A Technical Exploration of Causal Inference with Hybrid LLM Synthetic Data
作者: Dana Kim, Yichen Xu, Tiffany Lin
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-10-31
备注: 9 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出混合生成框架,提升LLM合成数据在因果推断中的平均处理效应估计准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推断 合成数据 大型语言模型 平均处理效应 混合生成框架
📋 核心要点
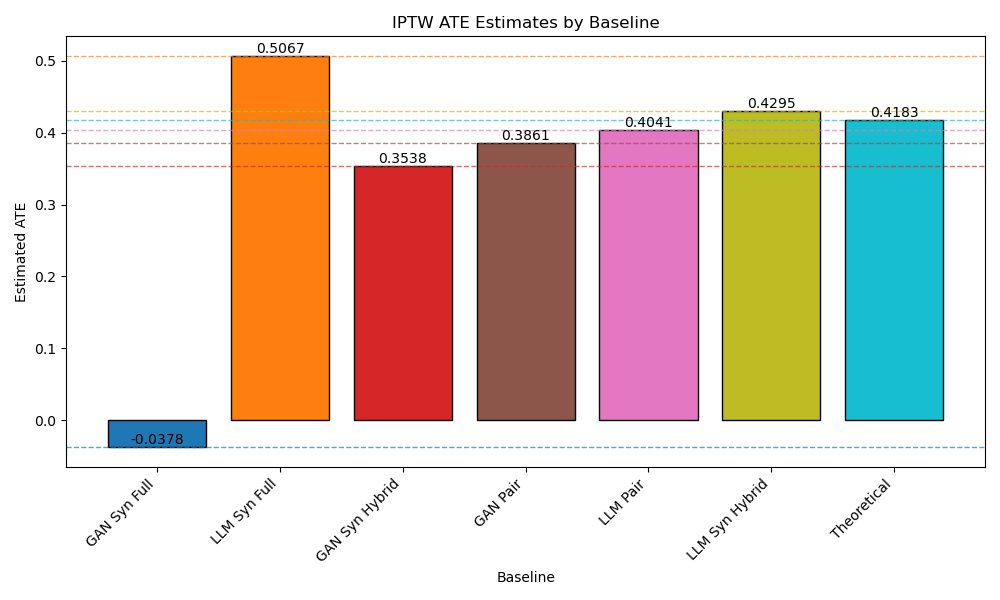
- 现有基于GAN和LLM的合成数据生成方法,虽然预测精度高,但在因果推断中对平均处理效应(ATE)的估计存在显著偏差。
- 提出一种混合生成框架,结合模型驱动的协变量合成与独立学习的倾向和结果模型,以保留数据中的因果结构。
- 引入合成配对策略缓解正性违背问题,并使用现实评估协议,在复杂协变量分布下评估传统估计器的性能。
📝 摘要(中文)
大型语言模型(LLMs)为生成合成表格数据提供了一种灵活的手段,但现有方法通常无法保留关键的因果参数,例如平均处理效应(ATE)。在这项技术探索中,我们首先证明了最先进的合成数据生成器,包括基于GAN和基于LLM的方法,可以在实现高预测精度的同时,大幅度地错误估计因果效应。为了解决这一差距,我们提出了一种混合生成框架,该框架结合了基于模型的协变量合成(通过最近邻距离过滤进行监控)与单独学习的倾向和结果模型,从而确保(W, A, Y)三元组保留其潜在的因果结构。我们进一步引入了一种合成配对策略来缓解正性违背问题,并采用了一种现实的评估协议,该协议利用无限的合成样本来评估复杂协变量分布下的传统估计器(IPTW、AIPW、替代)。这项工作为支持稳健因果分析的LLM驱动的数据管道奠定了基础。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLM)生成合成数据时,现有方法无法准确保留数据中潜在因果结构的问题,尤其是在平均处理效应(ATE)的估计方面。现有基于GAN和LLM的合成数据生成器虽然在预测精度上表现良好,但在因果推断任务中,对ATE的估计存在显著偏差,这限制了合成数据在因果分析中的应用。
核心思路:论文的核心思路是将协变量的生成与倾向得分和结果模型的学习解耦,采用混合生成框架。该框架首先使用模型生成协变量,并通过最近邻距离过滤来监控生成质量,然后独立学习倾向得分和结果模型。这种解耦的设计旨在确保合成数据能够保留原始数据中的因果关系,从而提高ATE估计的准确性。
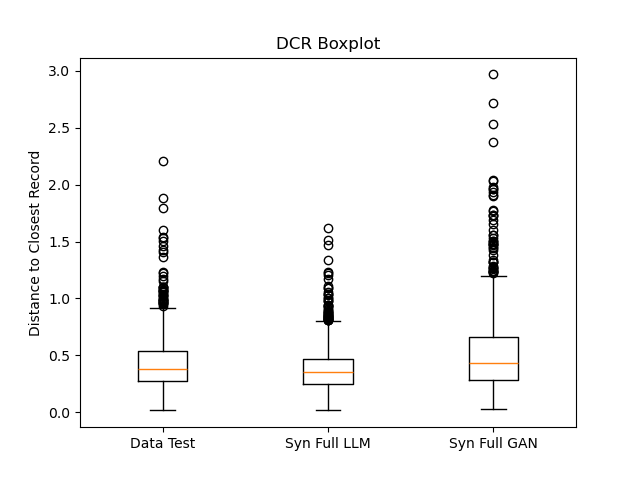
技术框架:整体框架包含以下几个主要模块:1) 协变量合成模块:使用模型(具体模型类型未明确说明,但暗示是可控的)生成协变量数据;2) 距离过滤模块:通过计算生成数据与真实数据之间的距离,过滤掉质量较差的合成数据;3) 倾向得分模型学习模块:基于合成的协变量和处理变量,学习倾向得分模型;4) 结果模型学习模块:基于合成的协变量、处理变量和结果变量,学习结果模型;5) 合成配对模块:使用合成配对策略缓解正性违背问题;6) 评估模块:使用合成数据评估传统因果推断估计器的性能。
关键创新:论文的关键创新在于混合生成框架的设计,它将协变量的生成与倾向得分和结果模型的学习解耦。这种解耦的设计与现有方法的本质区别在于,它更加关注因果结构的保留,而不是仅仅追求预测精度。此外,合成配对策略和现实评估协议也是重要的创新点,它们有助于提高合成数据的质量和评估的可靠性。
关键设计:论文中关于具体参数设置、损失函数和网络结构的描述较少,属于未明确部分。但可以推断,协变量合成模块可能涉及到特定的生成模型选择和参数调整;距离过滤模块可能需要设置距离阈值;倾向得分和结果模型可能涉及到模型选择(如逻辑回归、神经网络等)和超参数优化;合成配对策略的具体实现细节也需要仔细设计。
🖼️ 关键图片

📊 实验亮点
论文提出的混合生成框架能够显著提高合成数据在因果推断中的平均处理效应(ATE)估计准确性。通过与现有基于GAN和LLM的合成数据生成方法进行对比,验证了该框架的优越性。此外,论文还引入了合成配对策略和现实评估协议,进一步提升了合成数据的质量和评估的可靠性。具体的性能数据和提升幅度需要在论文原文中查找。
🎯 应用场景
该研究成果可应用于医疗健康、金融风控、市场营销等领域,通过生成高质量的合成数据,支持因果推断分析,从而帮助决策者更好地理解干预措施的效果,制定更有效的策略。例如,在医疗领域,可以利用合成数据评估不同治疗方案的疗效;在金融领域,可以评估不同信贷政策对违约率的影响。
📄 摘要(原文)
Large Language Models (LLMs) offer a flexible means to generate synthetic tabular data, yet existing approaches often fail to preserve key causal parameters such as the average treatment effect (ATE). In this technical exploration, we first demonstrate that state-of-the-art synthetic data generators, both GAN- and LLM-based, can achieve high predictive fidelity while substantially misestimating causal effects. To address this gap, we propose a hybrid generation framework that combines model-based covariate synthesis (monitored via distance-to-closest-record filtering) with separately learned propensity and outcome models, thereby ensuring that (W, A, Y) triplets retain their underlying causal structure. We further introduce a synthetic pairing strategy to mitigate positivity violations and a realistic evaluation protocol that leverages unlimited synthetic samples to benchmark traditional estimators (IPTW, AIPW, substitution) under complex covariate distributions. This work lays the groundwork for LLM-powered data pipelines that support robust causal analysis. Our code is available at https://github.com/Xyc-arch/llm-synthetic-for-causal-inference.git.