ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
作者: Zhuohan Wang, Ziwei Zhu, Ziniu Li, Congliang Chen, Yizhou Han, Yufeng Lin, Zhihang Lin, Angyang Gu, Xinglin Hu, Ruoyu Sun, Tian Ding
分类: cs.LG
发布日期: 2025-10-31
💡 一句话要点
ORGEval:基于图论的LLM优化建模能力评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 优化建模 图论 模型评估 图同构 Weisfeiler-Lehman测试 对称可分解图 Bench4Opt
📋 核心要点
- 现有基于求解器的优化模型评估方法存在不一致、不可行和计算成本高等问题,难以有效评估LLM的优化建模能力。
- ORGEval将优化模型表示为图,利用图同构测试来判断模型等价性,避免了求解器依赖和数值敏感性。
- 实验表明ORGEval能100%一致地检测模型等价性,显著优于传统方法,并用于构建Bench4Opt数据集评估LLM。
📝 摘要(中文)
工业应用中优化问题的建模需要大量的人工和领域专业知识。大型语言模型(LLM)在自动化该过程方面显示出潜力,但由于缺乏可靠的指标,评估其性能仍然很困难。现有的基于求解器的方法通常面临不一致性、不可行性问题和高计算成本。为了解决这些问题,我们提出了ORGEval,一个图论评估框架,用于评估LLM在制定线性规划和混合整数线性规划方面的能力。ORGEval将优化模型表示为图,将等价性检测简化为图同构测试。我们识别并证明了一个充分条件,即当被测试的图是对称可分解(SD)时,Weisfeiler-Lehman(WL)测试保证能正确检测同构。在此基础上,ORGEval集成了WL测试的定制变体和SD检测算法来评估模型等价性。通过关注结构等价性而不是实例级别的配置,ORGEval对数值变化具有鲁棒性。实验结果表明,我们的方法可以成功检测模型等价性,并在随机参数配置中产生100%一致的结果,同时在运行时间上显著优于基于求解器的方法,尤其是在困难问题上。利用ORGEval,我们构建了Bench4Opt数据集,并对最先进的LLM在优化建模方面进行了基准测试。我们的结果表明,尽管优化建模对所有LLM来说仍然具有挑战性,但DeepSeek-V3和Claude-Opus-4在直接提示下实现了最高的准确率,甚至优于领先的推理模型。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在优化建模方面的能力。现有基于求解器的方法,例如比较求解结果,存在对数值参数敏感、计算成本高昂以及可能出现不一致或不可行解的问题,无法准确反映LLM生成的优化模型的质量。
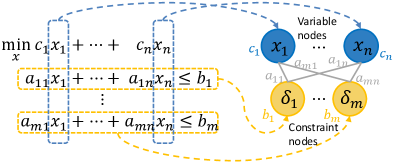
核心思路:论文的核心思路是将优化模型转化为图结构,然后通过图同构测试来判断两个模型是否等价。这种方法避免了直接求解优化问题,从而降低了计算成本,并且由于关注的是模型的结构而非具体的数值参数,因此对数值扰动具有更强的鲁棒性。
技术框架:ORGEval框架包含以下几个主要步骤:1) 将LLM生成的优化模型转化为图表示;2) 使用对称可分解(SD)检测算法判断图是否满足SD条件;3) 如果满足SD条件,则使用定制的Weisfeiler-Lehman (WL) 测试进行图同构检测;4) 根据WL测试的结果判断两个优化模型是否等价。如果图不满足SD条件,则可能需要其他图同构算法(论文中未明确说明)。
关键创新:ORGEval的关键创新在于将优化模型的等价性问题转化为图同构问题,并利用图论中的Weisfeiler-Lehman测试进行高效的等价性判断。此外,论文还提出了对称可分解(SD)的概念,并证明了在SD图上WL测试能够保证正确检测同构,从而提高了评估的可靠性。
关键设计:ORGEval的关键设计包括:1) 如何将优化模型中的变量、约束和目标函数有效地映射到图的节点和边;2) 如何定制Weisfeiler-Lehman测试以适应优化模型的图结构特点;3) 如何设计高效的对称可分解(SD)检测算法。论文中没有详细描述具体的参数设置、损失函数或网络结构,因为该方法主要依赖于图论算法。
🖼️ 关键图片


📊 实验亮点
ORGEval在模型等价性检测上实现了100%的一致性,并且在运行时间上显著优于基于求解器的方法,尤其是在复杂问题上。通过ORGEval,论文构建了Bench4Opt数据集,并发现DeepSeek-V3和Claude-Opus-4在优化建模任务上表现最佳,甚至优于一些专门的推理模型。
🎯 应用场景
ORGEval可用于评估和比较不同LLM在优化建模任务上的性能,帮助研究人员选择更适合特定优化问题的LLM。此外,该框架还可以用于自动化优化模型的生成和验证,从而降低工业界应用优化技术的门槛,加速优化算法在实际问题中的部署。
📄 摘要(原文)
Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.