Limits of Generalization in RLVR: Two Case Studies in Mathematical Reasoning
作者: Md Tanvirul Alam, Nidhi Rastogi
分类: cs.LG
发布日期: 2025-10-30 (更新: 2025-11-30)
🔗 代码/项目: GITHUB
💡 一句话要点
探讨RLVR在数学推理中的局限性与改进方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 数学推理 组合问题 模型评估 深度学习 推理能力
📋 核心要点
- 现有的RLVR方法在促进真正的数学推理能力方面存在不足,往往依赖于表面启发式而非深层次的推理策略。
- 论文通过研究两个组合问题,提出了使用可验证奖励的强化学习方法,旨在提升模型的推理能力。
- 实验结果表明,RLVR在多个奖励设计下提高了评估指标,但未能有效促进新的推理策略的学习。
📝 摘要(中文)
数学推理是大型语言模型(LLMs)面临的核心挑战之一,要求不仅提供正确答案,还需展现可信的推理过程。强化学习与可验证奖励(RLVR)作为提升此能力的有前景的方法,其实际效果尚不明确。本文研究了RLVR在两个组合问题上的应用:活动调度和最长递增子序列,使用精心策划的数据集。研究发现,尽管RLVR在评估指标上有所提升,但往往是通过强化表面启发式,而非真正获取新的推理策略。这些结果突显了RLVR泛化的局限性,强调了需要更好的基准来区分真正的数学推理与捷径利用,并提供真实的进展衡量。
🔬 方法详解
问题定义:本文旨在探讨RLVR在数学推理中的应用,尤其是其在活动调度和最长递增子序列问题上的表现。现有方法往往未能有效促进深层次的推理能力,导致模型依赖于表面启发式。
核心思路:论文提出通过设计可验证的奖励机制来增强模型的推理能力,期望模型能够在解决组合问题时不仅给出正确答案,还能展现出合理的推理过程。
技术框架:研究采用了RLVR框架,包含数据集构建、奖励设计、模型训练和评估四个主要模块。数据集使用了具有唯一最优解的组合问题,以确保模型的学习过程可验证。
关键创新:论文的主要创新在于通过可验证奖励的设计来提升模型的推理能力,强调了在评估模型时需要关注其推理过程而非仅仅是结果。与现有方法相比,RLVR在一定程度上能够改善模型的表现,但仍存在局限性。
关键设计:在实验中,设计了多种奖励机制,并对模型的训练过程进行了细致的参数调优。损失函数的选择和网络结构的设计均考虑了推理过程的可验证性,以确保模型不仅能给出正确答案,还能提供合理的推理路径。
🖼️ 关键图片
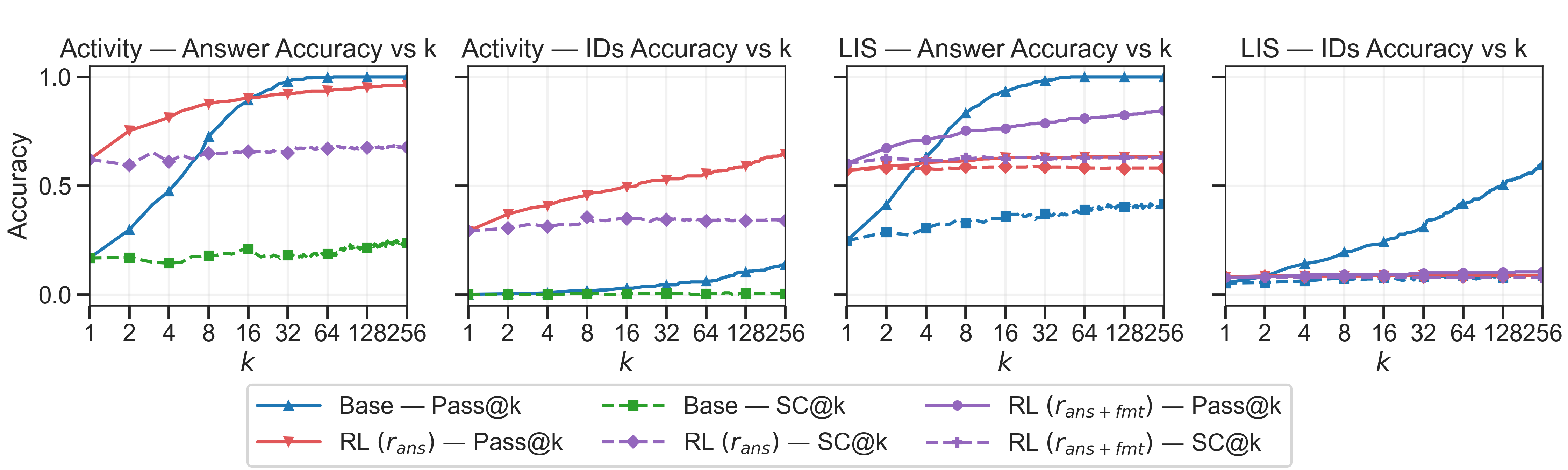


📊 实验亮点
实验结果显示,RLVR在活动调度和最长递增子序列问题上,评估指标有明显提升,尤其是在多个奖励设计下,尽管提升幅度存在局限,模型仍然未能有效学习到新的推理策略,强调了RLVR泛化的局限性。
🎯 应用场景
该研究的潜在应用领域包括教育、自动化决策系统和智能助手等,能够帮助这些系统在处理复杂的数学推理任务时,提供更为可靠的推理过程和结果。未来,该研究可能推动RLVR方法在更广泛的领域中的应用,提升AI系统的智能水平。
📄 摘要(原文)
Mathematical reasoning is a central challenge for large language models (LLMs), requiring not only correct answers but also faithful reasoning processes. Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising approach for enhancing such capabilities; however, its ability to foster genuine reasoning remains unclear. We investigate RLVR on two combinatorial problems with fully verifiable solutions: \emph{Activity Scheduling} and the \emph{Longest Increasing Subsequence}, using carefully curated datasets with unique optima. Across multiple reward designs, we find that RLVR improves evaluation metrics but often by reinforcing superficial heuristics rather than acquiring new reasoning strategies. These findings highlight the limits of RLVR generalization, emphasizing the importance of benchmarks that disentangle genuine mathematical reasoning from shortcut exploitation and provide faithful measures of progress. Code available at https://github.com/xashru/rlvr-seq-generalization.