existing models use a single autoregressive decoder for both sequential CoT reasoning and high-dimensional, parallelizable robot actions. This architectural mismatch degrades motor control and fails to forge a strong causal link between thought and action. We introduce DeepThinkVLA, which resolves this conflict through a tightly integrated architecture and training strategy. Architecturally, our hybrid-attention decoder generates sequential CoT with causal attention and then switches to bidirectional attention for fast, parallel decoding of action vectors. This design is complemented by a two-stage training pipeline: we first use Supervised Fine-Tuning (SFT) to teach the model foundational reasoning, then apply Reinforcement Learning (RL) with task-success rewards to causally align the full reasoning-action sequence with desired outcomes. This synergy leads to state-of-the-art performance, achieving a 97.0% success rate on the LIBERO benchmark. Our ablations confirm the design's effectiveness: the hybrid architecture alone outperforms standard decoders by 15.5%, and the final RL stage provides a crucial 2% boost to secure top performance.