LLMs as In-Context Meta-Learners for Model and Hyperparameter Selection
作者: Youssef Attia El Hili, Albert Thomas, Malik Tiomoko, Abdelhakim Benechehab, Corentin Léger, Corinne Ancourt, Balázs Kégl
分类: cs.LG, stat.ML
发布日期: 2025-10-30 (更新: 2025-11-06)
备注: 27 pages, 6 figures
💡 一句话要点
利用LLM作为上下文元学习器进行模型和超参数选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 元学习 模型选择 超参数优化 自动化机器学习
📋 核心要点
- 模型和超参数选择依赖专家经验或耗时搜索,缺乏高效自动化方法。
- 将数据集转化为元数据,利用LLM的上下文学习能力推荐模型和超参数。
- 实验表明,LLM无需搜索即可推荐具竞争力的模型和超参数,元学习能力显著。
📝 摘要(中文)
模型和超参数选择是机器学习中至关重要但具有挑战性的任务,通常需要专家经验或昂贵的自动化搜索。本文研究了大型语言模型(LLM)是否可以作为上下文元学习器来解决这个问题。通过将每个数据集转换为可解释的元数据,我们提示LLM推荐模型族和超参数。我们研究了两种提示策略:(1)仅依赖于预训练知识的零样本模式,以及(2)通过模型及其在过去任务中的表现示例增强的元信息模式。在合成和真实世界的基准测试中,我们表明LLM可以利用数据集元数据来推荐有竞争力的模型和超参数,而无需搜索,并且元信息提示的改进证明了它们进行上下文元学习的能力。这些结果突出了LLM作为一个轻量级、通用型助手在模型选择和超参数优化方面有前景的新角色。
🔬 方法详解
问题定义:论文旨在解决机器学习中模型和超参数选择的问题。现有方法,如网格搜索、随机搜索或贝叶斯优化,计算成本高昂,且依赖大量实验。专家经验虽然有效,但难以规模化应用。因此,如何高效、自动地进行模型和超参数选择是一个重要的挑战。
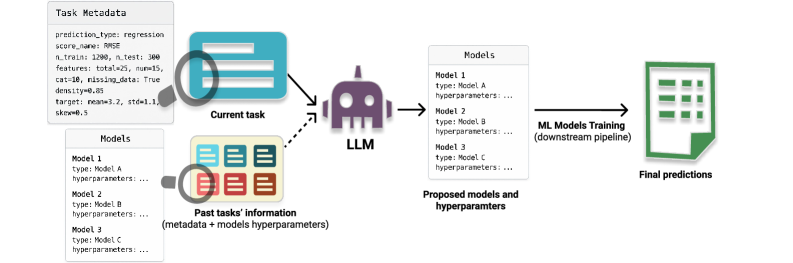
核心思路:论文的核心思路是将大型语言模型(LLM)作为上下文元学习器,利用其强大的知识储备和推理能力,根据数据集的元数据(如数据集大小、特征数量、特征类型等)直接推荐合适的模型和超参数。这种方法避免了传统的搜索过程,从而降低了计算成本。
技术框架:整体框架包含以下几个主要步骤:1) 数据集元数据提取:将数据集转化为可解释的元数据,例如数据集大小、特征数量、特征类型等。2) LLM提示:设计合适的提示语,将数据集元数据输入LLM。提示语可以分为两种模式:零样本模式(仅依赖LLM的预训练知识)和元信息模式(提供模型在过去任务中的表现示例)。3) 模型和超参数推荐:LLM根据提示语生成模型族和超参数的推荐。4) 评估:在目标数据集上评估推荐的模型和超参数的性能。
关键创新:论文的关键创新在于将LLM应用于模型和超参数选择任务,并将其视为上下文元学习器。与传统的元学习方法不同,该方法不需要显式的训练阶段,而是直接利用LLM的预训练知识和上下文学习能力。此外,论文还提出了两种不同的提示策略,并验证了元信息提示可以进一步提升LLM的性能。
关键设计:关键设计包括:1) 数据集元数据的表示方式:选择合适的元数据特征,例如数据集大小、特征数量、特征类型等,并将其转化为LLM可以理解的文本格式。2) 提示语的设计:设计清晰、简洁的提示语,引导LLM进行模型和超参数推荐。3) 元信息示例的选择:选择具有代表性的模型和数据集,构建元信息示例,帮助LLM更好地进行上下文学习。
🖼️ 关键图片
📊 实验亮点
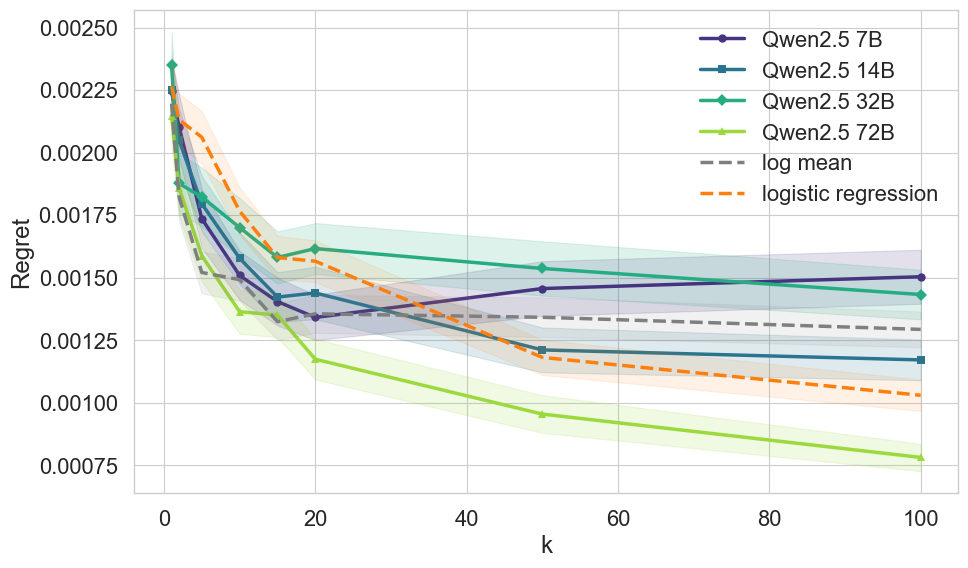
实验结果表明,LLM在合成和真实世界的数据集上均能推荐具有竞争力的模型和超参数,无需进行昂贵的搜索。元信息提示策略能够显著提升LLM的性能,证明了其上下文元学习的能力。例如,在某些数据集上,LLM推荐的模型性能接近甚至超过了经过精细调优的传统模型。
🎯 应用场景
该研究成果可应用于自动化机器学习(AutoML)领域,降低模型选择和超参数优化的成本,使机器学习模型更容易被非专家用户使用。未来,该方法可以扩展到更复杂的模型和数据集,并与其他AutoML技术相结合,构建更强大的自动化机器学习系统。
📄 摘要(原文)
Model and hyperparameter selection are critical but challenging in machine learning, typically requiring expert intuition or expensive automated search. We investigate whether large language models (LLMs) can act as in-context meta-learners for this task. By converting each dataset into interpretable metadata, we prompt an LLM to recommend both model families and hyperparameters. We study two prompting strategies: (1) a zero-shot mode relying solely on pretrained knowledge, and (2) a meta-informed mode augmented with examples of models and their performance on past tasks. Across synthetic and real-world benchmarks, we show that LLMs can exploit dataset metadata to recommend competitive models and hyperparameters without search, and that improvements from meta-informed prompting demonstrate their capacity for in-context meta-learning. These results highlight a promising new role for LLMs as lightweight, general-purpose assistants for model selection and hyperparameter optimization.