Soft Task-Aware Routing of Experts for Equivariant Representation Learning
作者: Jaebyeong Jeon, Hyeonseo Jang, Jy-yong Sohn, Kibok Lee
分类: cs.LG, cs.AI, cs.CV, stat.ML
发布日期: 2025-10-31
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出软任务感知路由专家(STAR),提升等变表征学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 等变表征学习 不变表征学习 软路由 任务感知 迁移学习
📋 核心要点
- 现有方法在联合学习等变和不变表征时,忽略了二者之间的信息共享,导致特征冗余和模型效率降低。
- 论文提出软任务感知路由(STAR)机制,将投影头视为专家,动态路由以学习共享和特定任务的信息。
- 实验表明,STAR能有效降低不变和等变嵌入间的相关性,并在多个迁移学习任务上取得性能提升。
📝 摘要(中文)
等变表征学习旨在捕捉表征空间中由输入变换引起的变化,而不变表征学习则通过忽略这些变换来编码语义信息。最近的研究表明,联合学习这两种类型的表征通常对下游任务有益,通常采用分离的投影头。然而,这种设计忽略了不变学习和等变学习之间共享的信息,导致冗余的特征学习和模型容量的低效利用。为了解决这个问题,我们引入了软任务感知路由(STAR),这是一种针对投影头的路由策略,将其建模为专家。STAR引导专家专注于捕获共享或特定于任务的信息,从而减少冗余特征学习。我们通过观察不变嵌入和等变嵌入之间较低的典型相关性来验证这种效果。实验结果表明,在不同的迁移学习任务中,性能得到了一致的提升。代码可在https://github.com/YonseiML/star获取。
🔬 方法详解
问题定义:论文旨在解决等变表征学习中,联合学习不变和等变表征时存在的冗余特征学习问题。现有方法通常采用分离的投影头来处理这两种表征,忽略了它们之间的信息共享,导致模型容量利用率低,学习效率不高。
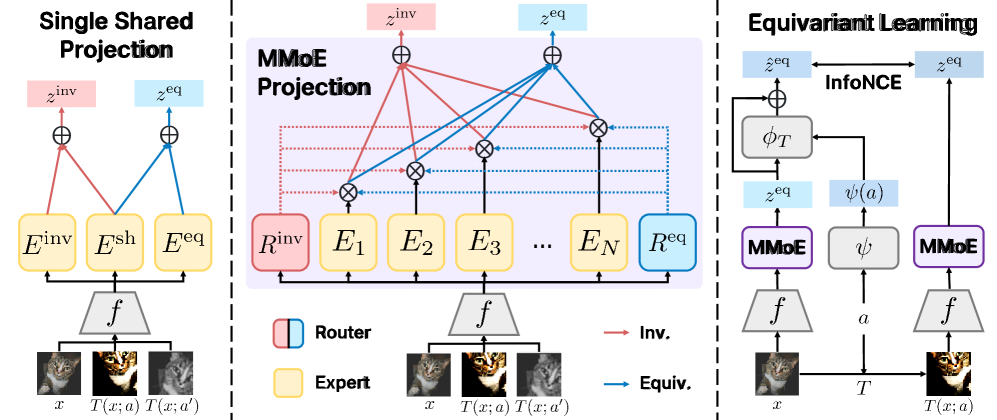
核心思路:论文的核心思路是将不同的投影头视为“专家”,每个专家负责学习特定的特征(共享或任务特定)。通过软路由机制,动态地将输入特征分配给不同的专家,从而使专家能够专注于学习不同的信息,减少冗余。
技术框架:整体框架包括一个共享的特征提取器和一个由多个“专家”组成的路由网络。特征提取器负责从输入数据中提取通用特征。路由网络根据输入特征的特性,动态地将特征分配给不同的专家。每个专家对应一个投影头,负责学习不变或等变的表征。最终的表征是所有专家输出的加权组合,权重由路由网络决定。
关键创新:最重要的创新点在于软任务感知路由机制(STAR)。与传统的硬路由不同,STAR允许输入特征同时被多个专家处理,并通过权重来控制每个专家的贡献。这种软路由方式能够更好地利用模型容量,并允许专家之间进行信息共享。
关键设计:STAR的关键设计包括:1) 使用Gumbel-Softmax技巧来实现可微分的软路由;2) 设计损失函数,鼓励专家学习不同的特征,例如,通过最小化不变和等变嵌入之间的典型相关性;3) 调整路由网络的结构,使其能够有效地捕捉输入特征的特性,并做出合理的路由决策。
🖼️ 关键图片

📊 实验亮点
实验结果表明,STAR方法能够有效降低不变和等变嵌入之间的典型相关性,验证了其减少冗余特征学习的效果。在多个迁移学习任务上,STAR方法均取得了显著的性能提升,例如,在ImageNet数据集上,相比于基线方法,STAR方法在目标检测任务上取得了平均精度(mAP)的提升。
🎯 应用场景
该研究成果可应用于各种需要同时学习不变和等变表征的领域,例如,3D目标识别、医学图像分析、机器人感知等。通过减少冗余特征学习,可以提高模型的效率和泛化能力,从而在资源受限的环境中部署更强大的模型。未来的研究可以探索更复杂的路由策略和专家网络结构,以进一步提升性能。
📄 摘要(原文)
Equivariant representation learning aims to capture variations induced by input transformations in the representation space, whereas invariant representation learning encodes semantic information by disregarding such transformations. Recent studies have shown that jointly learning both types of representations is often beneficial for downstream tasks, typically by employing separate projection heads. However, this design overlooks information shared between invariant and equivariant learning, which leads to redundant feature learning and inefficient use of model capacity. To address this, we introduce Soft Task-Aware Routing (STAR), a routing strategy for projection heads that models them as experts. STAR induces the experts to specialize in capturing either shared or task-specific information, thereby reducing redundant feature learning. We validate this effect by observing lower canonical correlations between invariant and equivariant embeddings. Experimental results show consistent improvements across diverse transfer learning tasks. The code is available at https://github.com/YonseiML/star.