RL-Exec: Impact-Aware Reinforcement Learning for Opportunistic Optimal Liquidation, Outperforms TWAP and a Book-Liquidity VWAP on BTC-USD Replays
作者: Enzo Duflot, Stanislas Robineau
分类: q-fin.ST, cs.LG, q-fin.TR
发布日期: 2025-10-30
备注: 8 pages main text, 3 appendix pages, 10 figures
💡 一句话要点
RL-Exec:基于强化学习的冲击感知型最优清算策略,优于TWAP和Book-Liquidity VWAP
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 最优清算 限价订单簿 市场冲击 交易执行 PPO 加密货币交易
📋 核心要点
- 现有交易执行策略未能充分考虑市场冲击和交易成本,导致清算效率低下。
- 提出RL-Exec,利用强化学习在模拟环境中学习最优清算策略,考虑了市场冲击、费用和延迟。
- 实验表明,RL-Exec在不同时间范围内显著优于TWAP和VWAP等基线策略,尤其在长时程下提升显著。
📝 摘要(中文)
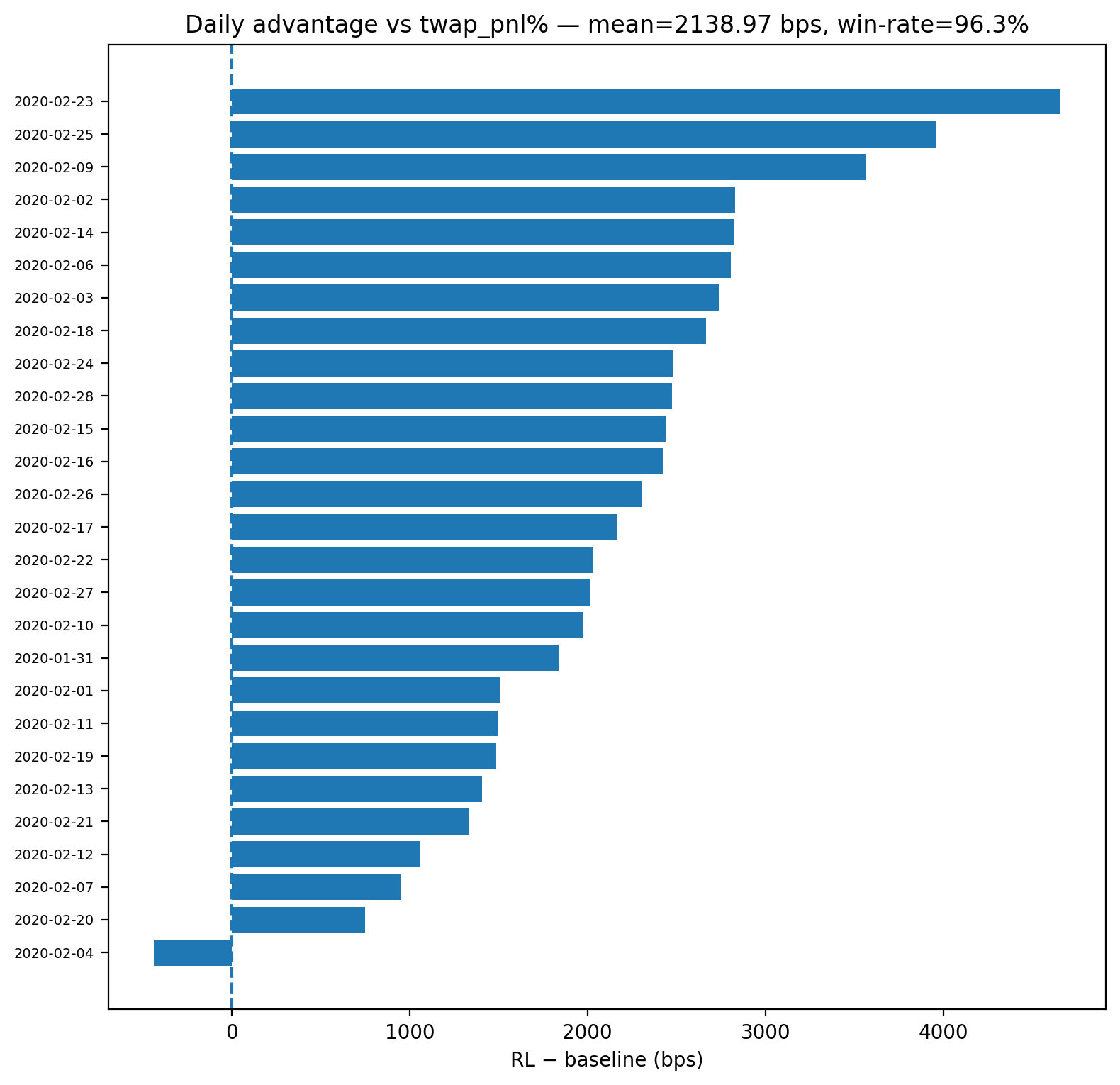
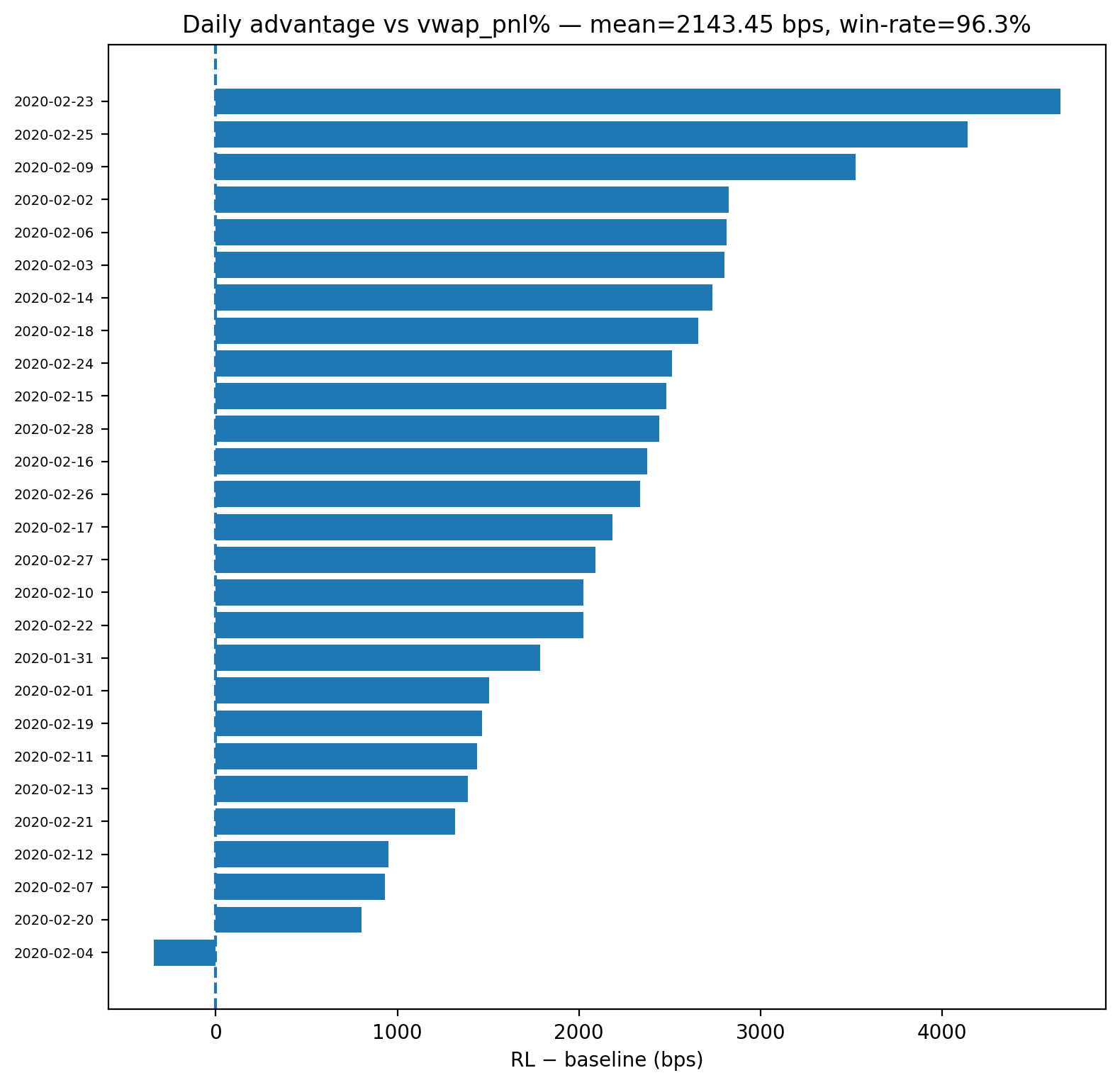
本文研究了在BTC-USD限价订单簿(LOB)上,固定期限内的机会型最优清算问题。我们提出了RL-Exec,一个基于PPO的智能体,它在历史回放数据上进行训练,并增强了内生瞬时冲击(弹性)、部分成交、做市商/吃单者费用和延迟。该策略观察深度为20的LOB特征以及微观结构指标,并在仅卖出库存约束下行动,以达到剩余目标。评估遵循严格的时间分割(训练:2020年1月;测试:2020年2月)和每日协议:对于每个测试日,我们运行十个独立的开始时间,并聚合到单个每日分数,避免伪复制。我们将该智能体与(i)TWAP和(ii)一种类似VWAP的基线进行比较,该基线使用相反侧订单簿流动性(前20个级别)进行分配,两者均在相同的时间戳和成本下执行。统计推断使用单侧Wilcoxon符号秩检验,对每日RL-基线差异进行Benjamini-Hochberg FDR校正和bootstrap置信区间。在2020年2月的测试集中,RL-Exec显著优于两个基线,并且差距随着执行期限的增加而增加(30分钟时+2-3个基点,60分钟时+7-8个基点,120分钟时+23个基点)。
🔬 方法详解
问题定义:论文旨在解决在限价订单簿上,如何以最优方式清算一定数量的BTC,同时最大化收益。现有方法,如TWAP和VWAP,通常忽略了交易本身对市场的影响(市场冲击),以及交易费用和延迟等因素,导致次优的清算效果。
核心思路:论文的核心在于使用强化学习(RL)来学习最优的清算策略。通过构建一个模拟交易环境,智能体可以在其中学习如何在考虑市场冲击、交易费用和延迟的情况下,以最佳方式执行交易。这种方法允许智能体根据实时市场状况动态调整其交易策略,从而实现更好的清算效果。
技术框架:RL-Exec使用PPO(Proximal Policy Optimization)算法作为其强化学习框架。整体流程如下:1. 构建模拟环境,该环境模拟了BTC-USD限价订单簿,并考虑了市场冲击、部分成交、做市商/吃单者费用和延迟。2. 使用历史数据训练PPO智能体,智能体观察LOB深度和微观结构指标,并采取行动(卖出一定数量的BTC)。3. 智能体的目标是最大化清算收益,同时满足库存约束。4. 在测试集上评估智能体的性能,并与TWAP和VWAP等基线策略进行比较。
关键创新:该论文的关键创新在于将强化学习应用于最优清算问题,并构建了一个考虑了市场冲击、交易费用和延迟的模拟环境。与传统的交易策略相比,RL-Exec能够更好地适应市场变化,并实现更高的清算收益。此外,论文还采用了严格的评估方法,避免了伪复制,并使用了统计推断来验证结果的显著性。
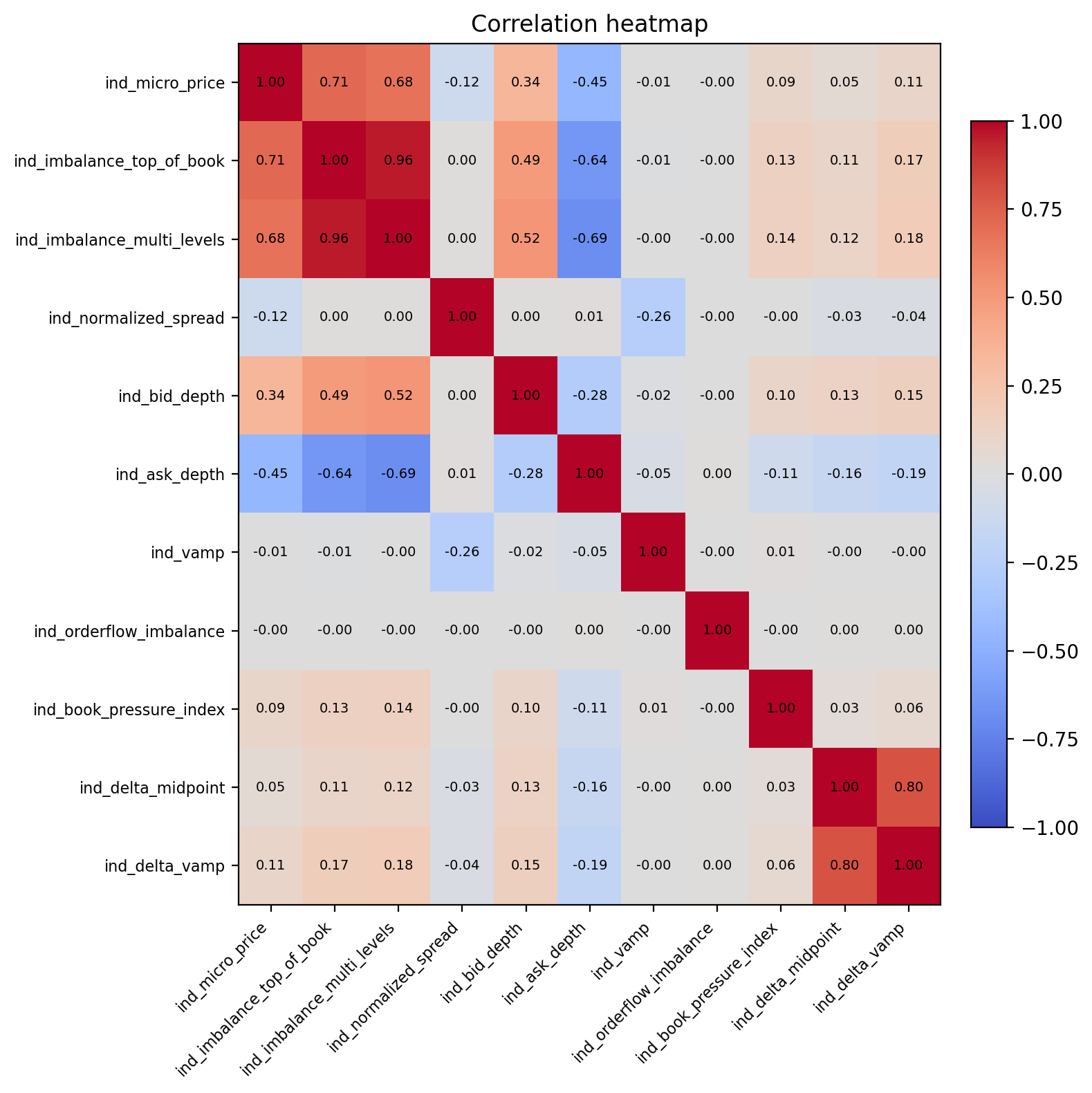
关键设计:智能体观察深度为20的LOB特征以及微观结构指标。动作空间是卖出一定数量的BTC。奖励函数旨在最大化清算收益,并考虑了交易费用和延迟。PPO算法用于训练智能体,并使用clip ratio来限制策略更新的幅度,以保证训练的稳定性。使用了Benjamini-Hochberg FDR校正和bootstrap置信区间进行统计推断。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RL-Exec在2020年2月的测试集中显著优于TWAP和Book-Liquidity VWAP基线。在30分钟的执行期限内,RL-Exec的性能提升了2-3个基点;在60分钟的执行期限内,性能提升了7-8个基点;在120分钟的执行期限内,性能提升了高达23个基点,表明RL-Exec在长时程交易中具有显著优势。
🎯 应用场景
该研究成果可应用于加密货币交易、股票交易等金融市场,为交易者提供更优的自动交易执行策略,降低交易成本,提高收益。未来可扩展到更复杂的交易场景,如多资产交易、算法交易等,具有广阔的应用前景。
📄 摘要(原文)
We study opportunistic optimal liquidation over fixed deadlines on BTC-USD limit-order books (LOB). We present RL-Exec, a PPO agent trained on historical replays augmented with endogenous transient impact (resilience), partial fills, maker/taker fees, and latency. The policy observes depth-20 LOB features plus microstructure indicators and acts under a sell-only inventory constraint to reach a residual target. Evaluation follows a strict time split (train: Jan-2020; test: Feb-2020) and a per-day protocol: for each test day we run ten independent start times and aggregate to a single daily score, avoiding pseudo-replication. We compare the agent to (i) TWAP and (ii) a VWAP-like baseline allocating using opposite-side order-book liquidity (top-20 levels), both executed on identical timestamps and costs. Statistical inference uses one-sided Wilcoxon signed-rank tests on daily RL-baseline differences with Benjamini-Hochberg FDR correction and bootstrap confidence intervals. On the Feb-2020 test set, RL-Exec significantly outperforms both baselines and the gap increases with the execution horizon (+2-3 bps at 30 min, +7-8 bps at 60 min, +23 bps at 120 min). Code: github.com/Giafferri/RL-Exec