Polybasic Speculative Decoding Through a Theoretical Perspective
作者: Ruilin Wang, Huixia Li, Yuexiao Ma, Xiawu Zheng, Fei Chao, Xuefeng Xiao, Rongrong Ji
分类: cs.LG
发布日期: 2025-10-30
💡 一句话要点
提出Polybasic推测解码框架,加速LLM推理并提供理论支撑。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大规模语言模型 推理加速 多模型协同 理论分析
📋 核心要点
- 现有推测解码方法依赖二元框架,缺乏对多模型协同的理论指导,限制了推理加速的潜力。
- 提出Polybasic推测解码框架,通过理论分析优化多模型token生成,实现更高效的推理。
- 实验表明,该方法在多个LLM上实现了显著的推理加速,同时保持了输出分布的质量。
📝 摘要(中文)
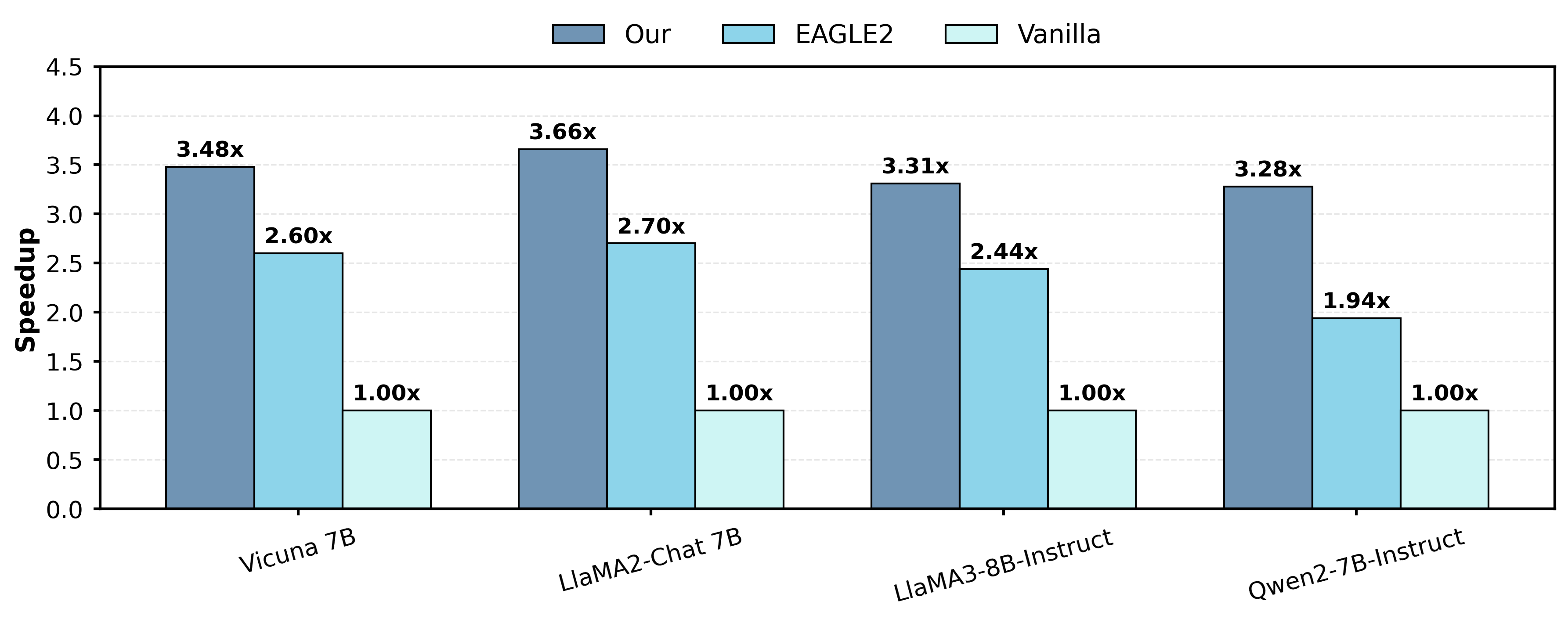
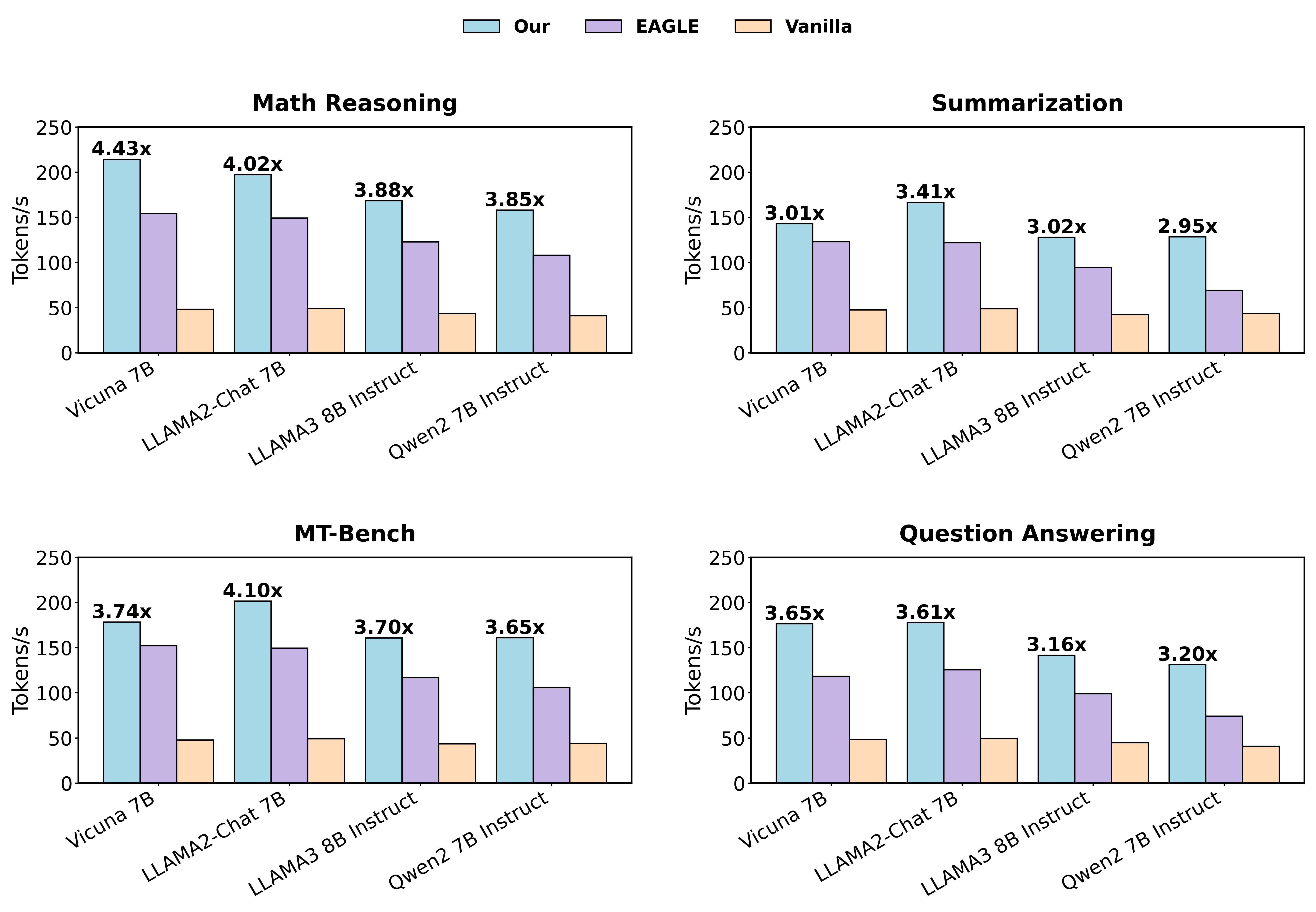
大规模语言模型(LLMs)的推理延迟是部署的关键瓶颈。推测解码方法最近在加速推理方面显示出潜力,且不影响输出分布。然而,现有工作通常依赖于二元草案-验证框架,缺乏严格的理论基础。本文提出了一种新的polybasic推测解码框架,并进行了全面的理论分析。具体来说,我们证明了一个基本定理,该定理描述了多模型推测解码系统的最佳推理时间,阐明了如何将方法扩展到二元方法之外,形成更通用的polybasic范式。通过对多模型token生成的理论研究,我们揭示并优化了模型能力、接受长度和总体计算成本之间的相互作用。我们的框架支持独立实现以及与现有推测技术的集成,从而在实践中加速性能。跨多个模型系列的实验结果表明,我们的方法对LLaMA2-Chat 7B的加速比为3.31倍至4.01倍,对LLaMA3-8B的加速比高达3.87倍,对Vicuna-7B的加速比高达4.43倍,对Qwen2-7B的加速比高达3.85倍——所有这些都保留了原始输出分布。我们发布了我们的理论证明和实现代码,以促进对polybasic推测解码的进一步研究。
🔬 方法详解
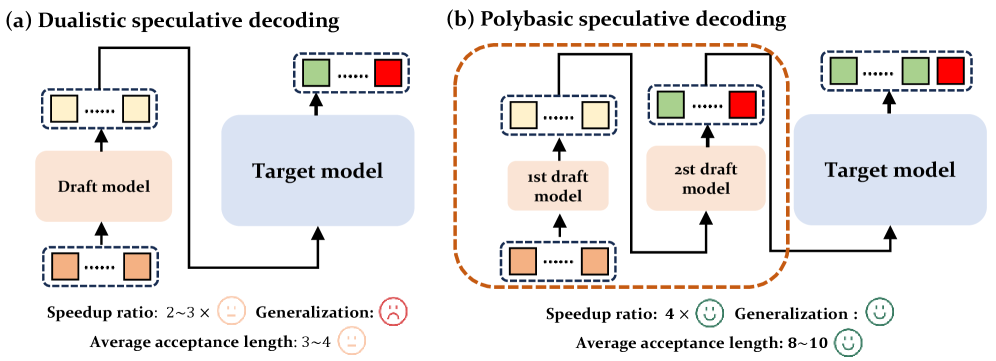
问题定义:论文旨在解决大规模语言模型(LLMs)推理速度慢的问题。现有的推测解码方法通常采用二元(dualistic)的draft-verify框架,即使用一个小模型生成草稿,然后用大模型验证。这种方法的局限性在于,它未能充分利用多个模型的潜力,并且缺乏对多模型协同工作方式的理论指导,导致推理效率提升有限。
核心思路:论文的核心思路是提出一种“polybasic”推测解码框架,该框架允许使用多个模型进行推测,而不仅仅是两个。通过对多模型token生成的理论分析,论文旨在优化模型能力、接受长度和总体计算成本之间的相互作用,从而实现更高效的推理。核心在于找到最佳的模型组合和推测策略,以最大化加速效果。
技术框架:该框架包含以下主要阶段:1. 多模型选择:根据模型的能力和计算成本,选择合适的多个模型参与推测。2. 草稿生成:使用选定的多个模型并行生成多个token序列作为草稿。3. 验证:使用主模型(通常是最大的模型)并行验证这些草稿。4. 接受与拒绝:根据验证结果,接受或拒绝草稿中的token。5. 迭代:重复上述过程,直到生成所需的token序列。
关键创新:最重要的技术创新点在于提出了polybasic推测解码的理论框架,并证明了一个基本定理,该定理描述了多模型推测解码系统的最佳推理时间。这为如何扩展到二元方法之外,形成更通用的polybasic范式提供了理论指导。与现有方法的本质区别在于,该方法不再局限于两个模型之间的交互,而是允许多个模型协同工作,从而更充分地利用了模型资源。
关键设计:论文的关键设计包括:1. 模型选择策略:如何根据模型的能力和计算成本选择合适的模型组合。2. 接受长度优化:如何优化接受长度,以平衡计算成本和加速效果。3. 并行验证策略:如何并行验证多个草稿,以提高验证效率。4. 损失函数:论文可能使用了某种损失函数来优化模型的推测能力,但具体细节未知。5. 网络结构:论文可能对模型的网络结构进行了一些调整,以适应多模型推测的需求,但具体细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个LLM上实现了显著的推理加速。对于LLaMA2-Chat 7B,加速比为3.31倍至4.01倍;对于LLaMA3-8B,加速比高达3.87倍;对于Vicuna-7B,加速比高达4.43倍;对于Qwen2-7B,加速比高达3.85倍。这些加速是在保持原始输出分布不变的前提下实现的,证明了该方法的有效性和可靠性。
🎯 应用场景
该研究成果可广泛应用于各种需要加速LLM推理的场景,例如在线对话系统、文本生成、机器翻译等。通过提高推理效率,可以降低部署成本,提升用户体验,并促进LLM在资源受限设备上的应用。未来,该方法有望与其他推理加速技术相结合,进一步提升LLM的实用性。
📄 摘要(原文)
Inference latency stands as a critical bottleneck in the large-scale deployment of Large Language Models (LLMs). Speculative decoding methods have recently shown promise in accelerating inference without compromising the output distribution. However, existing work typically relies on a dualistic draft-verify framework and lacks rigorous theoretical grounding. In this paper, we introduce a novel \emph{polybasic} speculative decoding framework, underpinned by a comprehensive theoretical analysis. Specifically, we prove a fundamental theorem that characterizes the optimal inference time for multi-model speculative decoding systems, shedding light on how to extend beyond the dualistic approach to a more general polybasic paradigm. Through our theoretical investigation of multi-model token generation, we expose and optimize the interplay between model capabilities, acceptance lengths, and overall computational cost. Our framework supports both standalone implementation and integration with existing speculative techniques, leading to accelerated performance in practice. Experimental results across multiple model families demonstrate that our approach yields speedup ratios ranging from $3.31\times$ to $4.01\times$ for LLaMA2-Chat 7B, up to $3.87 \times$ for LLaMA3-8B, up to $4.43 \times$ for Vicuna-7B and up to $3.85 \times$ for Qwen2-7B -- all while preserving the original output distribution. We release our theoretical proofs and implementation code to facilitate further investigation into polybasic speculative decoding.