Pre-trained Forecasting Models: Strong Zero-Shot Feature Extractors for Time Series Classification
作者: Andreas Auer, Daniel Klotz, Sebastinan Böck, Sepp Hochreiter
分类: cs.LG
发布日期: 2025-10-30
备注: NeurIPS 2025 Workshop on Recent Advances in Time Series Foundation Models (BERT2S)
💡 一句话要点
预训练预测模型作为时间序列分类的强大零样本特征提取器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分类 预训练模型 特征提取 零样本学习 预测模型
📋 核心要点
- 时间序列基础模型的研究主要集中在预测任务,缺乏对其学习表征泛化能力的深入研究,阻碍了其在其他任务上的应用。
- 该论文探索了利用预训练的预测模型作为特征提取器,直接应用于时间序列分类任务,无需针对分类任务进行专门的预训练。
- 实验结果表明,优秀的预测模型在时间序列分类任务上可以达到甚至超过专门为分类任务预训练的模型的性能,并验证了预测性能与分类性能的正相关性。
📝 摘要(中文)
最近关于时间序列基础模型的研究主要集中在预测方面,其学习到的表征的泛化能力尚不清楚。本研究探讨了冻结的预训练预测模型是否能为分类提供有效的表征。为此,我们比较了不同的表征提取策略,并引入了两种模型无关的嵌入增强方法。实验表明,最佳预测模型实现了与专门为分类预训练的最先进模型相匹配甚至超越的分类精度。此外,我们观察到预测性能和分类性能之间存在正相关关系。这些发现挑战了任务特定预训练是必要的这一假设,并表明学习预测可能为构建通用时间序列基础模型提供了一条有效的途径。
🔬 方法详解
问题定义:论文旨在解决时间序列分类任务中,依赖任务特定预训练模型的问题。现有方法通常需要针对分类任务进行专门的预训练,这增加了计算成本和模型开发的复杂性。论文希望探索是否可以通过预训练的预测模型,直接提取时间序列的有效特征,用于分类任务,从而避免任务特定的预训练过程。
核心思路:论文的核心思路是利用预训练的预测模型学习到的时间序列表征,将其作为通用的特征提取器,直接应用于时间序列分类任务。通过冻结预训练模型的参数,避免在分类任务中进行微调,从而实现零样本的特征提取和分类。论文假设,良好的时间序列预测能力能够反映模型对时间序列内在结构的理解,从而可以提取出适用于分类任务的有效特征。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择预训练的预测模型,例如Transformer、N-BEATS等;2) 冻结预训练模型的参数;3) 使用不同的表征提取策略,从预训练模型中提取时间序列的特征向量;4) 使用提取的特征向量训练分类器,例如线性分类器或支持向量机;5) 评估分类器的性能。论文还提出了两种模型无关的嵌入增强方法,用于进一步提升特征的表达能力。
关键创新:论文的关键创新在于:1) 验证了预训练的预测模型可以作为时间序列分类的有效特征提取器,挑战了任务特定预训练的必要性;2) 提出了两种模型无关的嵌入增强方法,进一步提升了特征的表达能力;3) 观察到预测性能和分类性能之间存在正相关关系,为时间序列基础模型的研究提供了新的思路。
关键设计:论文的关键设计包括:1) 选择了多种不同的预训练预测模型,以验证方法的通用性;2) 采用了不同的表征提取策略,例如使用编码器的最后一层输出、使用注意力机制的加权平均等;3) 提出了两种模型无关的嵌入增强方法,包括时间域和频率域的增强;4) 使用了多种时间序列分类数据集,以评估方法的性能。
🖼️ 关键图片
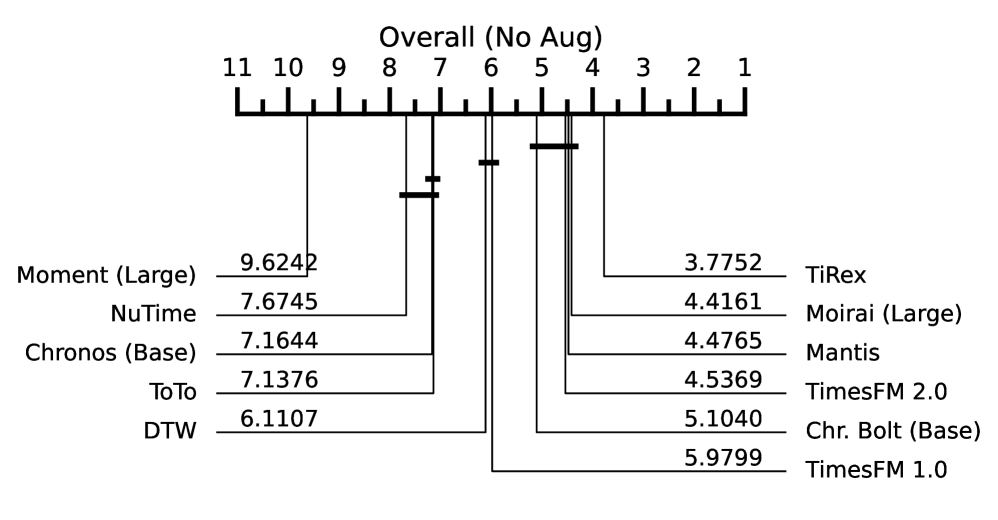
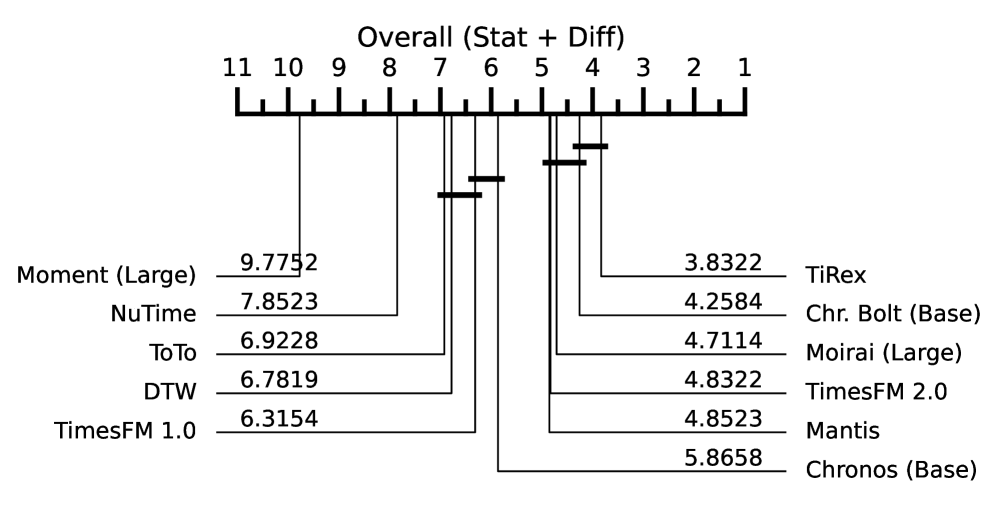
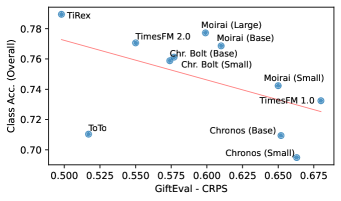
📊 实验亮点
实验结果表明,最佳的预训练预测模型在时间序列分类任务上取得了与专门为分类任务预训练的最先进模型相匹配甚至超越的性能。例如,在某些数据集上,使用预训练的Transformer模型作为特征提取器,可以达到超过90%的分类准确率,并且显著优于传统的基于手工特征的方法。此外,实验还验证了预测性能和分类性能之间存在正相关关系。
🎯 应用场景
该研究成果可应用于各种时间序列分类场景,例如:医疗健康领域的疾病诊断、金融领域的欺诈检测、工业领域的设备故障预测等。通过利用预训练的预测模型,可以降低模型开发的成本和时间,提高分类的准确率和泛化能力。未来,该研究可以进一步扩展到其他时间序列分析任务,例如异常检测、聚类等,为构建通用的时间序列基础模型奠定基础。
📄 摘要(原文)
Recent research on time series foundation models has primarily focused on forecasting, leaving it unclear how generalizable their learned representations are. In this study, we examine whether frozen pre-trained forecasting models can provide effective representations for classification. To this end, we compare different representation extraction strategies and introduce two model-agnostic embedding augmentations. Our experiments show that the best forecasting models achieve classification accuracy that matches or even surpasses that of state-of-the-art models pre-trained specifically for classification. Moreover, we observe a positive correlation between forecasting and classification performance. These findings challenge the assumption that task-specific pre-training is necessary, and suggest that learning to forecast may provide a powerful route toward constructing general-purpose time series foundation models.