LSM-MS2: A Foundation Model Bridging Spectral Identification and Biological Interpretation
作者: Gabriel Asher, Devesh Shah, Amy A. Caudy, Luke Ferro, Lea Amar, Ana S. H. Costa, Thomas Patton, Niall O'Connor, Jennifer M. Campbell, Jack Geremia
分类: cs.LG
发布日期: 2025-10-30
💡 一句话要点
LSM-MS2:用于桥接谱图识别与生物学解释的深度学习基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 质谱分析 谱图识别 深度学习 基础模型 化学语义空间
📋 核心要点
- 质谱数据的生物和化学信息未被充分挖掘,现有方法在谱图识别方面存在不足。
- LSM-MS2通过在大规模质谱数据上训练深度学习模型,学习化学语义空间,从而实现谱图识别和生物学解释。
- LSM-MS2在谱图识别准确率上显著提升,尤其是在异构化合物和复杂生物样品中,同时保持了低浓度下的鲁棒性。
📝 摘要(中文)
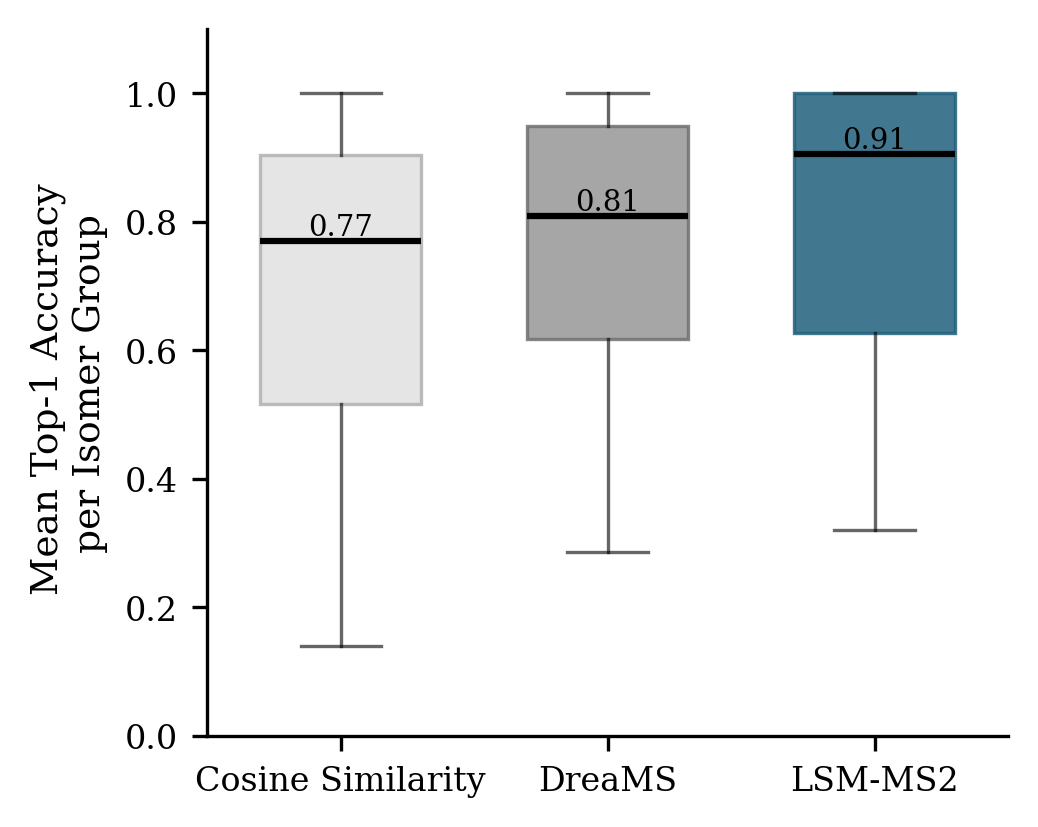
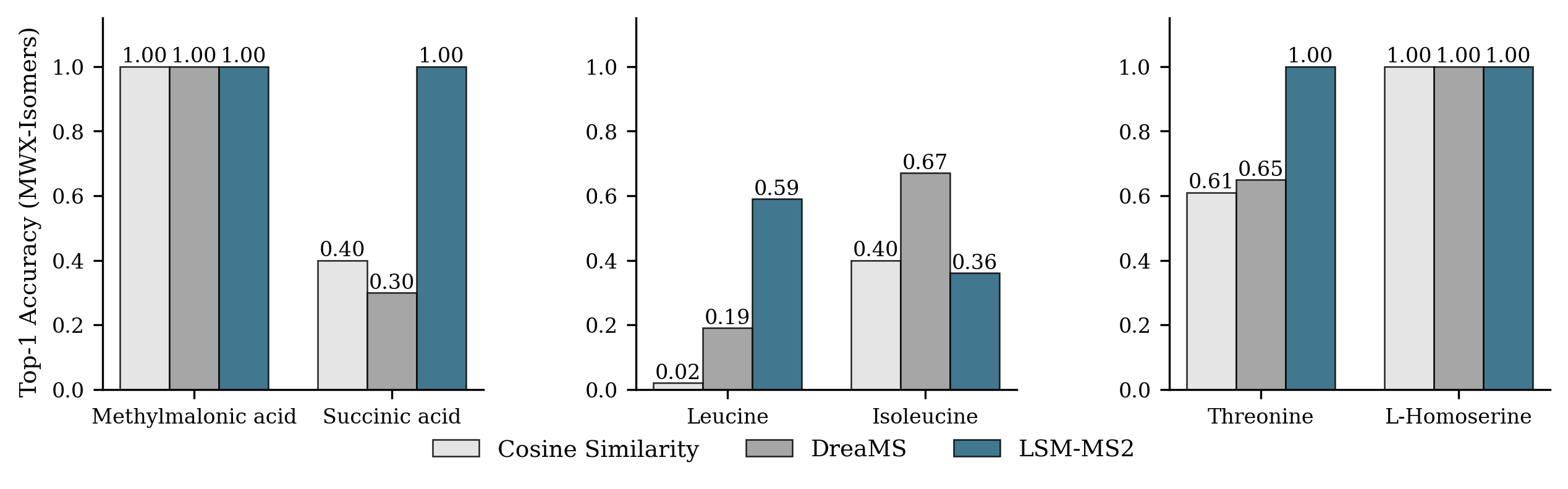
本文提出了LSM-MS2,一个大规模深度学习基础模型,它在数百万张质谱图上进行训练,以学习化学语义空间。LSM-MS2在谱图识别方面达到了最先进的性能,在识别具有挑战性的异构化合物的准确率方面比现有方法提高了30%,在复杂生物样品中正确识别的数量提高了42%,并在低浓度条件下保持了鲁棒性。此外,LSM-MS2生成丰富的谱图嵌入,能够从最少的下游数据中直接进行生物学解释,成功区分疾病状态并预测各种转化应用中的临床结果。
🔬 方法详解
问题定义:质谱数据蕴含丰富的生物和化学信息,但现有方法在谱图识别方面存在局限性,尤其是在处理异构化合物和复杂生物样品时,准确率较低,难以充分挖掘数据价值。此外,现有方法难以直接从谱图数据中进行生物学解释,需要额外的实验和分析。
核心思路:LSM-MS2的核心思路是利用大规模深度学习模型,通过在数百万张质谱图上进行训练,学习一个化学语义空间。该模型能够将谱图数据映射到高维嵌入空间,从而实现谱图识别和生物学解释。通过学习化学语义空间,LSM-MS2能够更好地理解谱图数据中的化学信息,提高谱图识别的准确率和鲁棒性。
技术框架:LSM-MS2的技术框架主要包括数据预处理、模型训练和下游应用三个阶段。在数据预处理阶段,对原始质谱数据进行清洗、校正和标准化处理。在模型训练阶段,使用大规模质谱数据集训练深度学习模型,学习化学语义空间。在下游应用阶段,利用训练好的模型进行谱图识别、生物学解释和临床预测等任务。整体流程是从原始数据到模型训练,再到实际应用。
关键创新:LSM-MS2的关键创新在于其大规模深度学习模型和化学语义空间的学习。与现有方法相比,LSM-MS2能够更好地捕捉谱图数据中的复杂模式和化学信息,从而提高谱图识别的准确率和鲁棒性。此外,LSM-MS2生成的谱图嵌入能够直接用于生物学解释,无需额外的实验和分析。
关键设计:LSM-MS2的具体网络结构和损失函数等技术细节在论文中未详细说明,属于未知信息。但可以推测,可能采用了Transformer或图神经网络等先进的深度学习架构,并设计了合适的损失函数来优化模型的性能。具体的参数设置也未知。
🖼️ 关键图片

📊 实验亮点
LSM-MS2在谱图识别方面取得了显著的性能提升。在识别具有挑战性的异构化合物的准确率方面,LSM-MS2比现有方法提高了30%。在复杂生物样品中,LSM-MS2正确识别的数量提高了42%。此外,LSM-MS2在低浓度条件下保持了鲁棒性,表明其具有很强的实用价值。
🎯 应用场景
LSM-MS2具有广泛的应用前景,可用于代谢组学、蛋白质组学、药物发现、疾病诊断和环境监测等领域。通过提高谱图识别的准确率和效率,LSM-MS2能够加速生物标志物的发现和药物的研发。此外,LSM-MS2还能够直接从谱图数据中进行生物学解释,为临床诊断和个性化治疗提供新的思路。
📄 摘要(原文)
A vast majority of mass spectrometry data remains uncharacterized, leaving much of its biological and chemical information untapped. Recent advances in machine learning have begun to address this gap, particularly for tasks such as spectral identification in tandem mass spectrometry data. Here, we present the latest generation of LSM-MS2, a large-scale deep learning foundation model trained on millions of spectra to learn a semantic chemical space. LSM-MS2 achieves state-of-the-art performance in spectral identification, improving on existing methods by 30% in accuracy of identifying challenging isomeric compounds, yielding 42% more correct identifications in complex biological samples, and maintaining robustness under low-concentration conditions. Furthermore, LSM-MS2 produces rich spectral embeddings that enable direct biological interpretation from minimal downstream data, successfully differentiating disease states and predicting clinical outcomes across diverse translational applications.