Pelican-VL 1.0: A Foundation Brain Model for Embodied Intelligence
作者: Yi Zhang, Che Liu, Xiancong Ren, Hanchu Ni, Shuai Zhang, Zeyuan Ding, Jiayu Hu, Hanzhe Shan, Zhenwei Niu, Zhaoyang Liu, Shuang Liu, Yue Zhao, Junbo Qi, Qinfan Zhang, Dengjie Li, Yidong Wang, Jiachen Luo, Yong Dai, Zenglin Xu, Bin Shen, Qifan Wang, Jian Tang, Xiaozhu Ju
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-30 (更新: 2025-11-14)
💡 一句话要点
Pelican-VL 1.0:用于具身智能的开源基础大脑模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 大脑模型 多模态学习 强化学习 刻意练习
📋 核心要点
- 现有具身智能模型在数据质量和训练效率上存在瓶颈,难以充分利用大规模数据。
- Pelican-VL 1.0 通过 metaloop 提炼高质量数据集,并采用 DPPO 框架进行刻意练习,提升模型性能。
- 实验表明,Pelican-VL 1.0 性能超越同等规模开源模型,并与领先的专有系统在具身基准测试中表现相当。
📝 摘要(中文)
本报告介绍了Pelican-VL 1.0,这是一个新的开源具身大脑模型系列,参数规模从70亿到720亿不等。我们的明确目标是:将强大的智能嵌入到各种具身环境中。Pelican-VL 1.0是目前最大规模的开源具身多模态大脑模型。其核心优势在于数据能力和智能自适应学习机制的深度集成。具体来说,metaloop从包含40亿+ tokens 的原始数据集中提炼出了高质量的数据集。Pelican-VL 1.0 在一个包含 1000+ A800 GPU 的大型集群上进行训练,每个 checkpoint 消耗超过 50k+ A800 GPU-hours。这使得其性能比基础模型提升了 20.3%,并且比 100B 级别的开源模型高出 10.6%,在著名的具身基准测试中与领先的专有系统相媲美。我们建立了一个受人类元认知启发的全新框架 DPPO(Deliberate Practice Policy Optimization),用于训练 Pelican-VL 1.0。我们将其操作化为一个 metaloop,教导 AI 进行刻意练习,这是一个 RL-Refine-Diagnose-SFT 循环。
🔬 方法详解
问题定义:现有具身智能模型训练面临数据质量不高和训练效率低下的问题。大规模原始数据包含大量噪声,直接训练会导致模型性能下降。此外,传统的强化学习方法难以有效探索复杂的具身环境,导致训练效率低下。
核心思路:Pelican-VL 1.0 的核心思路是利用 metaloop 提炼高质量数据集,并采用受人类元认知启发的 DPPO 框架进行训练。通过 metaloop,模型可以从原始数据中学习如何选择和过滤高质量数据,从而提高数据利用率。DPPO 框架则模拟人类的刻意练习过程,通过强化学习、精炼、诊断和监督微调的循环,不断提升模型在具身环境中的表现。
技术框架:Pelican-VL 1.0 的训练框架主要包含两个关键模块:metaloop 数据提炼模块和 DPPO 训练模块。metaloop 负责从大规模原始数据集中提炼高质量数据集,DPPO 模块则利用提炼后的数据集进行模型训练。DPPO 模块包含四个阶段:强化学习(RL)、精炼(Refine)、诊断(Diagnose)和监督微调(SFT)。RL 阶段用于探索环境,Refine 阶段用于优化策略,Diagnose 阶段用于分析模型表现,SFT 阶段用于提升模型泛化能力。
关键创新:Pelican-VL 1.0 的关键创新在于 DPPO 框架,该框架模拟了人类的刻意练习过程,通过不断迭代优化,显著提升了模型在具身环境中的表现。与传统的强化学习方法相比,DPPO 框架能够更有效地探索复杂环境,并学习到更鲁棒的策略。此外,metaloop 数据提炼模块也提高了数据利用率,使得模型能够从大规模原始数据中学习到更多有用的信息。
关键设计:DPPO 框架中的强化学习阶段采用 PPO 算法,奖励函数的设计需要仔细考虑,以引导模型学习到期望的行为。精炼阶段采用行为克隆方法,利用专家数据对策略进行微调。诊断阶段则通过分析模型的行为,发现潜在的问题并进行改进。监督微调阶段则利用高质量的数据集,提升模型的泛化能力。具体的参数设置和网络结构需要根据具体的具身任务进行调整。
🖼️ 关键图片

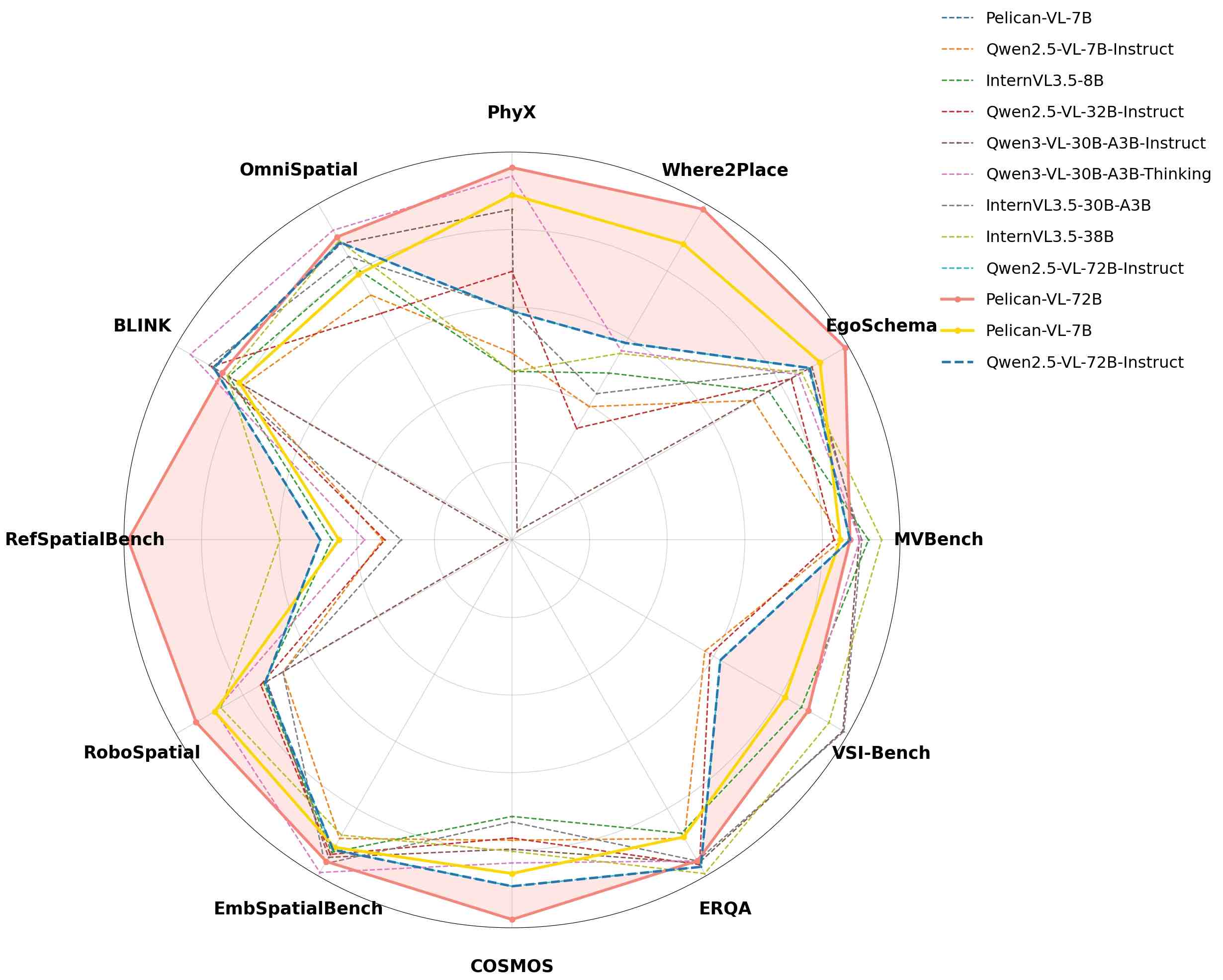
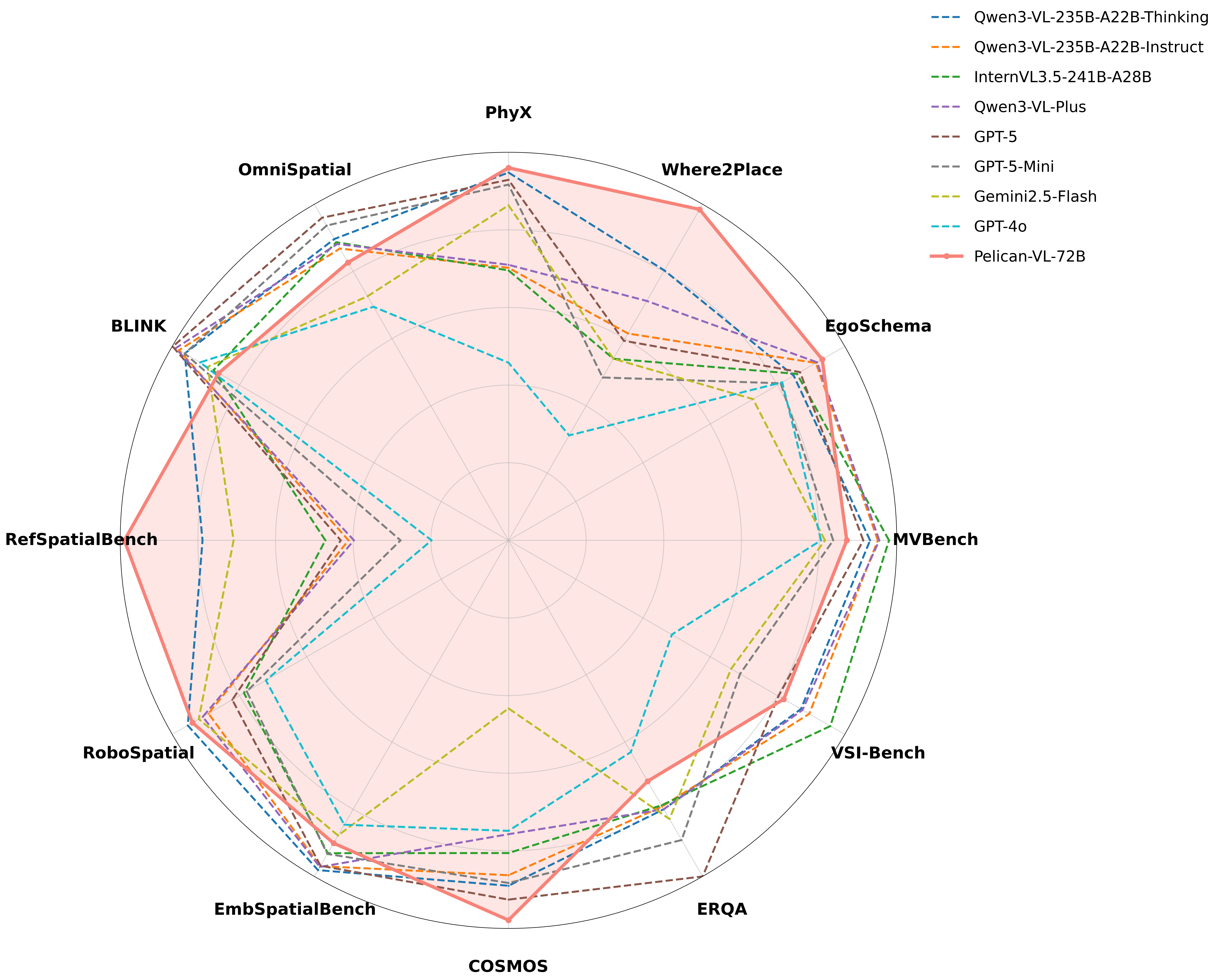
📊 实验亮点
Pelican-VL 1.0 在具身基准测试中表现出色,性能比基础模型提升了 20.3%,并且比 100B 级别的开源模型高出 10.6%,与领先的专有系统相媲美。这些结果表明,Pelican-VL 1.0 在数据质量和训练效率方面取得了显著进展,为具身智能领域的研究提供了新的思路。
🎯 应用场景
Pelican-VL 1.0 可应用于各种具身智能场景,例如机器人导航、物体操作、人机协作等。该模型能够帮助机器人更好地理解环境,并做出更智能的决策。此外,Pelican-VL 1.0 还可以用于虚拟现实和增强现实等领域,提升用户体验。未来,该模型有望推动具身智能技术的广泛应用,并为人类生活带来更多便利。
📄 摘要(原文)
This report presents Pelican-VL 1.0, a new family of open-source embodied brain models with parameter scales ranging from 7 billion to 72 billion. Our explicit mission is clearly stated as: To embed powerful intelligence into various embodiments. Pelican-VL 1.0 is currently the largest-scale open-source embodied multimodal brain model. Its core advantage lies in the in-depth integration of data power and intelligent adaptive learning mechanisms. Specifically, metaloop distilled a high-quality dataset from a raw dataset containing 4+ billion tokens. Pelican-VL 1.0 is trained on a large-scale cluster of 1000+ A800 GPUs, consuming over 50k+ A800 GPU-hours per checkpoint. This translates to a 20.3% performance uplift from its base model and outperforms 100B-level open-source counterparts by 10.6%, placing it on par with leading proprietary systems on well-known embodied benchmarks. We establish a novel framework, DPPO (Deliberate Practice Policy Optimization), inspired by human metacognition to train Pelican-VL 1.0. We operationalize this as a metaloop that teaches the AI to practice deliberately, which is a RL-Refine-Diagnose-SFT loop.