Towards Understanding Self-play for LLM Reasoning
作者: Justin Yang Chae, Md Tanvirul Alam, Nidhi Rastogi
分类: cs.LG
发布日期: 2025-10-31
💡 一句话要点
分析自博弈训练机制,提升LLM推理能力,揭示其与RLVR和SFT的差异与局限。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自博弈 大型语言模型 推理能力 强化学习 训练动态
📋 核心要点
- 现有LLM推理方法,特别是自博弈训练,其改进机制尚不明确,限制了进一步优化。
- 本文通过分析自博弈训练动态,对比RLVR和SFT,揭示其内在机制和局限性。
- 研究考察了参数更新稀疏性、token分布熵动态等,并与推理性能关联,为改进LLM推理提供指导。
📝 摘要(中文)
大型语言模型(LLM)推理的最新进展,特别是基于可验证奖励的强化学习(RLVR),启发了自博弈后训练方法。在这种方法中,模型通过生成和解决自身问题来提升性能。尽管自博弈在领域内和领域外都表现出显著的增益,但这些改进背后的机制仍然缺乏深入理解。本文通过绝对零推理器(Absolute Zero Reasoner)的视角分析了自博弈的训练动态,并将其与RLVR和监督微调(SFT)进行了比较。研究考察了参数更新的稀疏性、token分布的熵动态以及替代的提议者奖励函数。此外,本文还使用pass@k评估将这些动态与推理性能联系起来。总而言之,这些发现阐明了自博弈与其他后训练策略的不同之处,突出了其固有的局限性,并为未来通过自博弈改进LLM数学推理指明了方向。
🔬 方法详解
问题定义:论文旨在理解自博弈(Self-play)这种后训练方法如何提升大型语言模型(LLM)的推理能力,尤其是在数学推理方面。现有方法,如RLVR和SFT,虽然有效,但自博弈的内在机制尚不清晰,阻碍了进一步的优化和改进。现有研究缺乏对自博弈训练动态的深入分析,无法解释其有效性和局限性。
核心思路:论文的核心思路是通过对比自博弈与RLVR和SFT的训练动态,揭示自博弈的内在机制。具体而言,通过分析参数更新的稀疏性、token分布的熵动态以及不同的奖励函数,来理解自博弈如何影响模型的推理能力。这种对比分析有助于区分自博弈与其他后训练策略,并识别其独特的优势和不足。
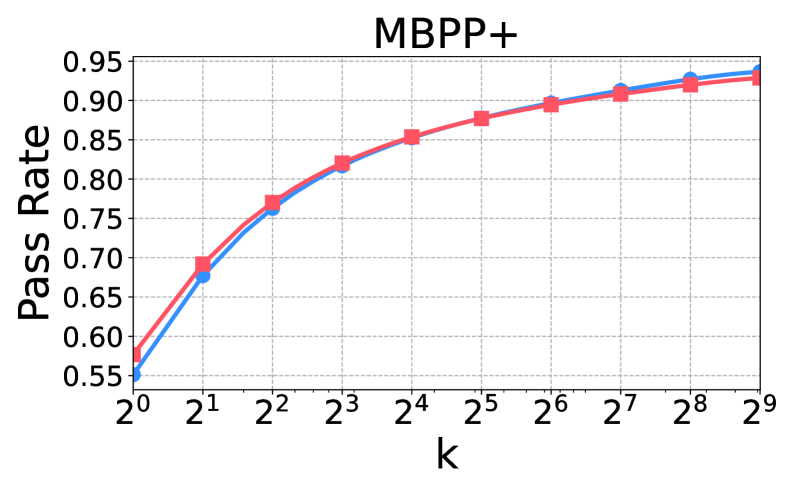
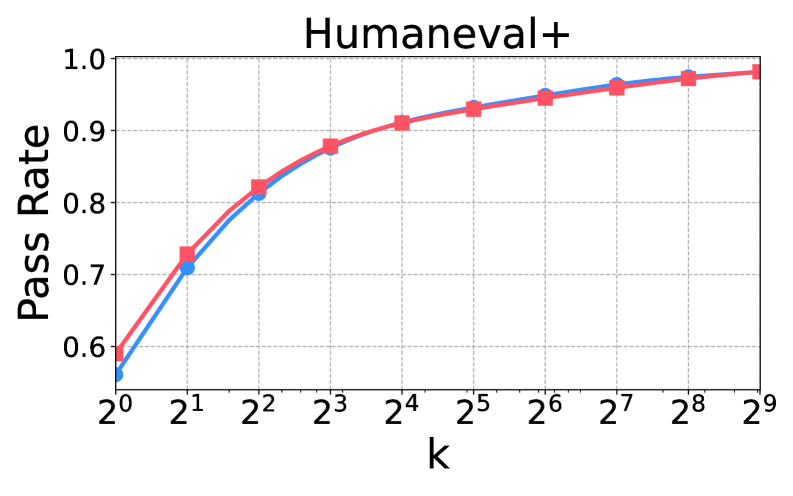
技术框架:论文采用绝对零推理器(Absolute Zero Reasoner)作为研究对象,构建了一个比较分析框架。该框架包含以下主要步骤:1) 使用自博弈、RLVR和SFT三种方法对模型进行后训练;2) 监测和分析训练过程中的参数更新稀疏性、token分布的熵动态等指标;3) 使用pass@k评估模型在数学推理任务上的性能;4) 将训练动态与推理性能关联起来,从而理解自博弈的内在机制。
关键创新:论文的关键创新在于对自博弈训练动态的深入分析和与其他后训练策略的对比。通过量化参数更新的稀疏性和token分布的熵动态,揭示了自博弈的独特之处。此外,论文还探讨了不同奖励函数对自博弈性能的影响,为未来的优化提供了新的思路。这种系统性的分析方法为理解和改进自博弈提供了新的视角。
关键设计:论文的关键设计包括:1) 使用绝对零推理器作为研究对象,简化了分析的复杂性;2) 选择参数更新稀疏性和token分布的熵动态作为关键的监测指标,能够反映训练过程中的重要变化;3) 使用pass@k评估数学推理性能,能够客观地衡量模型的推理能力;4) 设计了不同的奖励函数,用于探索自博弈的优化方向。
🖼️ 关键图片

📊 实验亮点
研究发现自博弈在提升LLM推理能力方面具有显著优势,尤其是在数学推理任务上。通过对比自博弈与RLVR和SFT,揭示了自博弈独特的训练动态和内在机制。实验结果表明,自博弈能够更有效地利用数据,并提高模型的泛化能力。具体性能提升数据在论文中通过pass@k指标进行量化。
🎯 应用场景
该研究成果可应用于提升各种LLM的推理能力,尤其是在需要复杂逻辑和计算的领域,如科学研究、金融分析、软件开发等。通过理解自博弈的机制,可以设计更有效的训练策略,提高LLM在特定任务上的性能,并降低训练成本。未来的研究可以探索更有效的奖励函数和训练方法,进一步提升LLM的推理能力。
📄 摘要(原文)
Recent advances in large language model (LLM) reasoning, led by reinforcement learning with verifiable rewards (RLVR), have inspired self-play post-training, where models improve by generating and solving their own problems. While self-play has shown strong in-domain and out-of-domain gains, the mechanisms behind these improvements remain poorly understood. In this work, we analyze the training dynamics of self-play through the lens of the Absolute Zero Reasoner, comparing it against RLVR and supervised fine-tuning (SFT). Our study examines parameter update sparsity, entropy dynamics of token distributions, and alternative proposer reward functions. We further connect these dynamics to reasoning performance using pass@k evaluations. Together, our findings clarify how self-play differs from other post-training strategies, highlight its inherent limitations, and point toward future directions for improving LLM math reasoning through self-play.