A Comparative Analysis of LLM Adaptation: SFT, LoRA, and ICL in Data-Scarce Scenarios
作者: Bernd Bohnet, Rumen Dangovski, Kevin Swersky, Sherry Moore, Arslan Chaudhry, Kathleen Kenealy, Noah Fiedel
分类: cs.LG
发布日期: 2025-10-31 (更新: 2025-11-04)
💡 一句话要点
数据稀缺场景下LLM适应性对比分析:SFT、LoRA与ICL
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 低秩适应 上下文学习 灾难性遗忘
📋 核心要点
- 现有LLM微调方法,如全量微调,计算成本高昂且易导致灾难性遗忘,影响模型通用能力。
- 论文对比了监督微调(SFT)、LoRA和上下文学习(ICL)三种方法在数据稀缺场景下的性能。
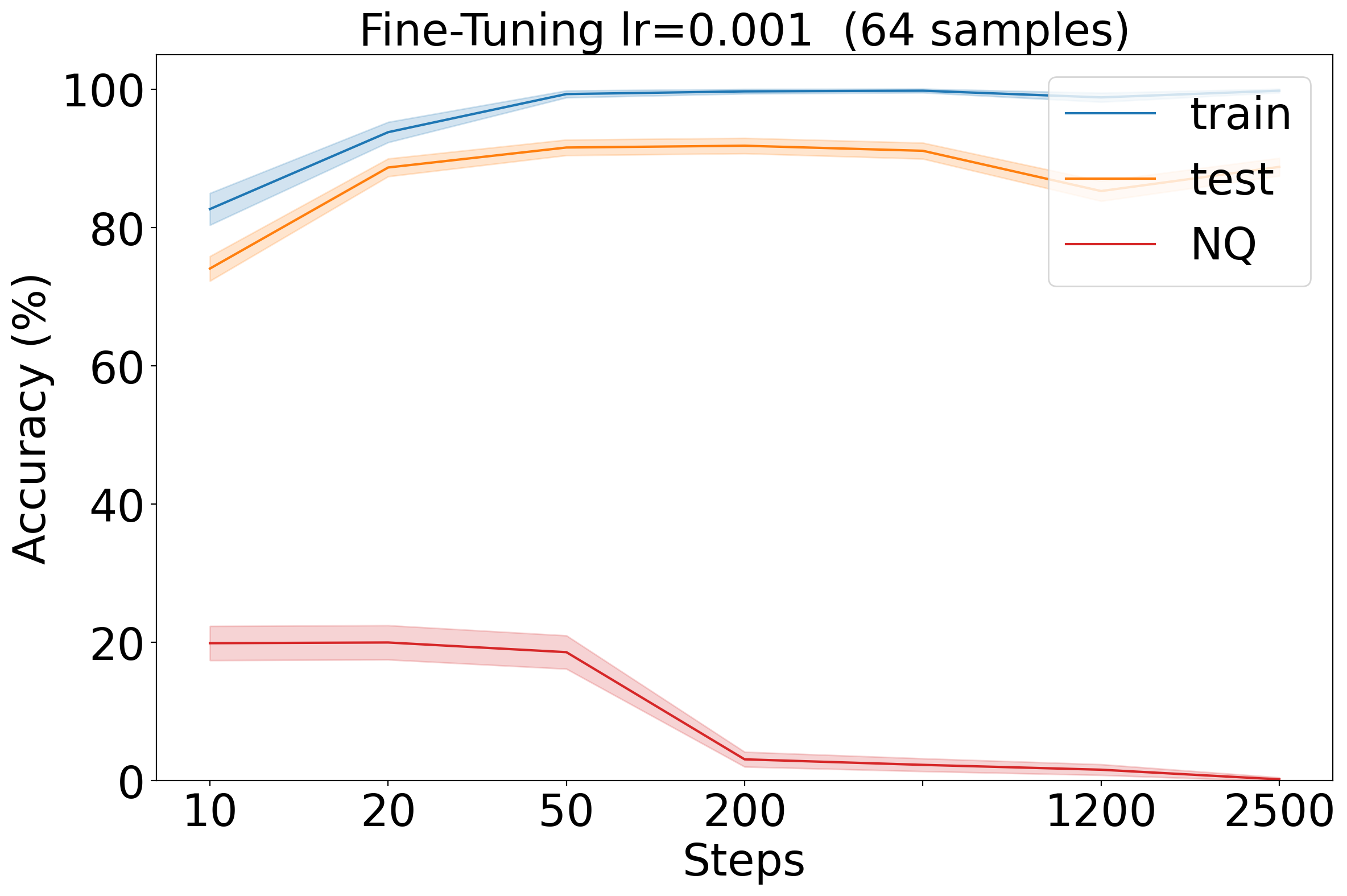
- 实验表明,LoRA在技能习得和通用知识保持之间取得了最佳平衡,SFT易发生灾难性遗忘,ICL不擅长复杂技能。
📝 摘要(中文)
大型语言模型(LLM)的卓越能力通常需要针对特定应用进行定制,这需要整合新知识或获得新技能。虽然全量微调是一种强大的适应方法,但其计算成本高昂,并可能导致通用推理能力的下降,即灾难性遗忘。目前存在一系列替代技术,每种技术都有其自身的优缺点。上下文学习(ICL)速度快,但受到上下文长度的限制,而像低秩适应(LoRA)这样的参数高效微调(PEFT)方法通过最小化参数变化提供了一个折衷方案。然而,灾难性遗忘的挑战依然存在,引发了关于针对给定任务的最佳适应策略的问题。本文对数据稀缺场景下的监督微调(SFT)、LoRA和ICL进行了比较分析。我们发现LoRA提供了最有效的平衡,成功地灌输了新技能,同时对基础模型的通用知识影响最小。相比之下,虽然SFT擅长技能习得,但它极易受到灾难性遗忘的影响。ICL在整合事实知识方面有效,但在处理复杂技能方面表现不佳。我们的研究结果为选择LLM适应策略提供了一个实用的框架。我们强调了技能习得和知识整合之间的关键区别,并阐明了任务特定性能和通用能力保持之间的权衡。
🔬 方法详解
问题定义:论文旨在解决在数据稀缺场景下,如何高效地对大型语言模型(LLM)进行适应性调整,使其能够获得新技能或整合新知识,同时避免灾难性遗忘的问题。现有方法,如全量微调,虽然有效,但计算成本高昂,且容易导致模型忘记先前学习的知识,降低其通用能力。
核心思路:论文的核心思路是通过对比分析不同的LLM适应方法,包括监督微调(SFT)、低秩适应(LoRA)和上下文学习(ICL),来确定在数据稀缺场景下,哪种方法能够在技能习得和通用知识保持之间取得最佳平衡。LoRA通过只训练少量参数来避免灾难性遗忘,而ICL则不更新模型参数,但受限于上下文长度。
技术框架:论文采用实验对比的方式,评估不同适应方法在特定任务上的性能和对通用知识的影响。具体流程包括:1)选择预训练的LLM作为基础模型;2)使用少量数据对模型进行SFT或LoRA微调;3)使用ICL方法,通过在输入中加入示例来引导模型;4)在特定任务和通用知识测试集上评估模型的性能。
关键创新:论文的关键创新在于对SFT、LoRA和ICL三种方法在数据稀缺场景下的性能进行了全面的对比分析,揭示了它们在技能习得和通用知识保持方面的不同优缺点。这为选择合适的LLM适应策略提供了重要的指导。
关键设计:论文的关键设计包括:1)精心选择的特定任务,用于评估模型的技能习得能力;2)标准的通用知识测试集,用于评估模型是否发生灾难性遗忘;3)对LoRA的秩(rank)等参数进行调整,以找到最佳的性能平衡点;4)对ICL的示例数量和选择策略进行优化,以提高其性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在数据稀缺场景下,LoRA在技能习得和通用知识保持之间取得了最佳平衡。SFT虽然在技能习得方面表现出色,但极易发生灾难性遗忘。ICL在整合事实知识方面有效,但在处理复杂技能方面表现不佳。这些发现为选择LLM适应策略提供了重要的依据。
🎯 应用场景
该研究成果可应用于各种需要对LLM进行定制化调整的场景,尤其是在数据资源有限的情况下。例如,可以用于开发特定领域的智能助手、定制化的文本生成模型,以及在医疗、金融等专业领域中应用LLM。通过选择合适的适应策略,可以有效地提高LLM在特定任务上的性能,同时保持其通用能力,从而实现更广泛的应用。
📄 摘要(原文)
The remarkable capabilities of Large Language Models (LLMs) often need to be tailored for specific applications, requiring the integration of new knowledge or the acquisition of new skills. While full fine-tuning is a powerful adaptation method, it is computationally expensive and can lead to a degradation of general reasoning abilities, a phenomenon known as catastrophic forgetting. A range of alternative techniques exists, each with its own trade-offs. In-Context Learning (ICL) is fast but limited by context length, while Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) offer a middle ground by minimizing parameter changes. However, the challenge of catastrophic forgetting persists, raising questions about the best adaptation strategy for a given task. This paper presents a comparative analysis of Supervised Finetuning (SFT), LoRA, and ICL in data-scarce scenarios. We find that LoRA provides the most effective balance, successfully instilling new skills with minimal impact on the base model's general knowledge. In contrast, while SFT excels at skill acquisition, it is highly susceptible to catastrophic forgetting. ICL is effective for incorporating factual knowledge but struggles with complex skills. Our findings offer a practical framework for selecting an LLM adaptation strategy. We highlight the critical distinction between skill acquisition and knowledge integration, clarify the trade-offs between task-specific performance and the preservation of general capabilities.