Calibration Across Layers: Understanding Calibration Evolution in LLMs
作者: Abhinav Joshi, Areeb Ahmad, Ashutosh Modi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-31
备注: Accepted at EMNLP 2025 (main)
💡 一句话要点
揭示LLM校准机制:层间校准演化与低维校准方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 校准 置信度 残差流 深度学习 MMLU 置信度校正
📋 核心要点
- 现有研究未能充分理解LLM校准能力在网络深度上的演化过程,仅关注最后一层。
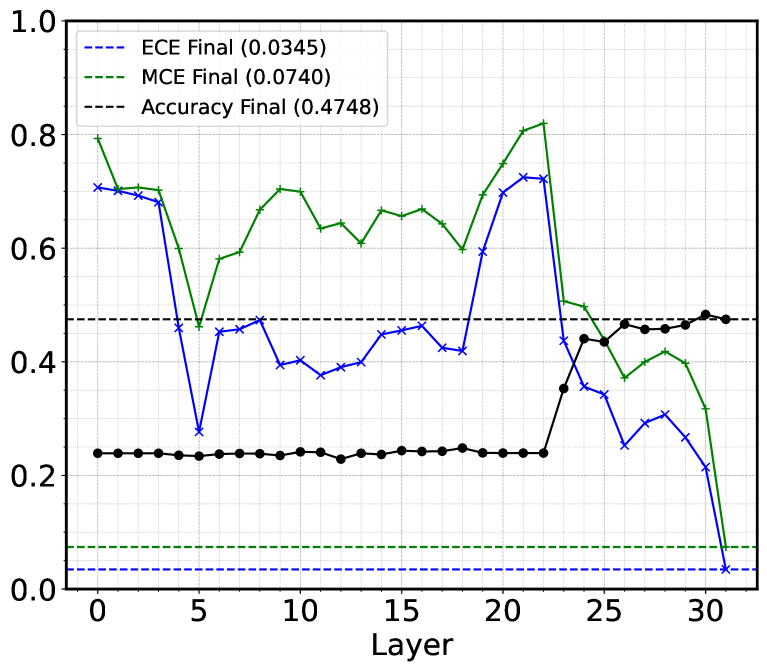
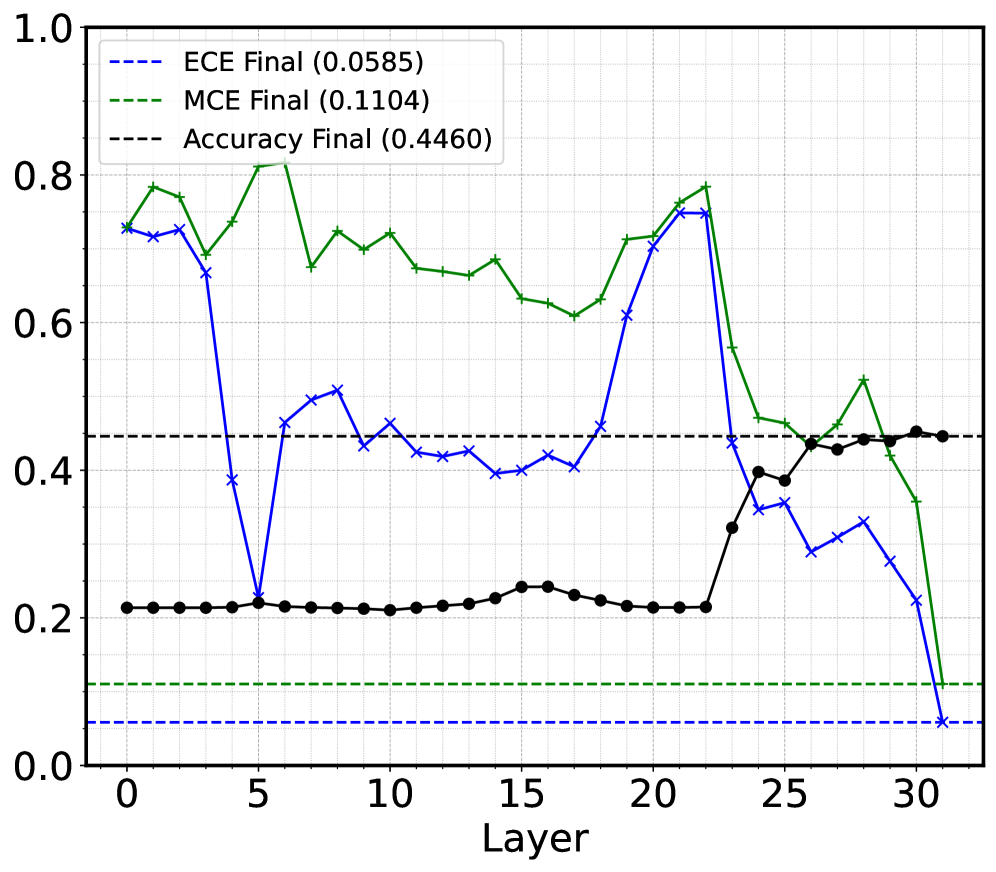
- 该论文通过分析多层网络,揭示了LLM在后期层存在置信度校正阶段,主动调整模型置信度。
- 实验发现残差流中存在低维校准方向,扰动该方向可在不损失精度的情况下提升校准效果。
📝 摘要(中文)
大型语言模型(LLM)展现出内在的校准能力,即预测概率与正确性高度一致,这与深度神经网络通常过度自信的结论相悖。现有研究将此行为归因于最后一层的特定组件,如熵神经元和unembedding矩阵的零空间。本文提供了一个互补的视角,研究校准如何在网络深度中演变。通过分析MMLU基准上的多个开源模型,我们发现了一个独特的置信度校正阶段,该阶段位于网络的上层/后层,在决策确定后主动重新校准模型置信度。此外,我们在残差流中识别出一个低维校准方向,对其进行扰动可以显著改善校准指标(ECE和MCE),而不会损害准确性。我们的研究结果表明,校准是一种分布式现象,在网络前向传播过程中形成,而不仅仅是在最终投影中,从而为LLM中置信度调节机制的运作方式提供了新的见解。
🔬 方法详解
问题定义:大型语言模型虽然表现出良好的校准能力,但现有研究主要集中在最后一层,缺乏对校准在整个网络深度中演化过程的理解。现有方法难以解释LLM如何在不同层之间调整置信度,以及哪些因素影响了校准效果。
核心思路:该论文的核心思路是深入分析LLM在不同层级的输出,特别是置信度的变化,从而揭示校准的演化过程。通过识别关键的校准阶段和方向,理解LLM如何逐步调整预测概率,使其与真实标签更加一致。
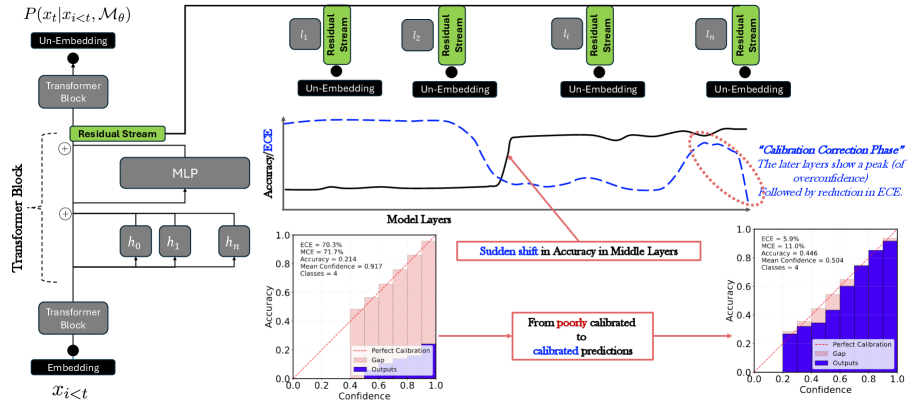
技术框架:该研究主要包括以下几个阶段:1) 选择多个开源LLM模型和MMLU基准数据集;2) 提取模型在不同层的输出,包括预测概率和隐藏状态;3) 分析置信度在不同层级的变化,识别置信度校正阶段;4) 在残差流中寻找低维校准方向,并通过扰动该方向来评估其对校准效果的影响;5) 使用ECE和MCE等指标评估校准效果。
关键创新:该论文的关键创新在于:1) 揭示了LLM中存在一个独特的置信度校正阶段,该阶段位于网络的上层/后层;2) 识别出残差流中的低维校准方向,通过扰动该方向可以有效改善校准效果,而不会损害准确性;3) 提出了校准是一种分布式现象,在网络前向传播过程中逐步形成的观点。
关键设计:该研究的关键设计包括:1) 选择MMLU作为评估基准,因为它覆盖了多个领域,可以更全面地评估模型的校准能力;2) 使用ECE和MCE作为主要的校准评估指标,这些指标可以量化预测概率与真实标签之间的偏差;3) 通过扰动残差流中的低维方向来评估其对校准效果的影响,这是一种有效的干预方法。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM在后期层存在置信度校正阶段,主动调整模型置信度。更重要的是,识别出残差流中的低维校准方向,扰动该方向可在不损失精度的情况下显著改善校准指标ECE和MCE。这些发现为理解和改进LLM的校准能力提供了新的视角。
🎯 应用场景
该研究成果可应用于提升LLM的可靠性和可信度,尤其是在需要高置信度预测的场景,如医疗诊断、金融风险评估等。通过理解和控制LLM的校准过程,可以减少模型过度自信或不确定性带来的风险,提高决策的准确性和安全性。此外,该研究还可以指导LLM的训练和优化,使其在各种任务中都能保持良好的校准状态。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated inherent calibration capabilities, where predicted probabilities align well with correctness, despite prior findings that deep neural networks are often overconfident. Recent studies have linked this behavior to specific components in the final layer, such as entropy neurons and the unembedding matrix null space. In this work, we provide a complementary perspective by investigating how calibration evolves throughout the network depth. Analyzing multiple open-weight models on the MMLU benchmark, we uncover a distinct confidence correction phase in the upper/later layers, where model confidence is actively recalibrated after decision certainty has been reached. Furthermore, we identify a low-dimensional calibration direction in the residual stream whose perturbation significantly improves calibration metrics (ECE and MCE) without harming accuracy. Our findings suggest that calibration is a distributed phenomenon, shaped throughout the network forward pass, not just in its final projection, providing new insights into how confidence-regulating mechanisms operate within LLMs.