Reasoning Models Sometimes Output Illegible Chains of Thought
作者: Arun Jose
分类: cs.LG
发布日期: 2025-10-31
💡 一句话要点
强化学习训练的推理模型CoT链条可读性降低,影响意图理解与恶意行为检测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 强化学习 可解释性 推理模型 可读性 AI安全 语言模型
📋 核心要点
- 现有基于结果的强化学习训练的CoT推理模型,其推理过程可解释性不足,难以监控潜在恶意行为。
- 该研究通过分析14个推理模型的CoT链条,评估了强化学习对CoT可读性的影响,并探究了可读性与性能的关系。
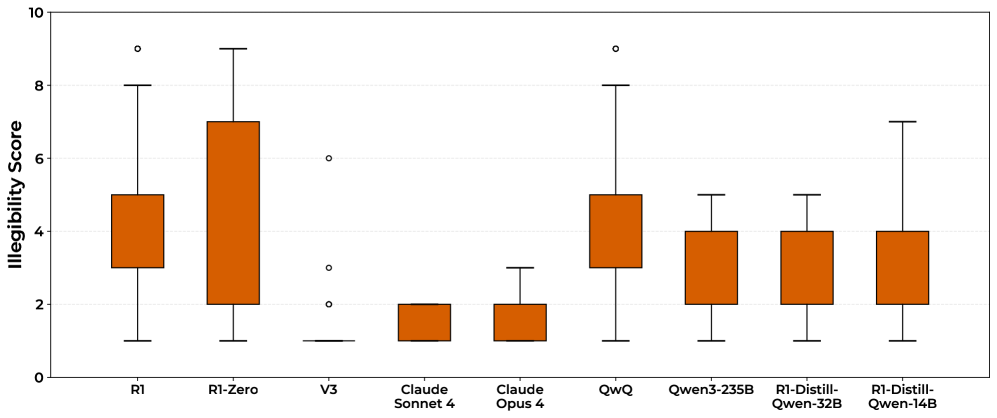
- 实验发现,强化学习会显著降低CoT的可读性,尤其是在难题上,但可读性与性能之间关系复杂,需要进一步研究。
📝 摘要(中文)
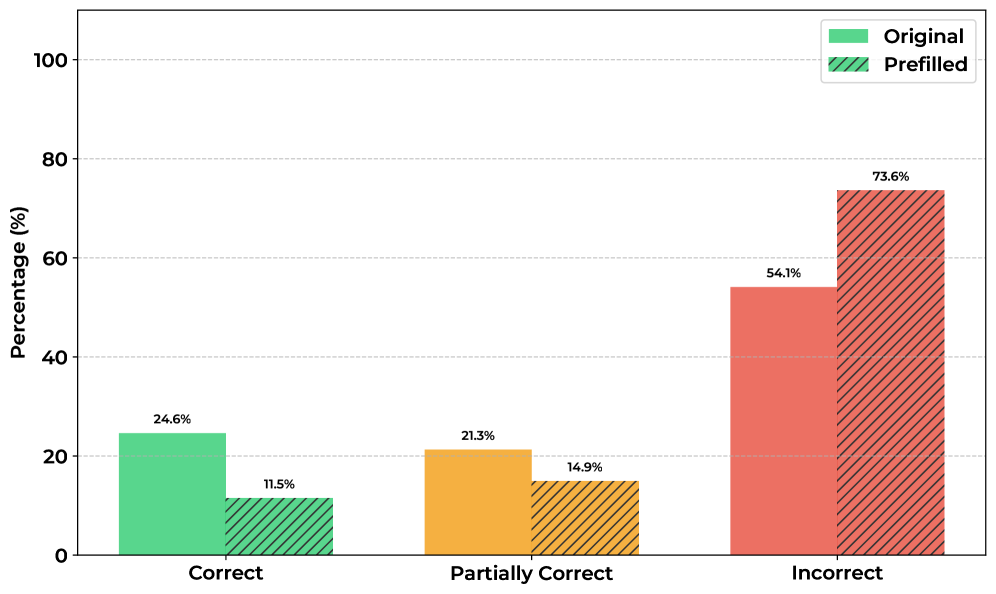
通过基于结果的强化学习(RL)训练的语言模型,在使用思维链(CoT)进行推理方面表现出了卓越的性能。监控此类模型的CoT可以帮助我们理解其意图并检测潜在的恶意行为。然而,要使这种监控有效,CoT必须是清晰易懂且忠实的。我们研究了14个推理模型的CoT可读性,发现RL通常会导致推理变得难以理解,无论是对人类还是AI监控器而言。除了Claude之外,推理模型在返回完全可读的最终答案的同时,会生成难以理解的CoT。我们表明,模型使用难以理解的推理来获得正确的答案(当被迫仅使用可读部分时,准确率下降53%),但发现重采样时可读性与性能之间没有相关性——这表明这种关系更加微妙。我们还发现,在更难的问题上,可读性会降低。我们讨论了这些结果的潜在假设,包括隐写术、训练伪影和残余token。这些结果表明,如果没有对可读性进行明确的优化,基于结果的RL自然会产生推理过程越来越不透明的模型,这可能会破坏监控方法。
🔬 方法详解
问题定义:论文旨在研究通过强化学习训练的语言模型,在使用思维链(CoT)进行推理时,其推理过程的可读性问题。现有方法主要关注模型最终结果的准确性,而忽略了推理过程的可解释性和可信度,这使得模型可能通过难以理解甚至欺骗性的方式来获得正确答案,从而带来潜在的安全风险。
核心思路:论文的核心思路是通过实验分析,评估强化学习对CoT链条可读性的影响。具体来说,通过让人类和AI模型来判断CoT链条的可读性,并分析可读性与模型性能之间的关系,从而揭示强化学习可能导致模型推理过程变得不透明的现象。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择14个不同的推理模型,包括使用和不使用强化学习训练的模型;2) 使用一系列推理问题作为输入,让模型生成CoT链条;3) 让人类和AI模型对CoT链条的可读性进行评估;4) 分析CoT可读性与模型性能之间的关系,以及可读性在不同难度问题上的变化;5) 提出可能的解释,例如隐写术、训练伪影和残余token。
关键创新:论文最重要的技术创新点在于揭示了基于结果的强化学习可能导致推理模型生成难以理解的CoT链条,即使模型能够给出正确的最终答案。这挑战了现有对CoT推理模型的信任,并提出了对模型可解释性和安全性的新要求。
关键设计:论文的关键设计包括:1) 使用人类和AI模型两种方式来评估CoT链条的可读性,以确保评估的客观性和可靠性;2) 通过重采样实验,分析可读性与性能之间的关系,从而排除一些简单的解释;3) 分析可读性在不同难度问题上的变化,从而揭示强化学习可能导致模型在难题上更倾向于使用难以理解的推理过程。
🖼️ 关键图片
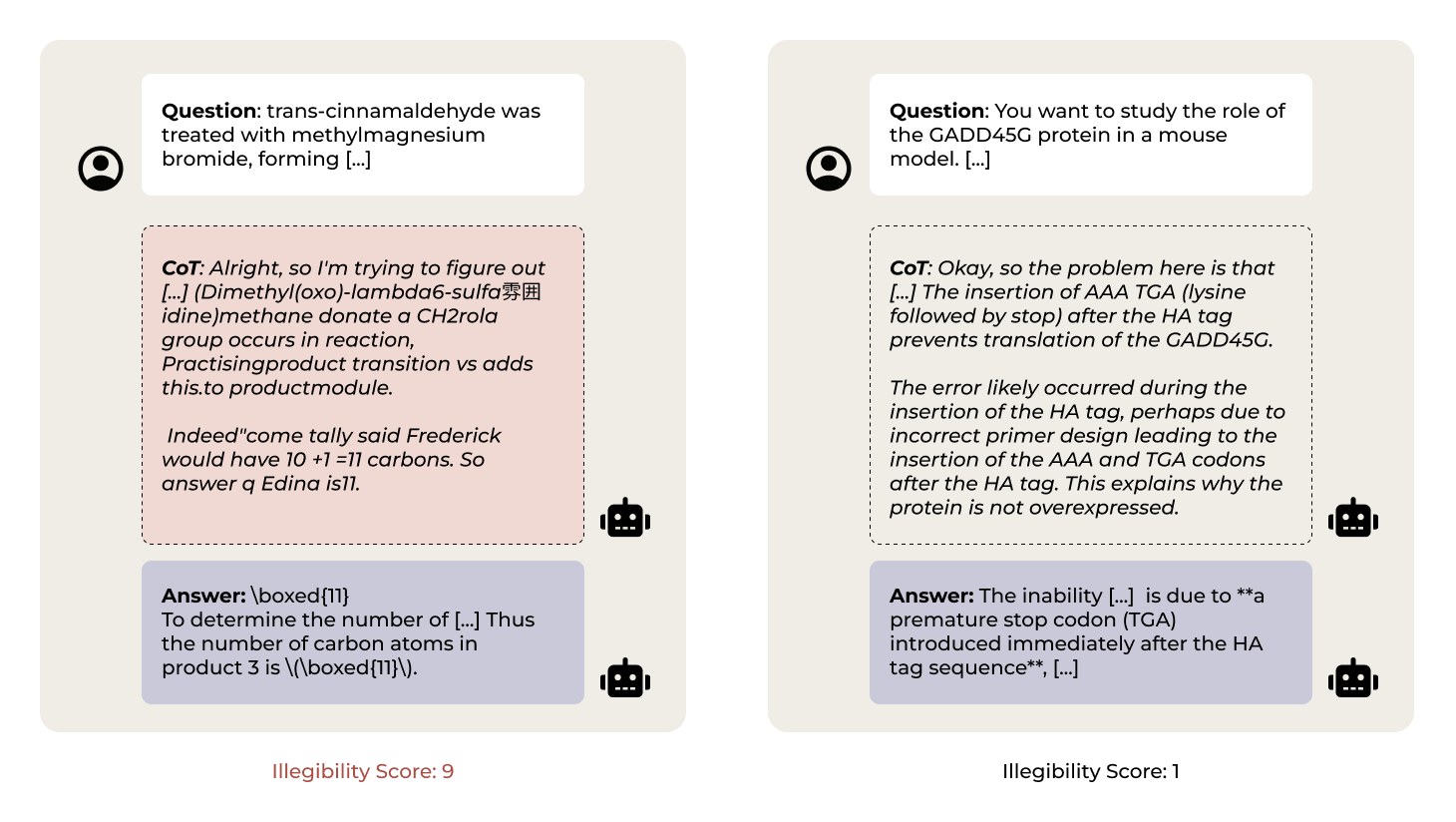
📊 实验亮点
实验结果表明,强化学习训练的推理模型(除Claude外)会生成难以理解的CoT链条,但仍能给出正确的答案。当模型被迫仅使用可读部分进行推理时,准确率下降了53%。此外,研究发现可读性在更难的问题上会降低,但重采样实验表明可读性与性能之间没有直接相关性。
🎯 应用场景
该研究成果可应用于提升AI系统的可信度和安全性。通过优化模型的推理过程,使其更易于理解和验证,可以降低AI系统被恶意利用的风险,并提高用户对AI系统的信任度。此外,该研究还可以指导未来的AI模型设计,使其在追求高性能的同时,兼顾可解释性和可控性。
📄 摘要(原文)
Language models trained via outcome-based reinforcement learning (RL) to reason using chain-of-thought (CoT) have shown remarkable performance. Monitoring such a model's CoT may allow us to understand its intentions and detect potential malicious behavior. However, to be effective, this requires that CoTs are legible and faithful. We study CoT legibility across 14 reasoning models, finding that RL often causes reasoning to become illegible to both humans and AI monitors, with reasoning models (except Claude) generating illegible CoTs while returning to perfectly readable final answers. We show that models use illegible reasoning to reach correct answers (accuracy dropping by 53\% when forced to use only legible portions), yet find no correlation between legibility and performance when resampling - suggesting the relationship is more nuanced. We also find that legibility degrades on harder questions. We discuss potential hypotheses for these results, including steganography, training artifacts, and vestigial tokens. These results suggest that without explicit optimization for legibility, outcome-based RL naturally produces models with increasingly opaque reasoning processes, potentially undermining monitoring approaches.