Jasmine: A Simple, Performant and Scalable JAX-based World Modeling Codebase
作者: Mihir Mahajan, Alfred Nguyen, Franz Srambical, Stefan Bauer
分类: cs.LG, cs.AI
发布日期: 2025-10-30
备注: Blog post: https://pdoom.org/jasmine.html
💡 一句话要点
Jasmine:一个简单、高性能且可扩展的基于JAX的世界模型代码库
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 JAX 高性能计算 可扩展性 可复现性
📋 核心要点
- 世界模型是解决机器人等领域数据稀缺的关键,但缺乏易用且高性能的训练基础设施。
- Jasmine提供了一个基于JAX的高性能世界模型代码库,支持大规模并行训练和可复现性。
- 实验表明,Jasmine在CoinRun案例中实现了数量级的性能提升,并为模型基准测试提供了基础。
📝 摘要(中文)
世界模型正日益成为克服机器人等领域数据稀缺问题的有效途径,但世界模型的开放训练基础设施仍处于起步阶段。本文介绍了Jasmine,一个高性能的基于JAX的世界模型代码库,它可以通过最少的代码更改,从单主机扩展到数百个加速器。通过对数据加载、训练和检查点等环节的性能优化,Jasmine在CoinRun案例研究中的复现速度比之前的开源实现快一个数量级。该代码库保证了完全可复现的训练,并支持各种分片配置。通过将Jasmine与精心策划的大规模数据集相结合,我们为跨模型家族和架构消融研究的严格基准测试流程建立了基础设施。
🔬 方法详解
问题定义:现有世界模型训练基础设施不足,难以支持大规模、高性能和可复现的实验。开源实现性能较低,限制了研究人员探索复杂模型和大规模数据集的能力。
核心思路:Jasmine的核心思路是利用JAX框架的优势,通过优化数据加载、训练和检查点等关键环节,实现高性能和可扩展性。同时,注重代码的可复现性,为研究人员提供可靠的实验平台。
技术框架:Jasmine的整体框架包括数据加载模块、模型定义模块、训练循环模块和检查点管理模块。数据加载模块负责高效地将数据加载到加速器上。模型定义模块支持各种世界模型架构。训练循环模块使用JAX进行自动微分和优化。检查点管理模块负责保存和加载模型参数。
关键创新:Jasmine的关键创新在于其对性能的极致优化,包括:1) 使用JAX的pmap和pjit实现数据并行和模型并行;2) 优化数据加载流程,减少CPU到GPU的数据传输;3) 使用高效的检查点机制,加速模型保存和加载。
关键设计:Jasmine支持多种分片配置,允许用户根据硬件资源和模型大小灵活地分配计算任务。损失函数可以根据具体任务进行定制。网络结构可以根据需要进行修改。此外,Jasmine还提供了丰富的工具,用于监控训练过程和分析模型性能。
🖼️ 关键图片

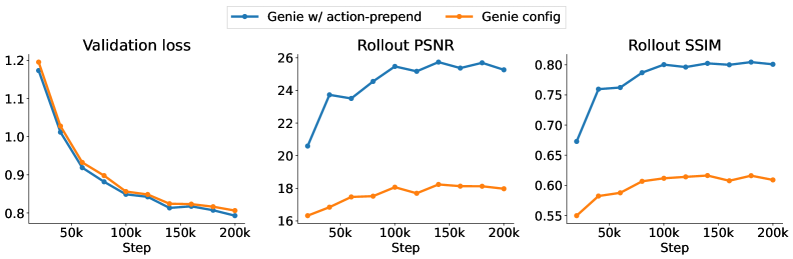

📊 实验亮点
Jasmine在CoinRun案例研究中实现了数量级的性能提升,证明了其高性能和可扩展性。与之前的开源实现相比,Jasmine的训练速度更快,资源利用率更高。此外,Jasmine还保证了完全可复现的训练,为研究人员提供了一个可靠的实验平台。
🎯 应用场景
Jasmine可应用于机器人、游戏AI、自动驾驶等领域,通过世界模型学习环境的动态特性,从而提升智能体的决策能力和泛化性能。该代码库为研究人员提供了一个高效的实验平台,加速世界模型相关算法的开发和验证,并促进相关技术的落地应用。
📄 摘要(原文)
While world models are increasingly positioned as a pathway to overcoming data scarcity in domains such as robotics, open training infrastructure for world modeling remains nascent. We introduce Jasmine, a performant JAX-based world modeling codebase that scales from single hosts to hundreds of accelerators with minimal code changes. Jasmine achieves an order-of-magnitude faster reproduction of the CoinRun case study compared to prior open implementations, enabled by performance optimizations across data loading, training and checkpointing. The codebase guarantees fully reproducible training and supports diverse sharding configurations. By pairing Jasmine with curated large-scale datasets, we establish infrastructure for rigorous benchmarking pipelines across model families and architectural ablations.